 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Graph Propagation with Hierarchical Information Transfer for Incomplete Contrastive Multi-view Clustering
Feb 26, 2025Incomplete multi-view clustering has become one of the important research problems due to the extensive missing multi-view data in the real world. Although the existing methods have made great progress, there are still some problems: 1) most methods cannot effectively mine the information hidden in the missing data; 2) most methods typically divide representation learning and clustering into two separate stages, but this may affect the clustering performance as the clustering results directly depend on the learned representation. To address these problems, we propose a novel incomplete multi-view clustering method with hierarchical information transfer. Firstly, we design the view-specific Graph Convolutional Networks (GCN) to obtain the representation encoding the graph structure, which is then fused into the consensus representation. Secondly, considering that one layer of GCN transfers one-order neighbor node information, the global graph propagation with the consensus representation is proposed to handle the missing data and learn deep representation. Finally, we design a weight-sharing pseudo-classifier with contrastive learning to obtain an end-to-end framework that combines view-specific representation learning, global graph propagation with hierarchical information transfer, and contrastive clustering for joint optimization. Extensive experiments conducted on several commonly-used datasets demonstrate the effectiveness and superiority of our method in comparison with other state-of-the-art approaches. The code is available at https://github.com/KelvinXuu/GHICMC.
Short-Term Temporal Convolutional Networks for Dynamic Hand Gesture Recognition
Dec 31, 2019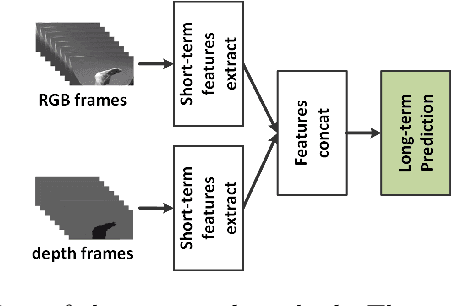



The purpose of gesture recognition is to recognize meaningful movements of human bodies, and gesture recognition is an important issue in computer vision. In this paper, we present a multimodal gesture recognition method based on 3D densely convolutional networks (3D-DenseNets) and improved temporal convolutional networks (TCNs). The key idea of our approach is to find a compact and effective representation of spatial and temporal features, which orderly and separately divide task of gesture video analysis into two parts: spatial analysis and temporal analysis. In spatial analysis, we adopt 3D-DenseNets to learn short-term spatio-temporal features effectively. Subsequently, in temporal analysis, we use TCNs to extract temporal features and employ improved Squeeze-and-Excitation Networks (SENets) to strengthen the representational power of temporal features from each TCNs' layers. The method has been evaluated on the VIVA and the NVIDIA Gesture Dynamic Hand Gesture Datasets. Our approach obtains very competitive performance on VIVA benchmarks with the classification accuracies of 91.54%, and achieve state-of-the art performance with 86.37% accuracy on NVIDIA benchmark.