 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Bias in Locally Constrained Decoding via Tractable Proposals
Jun 01, 2026Generations from large language models often fail to conform to desired constraints such as JSON schema. Existing locally constrained decoding (LCD) approaches enforce constraints by myopically masking out next tokens, resulting in biased sampling and degradation in performance. Recent work uses sequential Monte Carlo (SMC) methods to mitigate such biases, but designing effective proposal distributions or potential functions remains a key challenge. In this work, we propose a generic approach to construct proposals and potentials for SMC sampling from $p_{\mathrm{lm}}( \cdot \mid \mathrm{constraint})$. First, we show that constraints specified as finite automata can be tensorized for efficient execution on GPUs, which we use to construct globally constrained decoding (GCD) proposals. In addition, leveraging the fact that tensorized finite automata share the same circuit structure as hidden Markov models, we circuit-multiply them to obtain the probabilistic GCD (P-GCD) proposals encoding both logical and probabilistic information about the target distributions. We evaluate (P-)GCD on the tasks of function calling, keyword-based generation, and SQL generation. Experiments show that under the same SMC sampling setup, compared to LCD proposals, (P-)GCD converges faster to the target distribution with significantly fewer particles.
Skill Reuse as Compression in Agentic RL
May 29, 2026Large language model agents trained with reinforcement learning (RL) often learn brittle, task-specific shortcuts. We hypothesize that agents generalize better when their successful trajectories are structurally compressible, decomposed into a small set of reusable abstract patterns. To formalize this, we introduce ReuseRL, which grounds agentic RL in the Minimum Description Length (MDL) principle. ReuseRL extracts a shared skill dictionary from successful trajectories and augments the RL objective with a segmentation cost, explicitly penalizing idiosyncratic behaviors that encode poorly. We prove a PAC-Bayes generalization bound for this compression penalty. Across ALFWorld, TextWorld-Cooking, and Countdown-Stepwise, ReuseRL improves in- and out-of-distribution success over vanilla GRPO and strong round-length baselines.
Converted, Not Equivalent: Benchmarking Codebase Conversion via Observational Equivalence
May 27, 2026Coding agents increasingly act as codebase-scale collaborators that can assist with codebase conversion, but this progress has exposed a critical weakness: agents often over-trust their own local validation routines and declare success on artifacts that satisfy surface checks while violating the semantic contracts users actually care about. This problem is especially acute in codebase conversion, where prior evaluation is largely outcome-driven and therefore unstable: two implementations can match on a shallow outcome, such as a single forward loss, while diverging in gradients, optimizer behavior, or short-horizon training dynamics. We introduce T2J-Bench, a benchmark for codebase conversion that reformulates conversion as transfer under a fixed equivalence contract. A fixed verifier then compares source and converted codebases through three ordered stages: Spec (interface admissibility), Numeric (forward outputs, losses, gradients, and objective-specific tensors), and Behavioral (short training dynamics under fixed seeds). Across 355 blind conversion attempts, the best system reaches only 26.7--28.9% overall pass rate despite Spec pass rates up to 91.1%; a 4.7x token-budget spread yields only a 2.2x pass-rate spread; and all systems overestimate success by 66.6--97.8 points relative to the fixed evaluator. This suggests that failures stem more from contract-misaligned self-validation than from limited budget or backbone strength.
The Blind Spot of Agent Safety: How Benign User Instructions Expose Critical Vulnerabilities in Computer-Use Agents
Apr 12, 2026Computer-use agents (CUAs) can now autonomously complete complex tasks in real digital environments, but when misled, they can also be used to automate harmful actions programmatically. Existing safety evaluations largely target explicit threats such as misuse and prompt injection, but overlook a subtle yet critical setting where user instructions are entirely benign and harm arises from the task context or execution outcome. We introduce OS-BLIND, a benchmark that evaluates CUAs under unintended attack conditions, comprising 300 human-crafted tasks across 12 categories, 8 applications, and 2 threat clusters: environment-embedded threats and agent-initiated harms. Our evaluation on frontier models and agentic frameworks reveals that most CUAs exceed 90% attack success rate (ASR), and even the safety-aligned Claude 4.5 Sonnet reaches 73.0% ASR. More interestingly, this vulnerability becomes even more severe, with ASR rising from 73.0% to 92.7% when Claude 4.5 Sonnet is deployed in multi-agent systems. Our analysis further shows that existing safety defenses provide limited protection when user instructions are benign. Safety alignment primarily activates within the first few steps and rarely re-engages during subsequent execution. In multi-agent systems, decomposed subtasks obscure the harmful intent from the model, causing safety-aligned models to fail. We will release our OS-BLIND to encourage the broader research community to further investigate and address these safety challenges.
Video-Based Reward Modeling for Computer-Use Agents
Mar 10, 2026Computer-using agents (CUAs) are becoming increasingly capable; however, it remains difficult to scale evaluation of whether a trajectory truly fulfills a user instruction. In this work, we study reward modeling from execution video: a sequence of keyframes from an agent trajectory that is independent of the agent's internal reasoning or actions. Although video-execution modeling is method-agnostic, it presents key challenges, including highly redundant layouts and subtle, localized cues that determine success. We introduce Execution Video Reward 53k (ExeVR-53k), a dataset of 53k high-quality video--task--reward triplets. We further propose adversarial instruction translation to synthesize negative samples with step-level annotations. To enable learning from long, high-resolution execution videos, we design spatiotemporal token pruning, which removes homogeneous regions and persistent tokens while preserving decisive UI changes. Building on these components, we fine-tune an Execution Video Reward Model (ExeVRM) that takes only a user instruction and a video-execution sequence to predict task success. Our ExeVRM 8B achieves 84.7% accuracy and 87.7% recall on video-execution assessment, outperforming strong proprietary models such as GPT-5.2 and Gemini-3 Pro across Ubuntu, macOS, Windows, and Android, while providing more precise temporal attribution. These results show that video-execution reward modeling can serve as a scalable, model-agnostic evaluator for CUAs.
MED-COPILOT: A Medical Assistant Powered by GraphRAG and Similar Patient Case Retrieval
Feb 28, 2026Clinical decision-making requires synthesizing heterogeneous evidence, including patient histories, clinical guidelines, and trajectories of comparable cases. While large language models (LLMs) offer strong reasoning capabilities, they remain prone to hallucinations and struggle to integrate long, structured medical documents. We present MED-COPILOT, an interactive clinical decision-support system designed for clinicians and medical trainees, which combines guideline-grounded GraphRAG retrieval with hybrid semantic-keyword similar-patient retrieval to support transparent and evidence-aware clinical reasoning. The system builds a structured knowledge graph from WHO and NICE guidelines, applies community-level summarization for efficient retrieval, and maintains a 36,000-case similar-patient database derived from SOAP-normalized MIMIC-IV notes and Synthea-generated records. We evaluate our framework on clinical note completion and medical question answering, and demonstrate that it consistently outperforms parametric LLM baselines and standard RAG, improving both generation fidelity and clinical reasoning accuracy. The full system is available at https://huggingface.co/spaces/Cryo3978/Med_GraphRAG , enabling users to inspect retrieved evidence, visualize token-level similarity contributions, and conduct guided follow-up analysis. Our results demonstrate a practical and interpretable approach to integrating structured guideline knowledge with patient-level analogical evidence for clinical LLMs.
Experiential Reinforcement Learning
Feb 15, 2026Reinforcement learning has become the central approach for language models (LMs) to learn from environmental reward or feedback. In practice, the environmental feedback is usually sparse and delayed. Learning from such signals is challenging, as LMs must implicitly infer how observed failures should translate into behavioral changes for future iterations. We introduce Experiential Reinforcement Learning (ERL), a training paradigm that embeds an explicit experience-reflection-consolidation loop into the reinforcement learning process. Given a task, the model generates an initial attempt, receives environmental feedback, and produces a reflection that guides a refined second attempt, whose success is reinforced and internalized into the base policy. This process converts feedback into structured behavioral revision, improving exploration and stabilizing optimization while preserving gains at deployment without additional inference cost. Across sparse-reward control environments and agentic reasoning benchmarks, ERL consistently improves learning efficiency and final performance over strong reinforcement learning baselines, achieving gains of up to +81% in complex multi-step environments and up to +11% in tool-using reasoning tasks. These results suggest that integrating explicit self-reflection into policy training provides a practical mechanism for transforming feedback into durable behavioral improvement.
CoAct-1: Computer-using Agents with Coding as Actions
Aug 05, 2025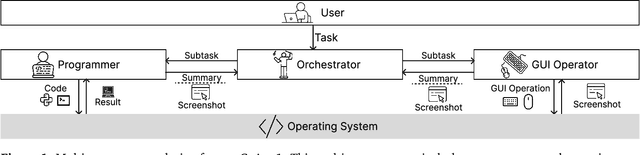
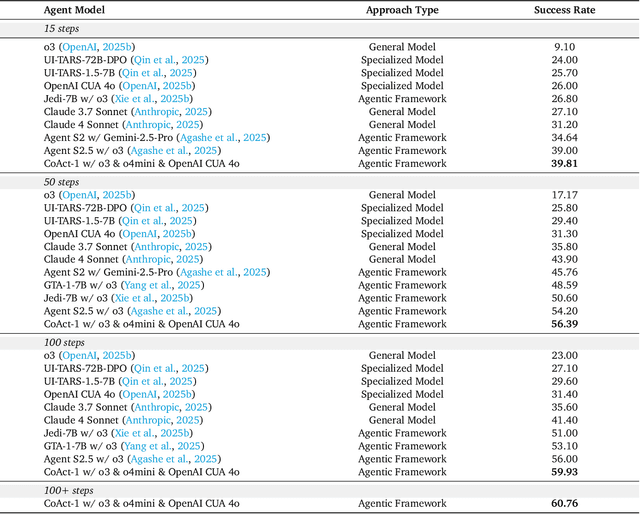
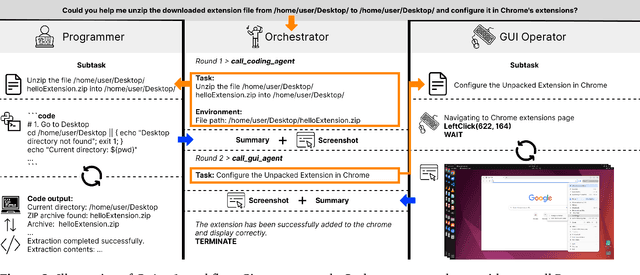

Autonomous agents that operate computers via Graphical User Interfaces (GUIs) often struggle with efficiency and reliability on complex, long-horizon tasks. While augmenting these agents with planners can improve task decomposition, they remain constrained by the inherent limitations of performing all actions through GUI manipulation, leading to brittleness and inefficiency. In this work, we introduce a more robust and flexible paradigm: enabling agents to use coding as a enhanced action. We present CoAct-1, a novel multi-agent system that synergistically combines GUI-based control with direct programmatic execution. CoAct-1 features an Orchestrator that dynamically delegates subtasks to either a conventional GUI Operator or a specialized Programmer agent, which can write and execute Python or Bash scripts. This hybrid approach allows the agent to bypass inefficient GUI action sequences for tasks like file management and data processing, while still leveraging visual interaction when necessary. We evaluate our system on the challenging OSWorld benchmark, where CoAct-1 achieves a new state-of-the-art success rate of 60.76%, significantly outperforming prior methods. Furthermore, our approach dramatically improves efficiency, reducing the average number of steps required to complete a task to just 10.15, compared to 15 for leading GUI agents. Our results demonstrate that integrating coding as a core action provides a more powerful, efficient, and scalable path toward generalized computer automation.
Can LLMs Express Personality Across Cultures? Introducing CulturalPersonas for Evaluating Trait Alignment
Jun 06, 2025As LLMs become central to interactive applications, ranging from tutoring to mental health, the ability to express personality in culturally appropriate ways is increasingly important. While recent works have explored personality evaluation of LLMs, they largely overlook the interplay between culture and personality. To address this, we introduce CulturalPersonas, the first large-scale benchmark with human validation for evaluating LLMs' personality expression in culturally grounded, behaviorally rich contexts. Our dataset spans 3,000 scenario-based questions across six diverse countries, designed to elicit personality through everyday scenarios rooted in local values. We evaluate three LLMs, using both multiple-choice and open-ended response formats. Our results show that CulturalPersonas improves alignment with country-specific human personality distributions (over a 20% reduction in Wasserstein distance across models and countries) and elicits more expressive, culturally coherent outputs compared to existing benchmarks. CulturalPersonas surfaces meaningful modulated trait outputs in response to culturally grounded prompts, offering new directions for aligning LLMs to global norms of behavior. By bridging personality expression and cultural nuance, we envision that CulturalPersonas will pave the way for more socially intelligent and globally adaptive LLMs.
SocialMaze: A Benchmark for Evaluating Social Reasoning in Large Language Models
May 29, 2025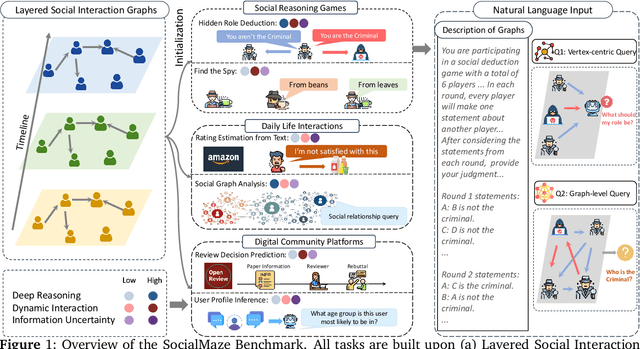
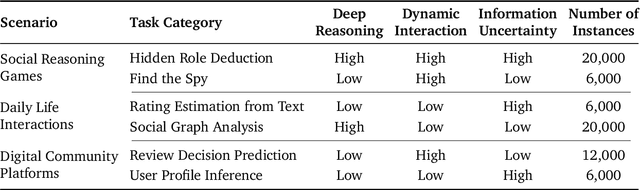
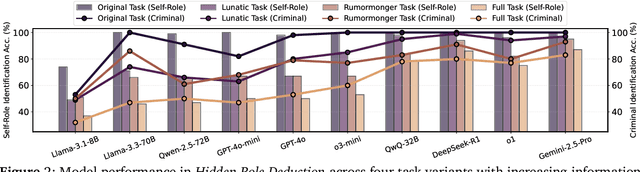
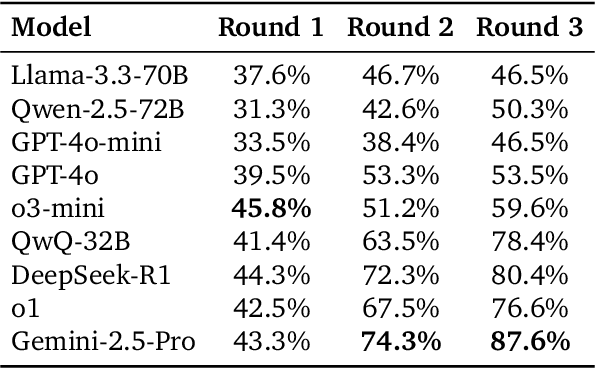
Large language models (LLMs) are increasingly applied to socially grounded tasks, such as online community moderation, media content analysis, and social reasoning games. Success in these contexts depends on a model's social reasoning ability - the capacity to interpret social contexts, infer others' mental states, and assess the truthfulness of presented information. However, there is currently no systematic evaluation framework that comprehensively assesses the social reasoning capabilities of LLMs. Existing efforts often oversimplify real-world scenarios and consist of tasks that are too basic to challenge advanced models. To address this gap, we introduce SocialMaze, a new benchmark specifically designed to evaluate social reasoning. SocialMaze systematically incorporates three core challenges: deep reasoning, dynamic interaction, and information uncertainty. It provides six diverse tasks across three key settings: social reasoning games, daily-life interactions, and digital community platforms. Both automated and human validation are used to ensure data quality. Our evaluation reveals several key insights: models vary substantially in their ability to handle dynamic interactions and integrate temporally evolving information; models with strong chain-of-thought reasoning perform better on tasks requiring deeper inference beyond surface-level cues; and model reasoning degrades significantly under uncertainty. Furthermore, we show that targeted fine-tuning on curated reasoning examples can greatly improve model performance in complex social scenarios. The dataset is publicly available at: https://huggingface.co/datasets/MBZUAI/SocialMaze