 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoFF: Cooperative Spatial Feature Fusion for 3D Object Detection on Autonomous Vehicles
Sep 24, 2020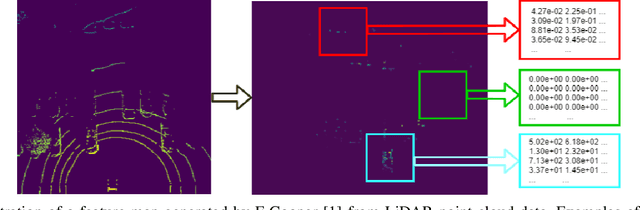

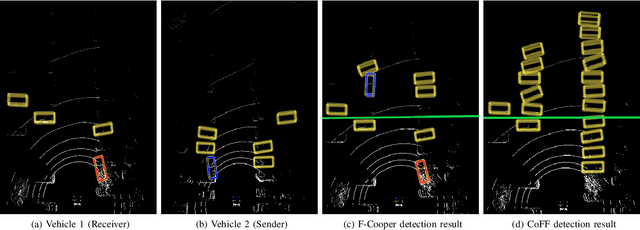
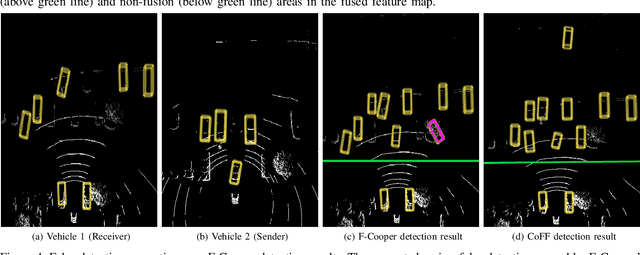
To reduce the amount of transmitted data, feature map based fusion is recently proposed as a practical solution to cooperative 3D object detection by autonomous vehicles. The precision of object detection, however, may require significant improvement, especially for objects that are far away or occluded. To address this critical issue for the safety of autonomous vehicles and human beings, we propose a cooperative spatial feature fusion (CoFF) method for autonomous vehicles to effectively fuse feature maps for achieving a higher 3D object detection performance. Specially, CoFF differentiates weights among feature maps for a more guided fusion, based on how much new semantic information is provided by the received feature maps. It also enhances the inconspicuous features corresponding to far/occluded objects to improve their detection precision. Experimental results show that CoFF achieves a significant improvement in terms of both detection precision and effective detection range for autonomous vehicles, compared to previous feature fusion solutions.
DCANet: Learning Connected Attentions for Convolutional Neural Networks
Jul 09, 2020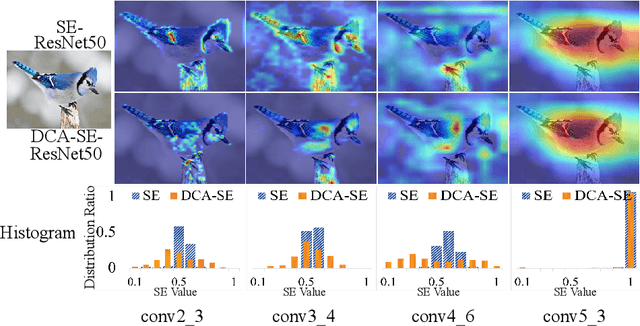

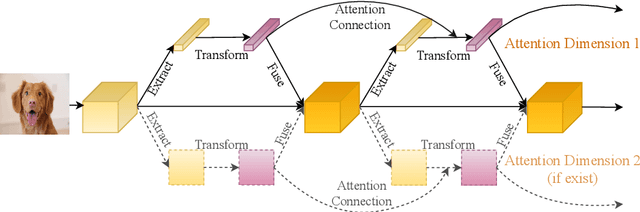

While self-attention mechanism has shown promising results for many vision tasks, it only considers the current features at a time. We show that such a manner cannot take full advantage of the attention mechanism. In this paper, we present Deep Connected Attention Network (DCANet), a novel design that boosts attention modules in a CNN model without any modification of the internal structure. To achieve this, we interconnect adjacent attention blocks, making information flow among attention blocks possible. With DCANet, all attention blocks in a CNN model are trained jointly, which improves the ability of attention learning. Our DCANet is generic. It is not limited to a specific attention module or base network architecture. Experimental results on ImageNet and MS COCO benchmarks show that DCANet consistently outperforms the state-of-the-art attention modules with a minimal additional computational overhead in all test cases. All code and models are made publicly available.
Cooper: Cooperative Perception for Connected Autonomous Vehicles based on 3D Point Clouds
May 13, 2019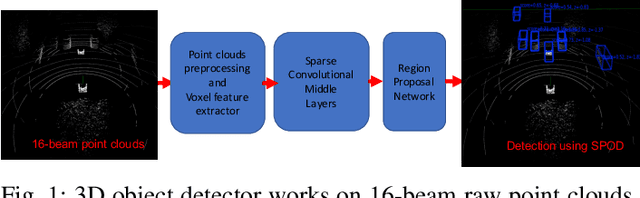
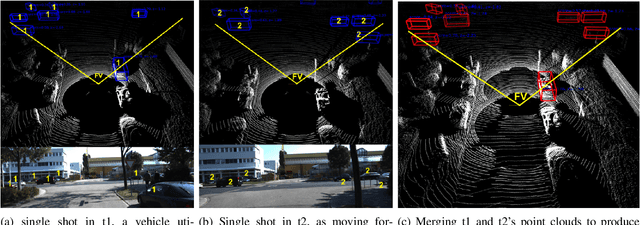
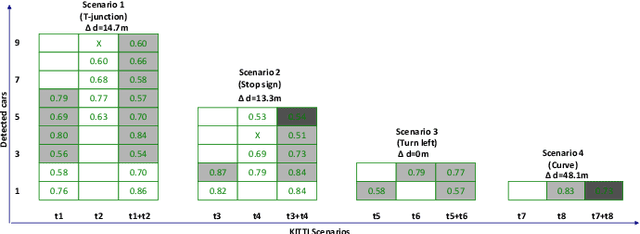
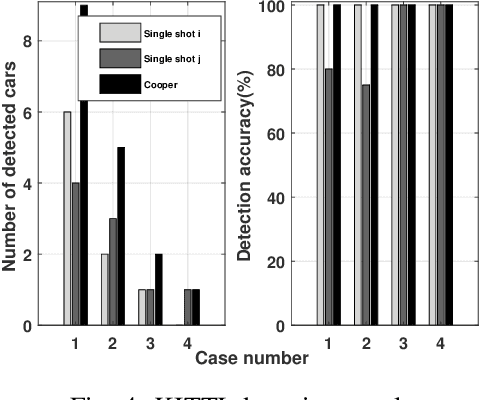
Autonomous vehicles may make wrong decisions due to inaccurate detection and recognition. Therefore, an intelligent vehicle can combine its own data with that of other vehicles to enhance perceptive ability, and thus improve detection accuracy and driving safety. However, multi-vehicle cooperative perception requires the integration of real world scenes and the traffic of raw sensor data exchange far exceeds the bandwidth of existing vehicular networks. To the best our knowledge, we are the first to conduct a study on raw-data level cooperative perception for enhancing the detection ability of self-driving systems. In this work, relying on LiDAR 3D point clouds, we fuse the sensor data collected from different positions and angles of connected vehicles. A point cloud based 3D object detection method is proposed to work on a diversity of aligned point clouds. Experimental results on KITTI and our collected dataset show that the proposed system outperforms perception by extending sensing area, improving detection accuracy and promoting augmented results. Most importantly, we demonstrate it is possible to transmit point clouds data for cooperative perception via existing vehicular network technologies.