 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCANet: Learning Connected Attentions for Convolutional Neural Networks
Paper and Code
Jul 09, 2020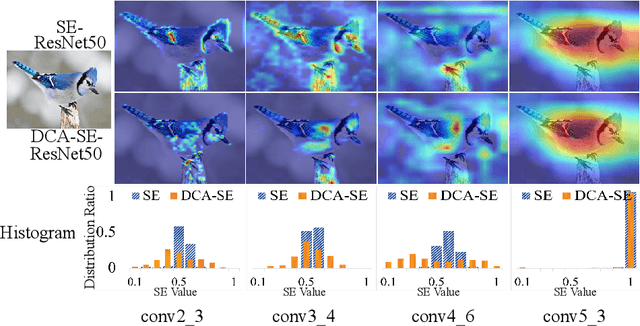

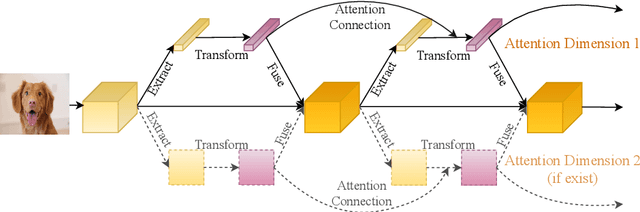

While self-attention mechanism has shown promising results for many vision tasks, it only considers the current features at a time. We show that such a manner cannot take full advantage of the attention mechanism. In this paper, we present Deep Connected Attention Network (DCANet), a novel design that boosts attention modules in a CNN model without any modification of the internal structure. To achieve this, we interconnect adjacent attention blocks, making information flow among attention blocks possible. With DCANet, all attention blocks in a CNN model are trained jointly, which improves the ability of attention learning. Our DCANet is generic. It is not limited to a specific attention module or base network architecture. Experimental results on ImageNet and MS COCO benchmarks show that DCANet consistently outperforms the state-of-the-art attention modules with a minimal additional computational overhead in all test cases. All code and models are made publicly available.