 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-view Masked Diffusion Transformers for Person Image Synthesis
Paper and Code
Feb 02, 2024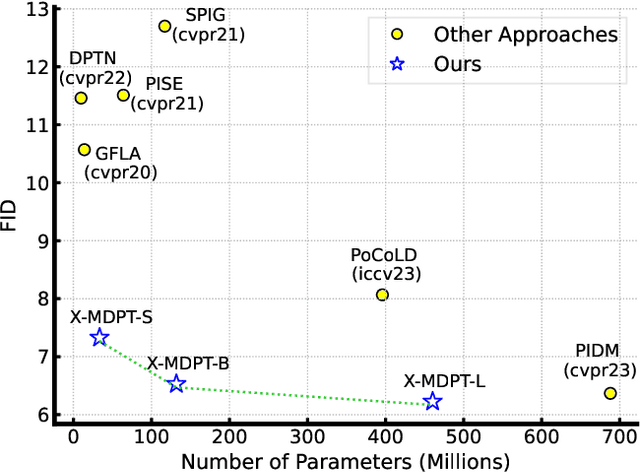


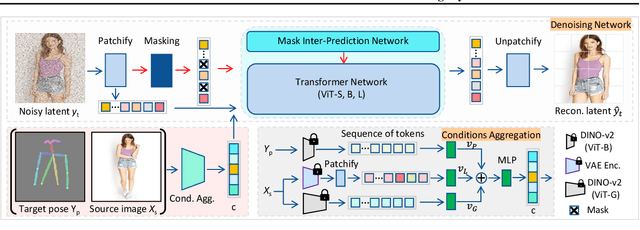
We present X-MDPT (Cross-view Masked Diffusion Prediction Transformers), a novel diffusion model designed for pose-guided human image generation. X-MDPT distinguishes itself by employing masked diffusion transformers that operate on latent patches, a departure from the commonly-used Unet structures in existing works. The model comprises three key modules: 1) a denoising diffusion Transformer, 2) an aggregation network that consolidates conditions into a single vector for the diffusion process, and 3) a mask cross-prediction module that enhances representation learning with semantic information from the reference image. X-MDPT demonstrates scalability, improving FID, SSIM, and LPIPS with larger models. Despite its simple design, our model outperforms state-of-the-art approaches on the DeepFashion dataset while exhibiting efficiency in terms of training parameters, training time, and inference speed. Our compact 33MB model achieves an FID of 7.42, surpassing a prior Unet latent diffusion approach (FID 8.07) using only $11\times$ fewer parameters. Our best model surpasses the pixel-based diffusion with $\frac{2}{3}$ of the parameters and achieves $5.43 \times$ faster inference.