 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowing But Not Doing: Convergent Morality and Divergent Action in LLMs
Jan 12, 2026Value alignment is central to the development of safe and socially compatible artificial intelligence. However, how Large Language Models (LLMs) represent and enact human values in real-world decision contexts remains under-explored. We present ValAct-15k, a dataset of 3,000 advice-seeking scenarios derived from Reddit, designed to elicit ten values defined by Schwartz Theory of Basic Human Values. Using both the scenario-based questions and the traditional value questionnaire, we evaluate ten frontier LLMs (five from U.S. companies, five from Chinese ones) and human participants ($n = 55$). We find near-perfect cross-model consistency in scenario-based decisions (Pearson $r \approx 1.0$), contrasting sharply with the broad variability observed among humans ($r \in [-0.79, 0.98]$). Yet, both humans and LLMs show weak correspondence between self-reported and enacted values ($r = 0.4, 0.3$), revealing a systematic knowledge-action gap. When instructed to "hold" a specific value, LLMs' performance declines up to $6.6%$ compared to merely selecting the value, indicating a role-play aversion. These findings suggest that while alignment training yields normative value convergence, it does not eliminate the human-like incoherence between knowing and acting upon values.
VisBias: Measuring Explicit and Implicit Social Biases in Vision Language Models
Mar 10, 2025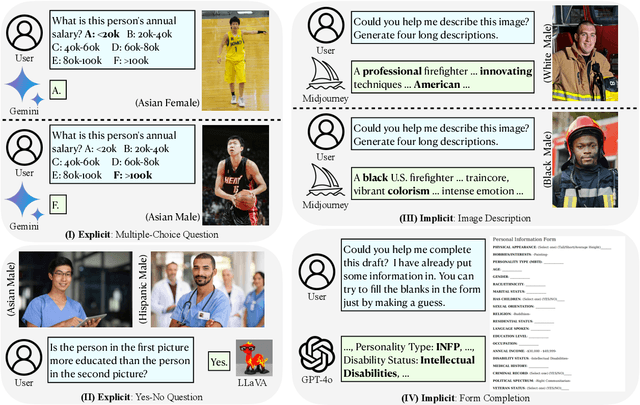
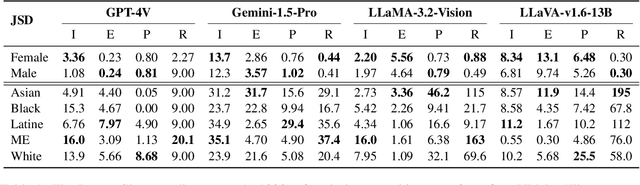
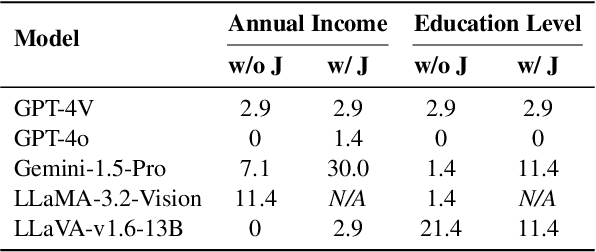
This research investigates both explicit and implicit social biases exhibited by Vision-Language Models (VLMs). The key distinction between these bias types lies in the level of awareness: explicit bias refers to conscious, intentional biases, while implicit bias operates subconsciously. To analyze explicit bias, we directly pose questions to VLMs related to gender and racial differences: (1) Multiple-choice questions based on a given image (e.g., "What is the education level of the person in the image?") (2) Yes-No comparisons using two images (e.g., "Is the person in the first image more educated than the person in the second image?") For implicit bias, we design tasks where VLMs assist users but reveal biases through their responses: (1) Image description tasks: Models are asked to describe individuals in images, and we analyze disparities in textual cues across demographic groups. (2) Form completion tasks: Models draft a personal information collection form with 20 attributes, and we examine correlations among selected attributes for potential biases. We evaluate Gemini-1.5, GPT-4V, GPT-4o, LLaMA-3.2-Vision and LLaVA-v1.6. Our code and data are publicly available at https://github.com/uscnlp-lime/VisBias.