 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Evolving Role of Large Language Models in Scientific Innovation: Evaluator, Collaborator, and Scientist
Jul 16, 2025Scientific innovation is undergoing a paradigm shift driven by the rapid advancement of Large Language Models (LLMs). As science faces mounting challenges including information overload, disciplinary silos, and diminishing returns on conventional research methods, LLMs are emerging as powerful agents capable not only of enhancing scientific workflows but also of participating in and potentially leading the innovation process. Existing surveys mainly focus on different perspectives, phrases, and tasks in scientific research and discovery, while they have limitations in understanding the transformative potential and role differentiation of LLM. This survey proposes a comprehensive framework to categorize the evolving roles of LLMs in scientific innovation across three hierarchical levels: Evaluator, Collaborator, and Scientist. We distinguish between LLMs' contributions to structured scientific research processes and open-ended scientific discovery, thereby offering a unified taxonomy that clarifies capability boundaries, evaluation criteria, and human-AI interaction patterns at each level. Through an extensive analysis of current methodologies, benchmarks, systems, and evaluation metrics, this survey delivers an in-depth and systematic synthesis on LLM-driven scientific innovation. We present LLMs not only as tools for automating existing processes, but also as catalysts capable of reshaping the epistemological foundations of science itself. This survey offers conceptual clarity, practical guidance, and theoretical foundations for future research, while also highlighting open challenges and ethical considerations in the pursuit of increasingly autonomous AI-driven science. Resources related to this survey can be accessed on GitHub at: https://github.com/haoxuan-unt2024/llm4innovation.
DP-GTR: Differentially Private Prompt Protection via Group Text Rewriting
Mar 06, 2025



Prompt privacy is crucial, especially when using online large language models (LLMs), due to the sensitive information often contained within prompts. While LLMs can enhance prompt privacy through text rewriting, existing methods primarily focus on document-level rewriting, neglecting the rich, multi-granular representations of text. This limitation restricts LLM utilization to specific tasks, overlooking their generalization and in-context learning capabilities, thus hindering practical application. To address this gap, we introduce DP-GTR, a novel three-stage framework that leverages local differential privacy (DP) and the composition theorem via group text rewriting. DP-GTR is the first framework to integrate both document-level and word-level information while exploiting in-context learning to simultaneously improve privacy and utility, effectively bridging local and global DP mechanisms at the individual data point level. Experiments on CommonSense QA and DocVQA demonstrate that DP-GTR outperforms existing approaches, achieving a superior privacy-utility trade-off. Furthermore, our framework is compatible with existing rewriting techniques, serving as a plug-in to enhance privacy protection. Our code is publicly available at https://github.com/FatShion-FTD/DP-GTR for reproducibility.
GSOT3D: Towards Generic 3D Single Object Tracking in the Wild
Dec 03, 2024In this paper, we present a novel benchmark, GSOT3D, that aims at facilitating development of generic 3D single object tracking (SOT) in the wild. Specifically, GSOT3D offers 620 sequences with 123K frames, and covers a wide selection of 54 object categories. Each sequence is offered with multiple modalities, including the point cloud (PC), RGB image, and depth. This allows GSOT3D to support various 3D tracking tasks, such as single-modal 3D SOT on PC and multi-modal 3D SOT on RGB-PC or RGB-D, and thus greatly broadens research directions for 3D object tracking. To provide highquality per-frame 3D annotations, all sequences are labeled manually with multiple rounds of meticulous inspection and refinement. To our best knowledge, GSOT3D is the largest benchmark dedicated to various generic 3D object tracking tasks. To understand how existing 3D trackers perform and to provide comparisons for future research on GSOT3D, we assess eight representative point cloud-based tracking models. Our evaluation results exhibit that these models heavily degrade on GSOT3D, and more efforts are required for robust and generic 3D object tracking. Besides, to encourage future research, we present a simple yet effective generic 3D tracker, named PROT3D, that localizes the target object via a progressive spatial-temporal network and outperforms all current solutions by a large margin. By releasing GSOT3D, we expect to advance further 3D tracking in future research and applications. Our benchmark and model as well as the evaluation results will be publicly released at our webpage https://github.com/ailovejinx/GSOT3D.
A Comparative Study of Quality Evaluation Methods for Text Summarization
Jun 30, 2024
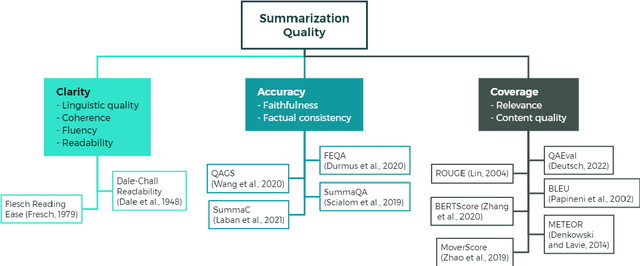


Evaluating text summarization has been a challenging task in natural language processing (NLP). Automatic metrics which heavily rely on reference summaries are not suitable in many situations, while human evaluation is time-consuming and labor-intensive. To bridge this gap, this paper proposes a novel method based on large language models (LLMs) for evaluating text summarization. We also conducts a comparative study on eight automatic metrics, human evaluation, and our proposed LLM-based method. Seven different types of state-of-the-art (SOTA) summarization models were evaluated. We perform extensive experiments and analysis on datasets with patent documents. Our results show that LLMs evaluation aligns closely with human evaluation, while widely-used automatic metrics such as ROUGE-2, BERTScore, and SummaC do not and also lack consistency. Based on the empirical comparison, we propose a LLM-powered framework for automatically evaluating and improving text summarization, which is beneficial and could attract wide attention among the community.
A Survey on Data Quality Dimensions and Tools for Machine Learning
Jun 28, 2024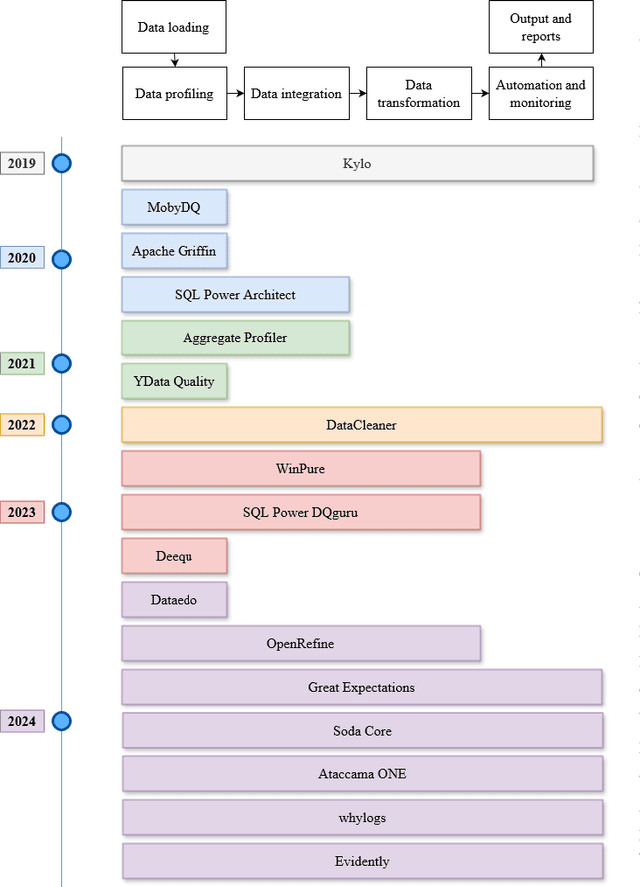

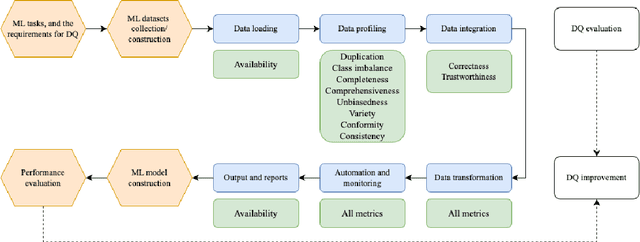
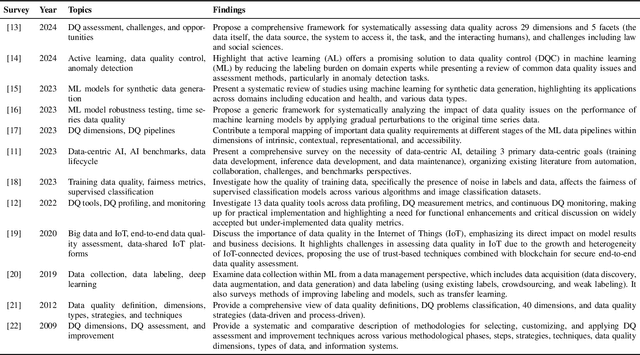
Machine learning (ML) technologies have become substantial in practically all aspects of our society, and data quality (DQ) is critical for the performance, fairness, robustness, safety, and scalability of ML models. With the large and complex data in data-centric AI, traditional methods like exploratory data analysis (EDA) and cross-validation (CV) face challenges, highlighting the importance of mastering DQ tools. In this survey, we review 17 DQ evaluation and improvement tools in the last 5 years. By introducing the DQ dimensions, metrics, and main functions embedded in these tools, we compare their strengths and limitations and propose a roadmap for developing open-source DQ tools for ML. Based on the discussions on the challenges and emerging trends, we further highlight the potential applications of large language models (LLMs) and generative AI in DQ evaluation and improvement for ML. We believe this comprehensive survey can enhance understanding of DQ in ML and could drive progress in data-centric AI. A complete list of the literature investigated in this survey is available on GitHub at: https://github.com/haihua0913/awesome-dq4ml.
Data Curation and Quality Assurance for Machine Learning-based Cyber Intrusion Detection
May 20, 2021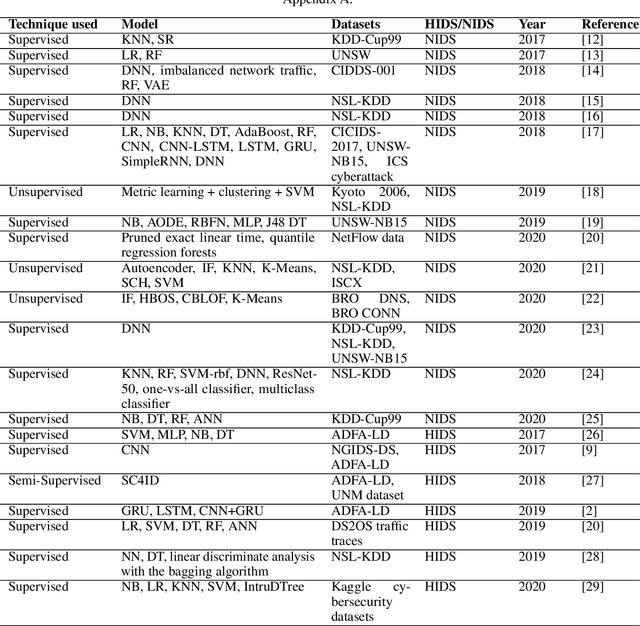
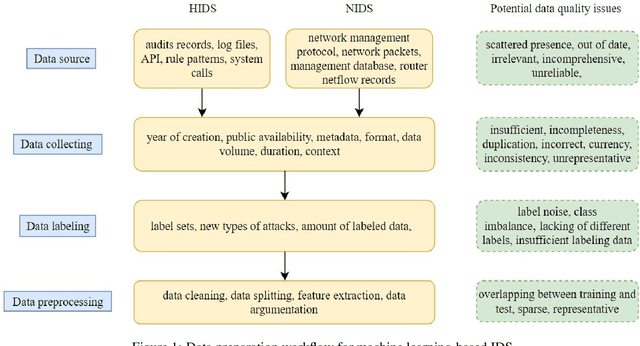
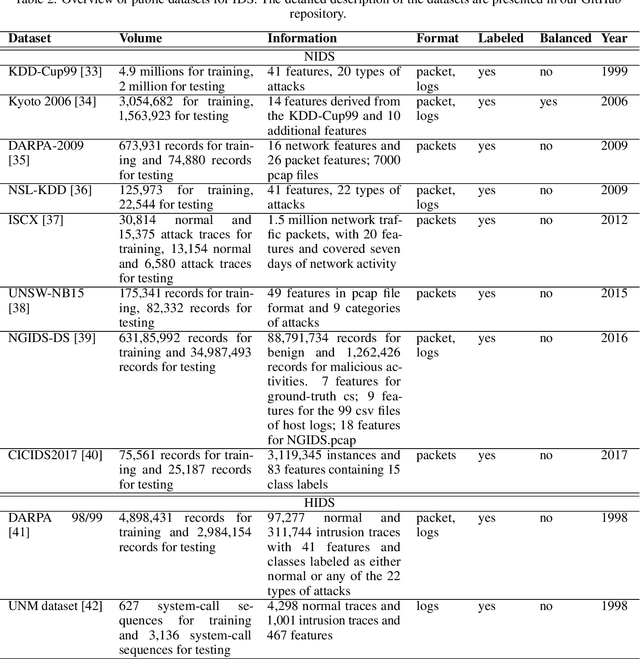
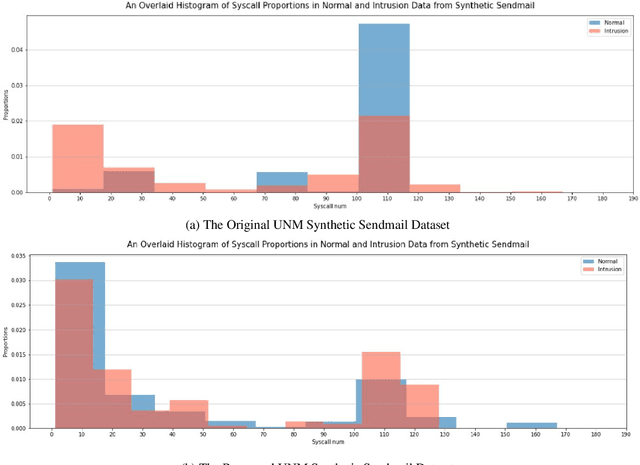
Intrusion detection is an essential task in the cyber threat environment. Machine learning and deep learning techniques have been applied for intrusion detection. However, most of the existing research focuses on the model work but ignores the fact that poor data quality has a direct impact on the performance of a machine learning system. More attention should be paid to the data work when building a machine learning-based intrusion detection system. This article first summarizes existing machine learning-based intrusion detection systems and the datasets used for building these systems. Then the data preparation workflow and quality requirements for intrusion detection are discussed. To figure out how data and models affect machine learning performance, we conducted experiments on 11 HIDS datasets using seven machine learning models and three deep learning models. The experimental results show that BERT and GPT were the best algorithms for HIDS on all of the datasets. However, the performance on different datasets varies, indicating the differences between the data quality of these datasets. We then evaluate the data quality of the 11 datasets based on quality dimensions proposed in this paper to determine the best characteristics that a HIDS dataset should possess in order to yield the best possible result. This research initiates a data quality perspective for researchers and practitioners to improve the performance of machine learning-based intrusion detection.