 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Motion Planning for autonomous vehicles in dynamic environments
Jun 05, 2024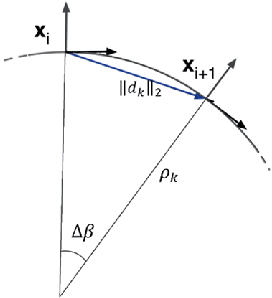
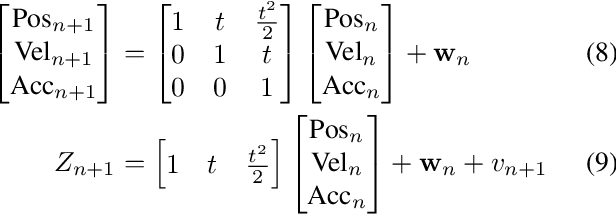
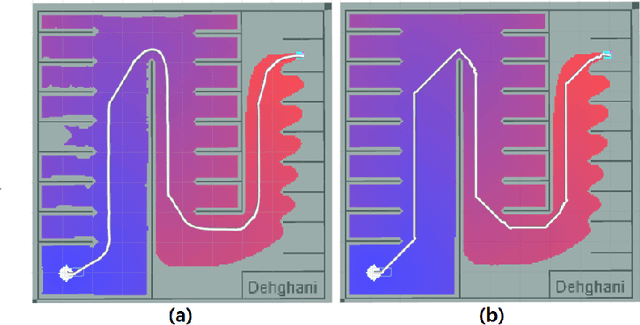
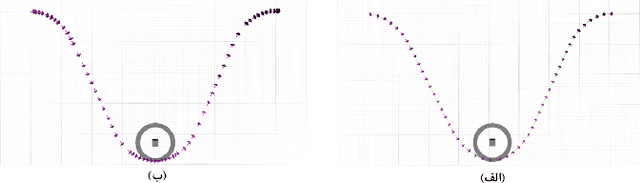
Recent advancements in self-driving car technologies have enabled them to navigate autonomously through various environments. However, one of the critical challenges in autonomous vehicle operation is trajectory planning, especially in dynamic environments with moving obstacles. This research aims to tackle this challenge by proposing a robust algorithm tailored for autonomous cars operating in dynamic environments with moving obstacles. The algorithm introduces two main innovations. Firstly, it defines path density by adjusting the number of waypoints along the trajectory, optimizing their distribution for accuracy in curved areas and reducing computational complexity in straight sections. Secondly, it integrates hierarchical motion planning algorithms, combining global planning with an enhanced $A^*$ graph-based method and local planning using the time elastic band algorithm with moving obstacle detection considering different motion models. The proposed algorithm is adaptable for different vehicle types and mobile robots, making it versatile for real-world applications. Simulation results demonstrate its effectiveness across various conditions, promising safer and more efficient navigation for autonomous vehicles in dynamic environments. These modifications significantly improve trajectory planning capabilities, addressing a crucial aspect of autonomous vehicle technology.
VirtualPainting: Addressing Sparsity with Virtual Points and Distance-Aware Data Augmentation for 3D Object Detection
Dec 26, 2023In recent times, there has been a notable surge in multimodal approaches that decorates raw LiDAR point clouds with camera-derived features to improve object detection performance. However, we found that these methods still grapple with the inherent sparsity of LiDAR point cloud data, primarily because fewer points are enriched with camera-derived features for sparsely distributed objects. We present an innovative approach that involves the generation of virtual LiDAR points using camera images and enhancing these virtual points with semantic labels obtained from image-based segmentation networks to tackle this issue and facilitate the detection of sparsely distributed objects, particularly those that are occluded or distant. Furthermore, we integrate a distance aware data augmentation (DADA) technique to enhance the models capability to recognize these sparsely distributed objects by generating specialized training samples. Our approach offers a versatile solution that can be seamlessly integrated into various 3D frameworks and 2D semantic segmentation methods, resulting in significantly improved overall detection accuracy. Evaluation on the KITTI and nuScenes datasets demonstrates substantial enhancements in both 3D and birds eye view (BEV) detection benchmarks
Facial Emotion Recognition using CNN in PyTorch
Dec 17, 2023In this project, we have implemented a model to recognize real-time facial emotions given the camera images. Current approaches would read all data and input it into their model, which has high space complexity. Our model is based on the Convolutional Neural Network utilizing the PyTorch library. We believe our implementation will significantly improve the space complexity and provide a useful contribution to facial emotion recognition. Our motivation is to understanding clearly about deep learning, particularly in CNNs, and analysis real-life scenarios. Therefore, we tunned the hyper parameter of model such as learning rate, batch size, and number of epochs to meet our needs. In addition, we also used techniques to optimize the networks, such as activation function, dropout and max pooling. Finally, we analyzed the result from two optimizer to observe the relationship between number of epochs and accuracy.