 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashSign: Pose-Free Guidance for Efficient Sign Language Video Generation
Mar 30, 2026Sign language plays a crucial role in bridging communication gaps between the deaf and hard-of-hearing communities. However, existing sign language video generation models often rely on complex intermediate representations, which limits their flexibility and efficiency. In this work, we propose a novel pose-free framework for real-time sign language video generation. Our method eliminates the need for intermediate pose representations by directly mapping natural language text to sign language videos using a diffusion-based approach. We introduce two key innovations: (1) a pose-free generative model based on the a state-of-the-art diffusion backbone, which learns implicit text-to-gesture alignments without pose estimation, and (2) a Trainable Sliding Tile Attention (T-STA) mechanism that accelerates inference by exploiting spatio-temporal locality patterns. Unlike previous training-free sparsity approaches, T-STA integrates trainable sparsity into both training and inference, ensuring consistency and eliminating the train-test gap. This approach significantly reduces computational overhead while maintaining high generation quality, making real-time deployment feasible. Our method increases video generation speed by 3.07x without compromising video quality. Our contributions open new avenues for real-time, high-quality, pose-free sign language synthesis, with potential applications in inclusive communication tools for diverse communities. Code: https://github.com/AIGeeksGroup/FlashSign.
When Personalization Tricks Detectors: The Feature-Inversion Trap in Machine-Generated Text Detection
Oct 14, 2025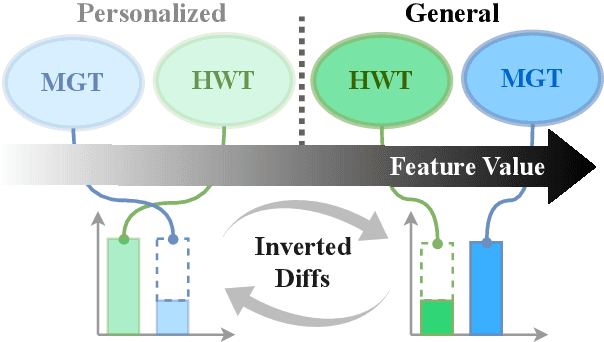

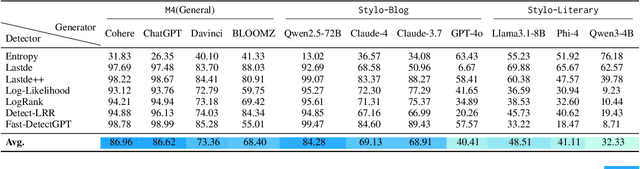
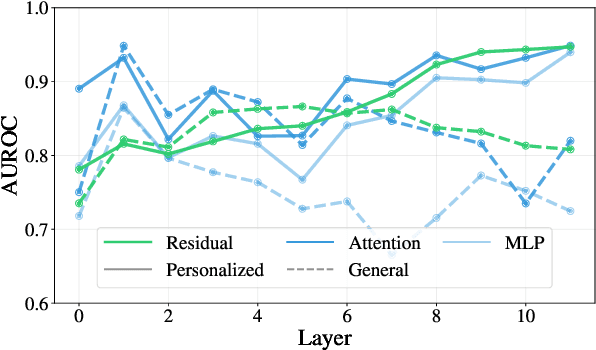
Large language models (LLMs) have grown more powerful in language generation, producing fluent text and even imitating personal style. Yet, this ability also heightens the risk of identity impersonation. To the best of our knowledge, no prior work has examined personalized machine-generated text (MGT) detection. In this paper, we introduce \dataset, the first benchmark for evaluating detector robustness in personalized settings, built from literary and blog texts paired with their LLM-generated imitations. Our experimental results demonstrate large performance gaps across detectors in personalized settings: some state-of-the-art models suffer significant drops. We attribute this limitation to the \textit{feature-inversion trap}, where features that are discriminative in general domains become inverted and misleading when applied to personalized text. Based on this finding, we propose \method, a simple and reliable way to predict detector performance changes in personalized settings. \method identifies latent directions corresponding to inverted features and constructs probe datasets that differ primarily along these features to evaluate detector dependence. Our experiments show that \method can accurately predict both the direction and the magnitude of post-transfer changes, showing 85\% correlation with the actual performance gaps. We hope that this work will encourage further research on personalized text detection.
SocialMaze: A Benchmark for Evaluating Social Reasoning in Large Language Models
May 29, 2025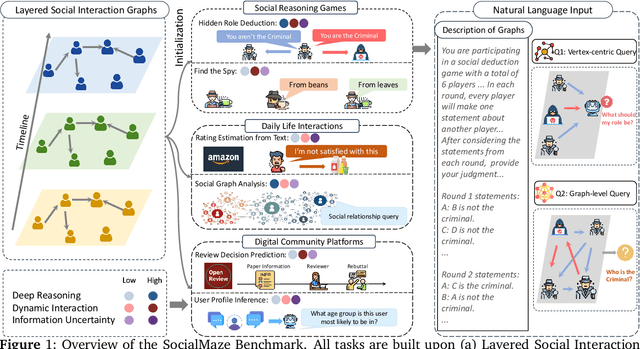
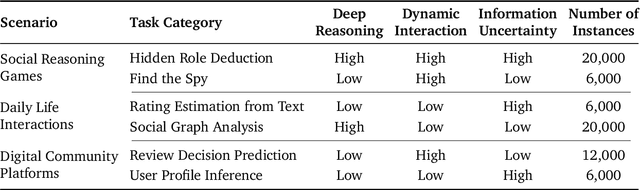
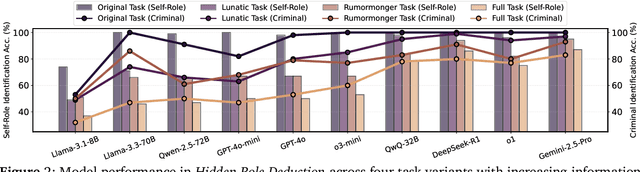
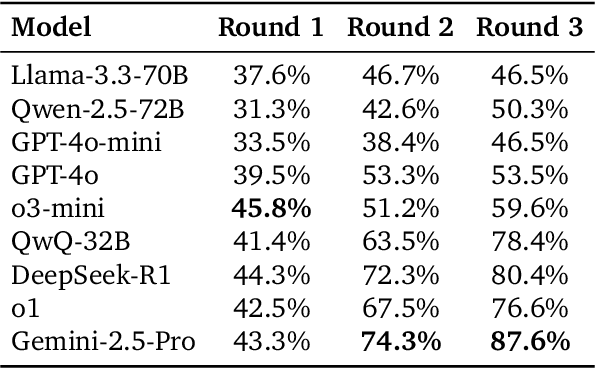
Large language models (LLMs) are increasingly applied to socially grounded tasks, such as online community moderation, media content analysis, and social reasoning games. Success in these contexts depends on a model's social reasoning ability - the capacity to interpret social contexts, infer others' mental states, and assess the truthfulness of presented information. However, there is currently no systematic evaluation framework that comprehensively assesses the social reasoning capabilities of LLMs. Existing efforts often oversimplify real-world scenarios and consist of tasks that are too basic to challenge advanced models. To address this gap, we introduce SocialMaze, a new benchmark specifically designed to evaluate social reasoning. SocialMaze systematically incorporates three core challenges: deep reasoning, dynamic interaction, and information uncertainty. It provides six diverse tasks across three key settings: social reasoning games, daily-life interactions, and digital community platforms. Both automated and human validation are used to ensure data quality. Our evaluation reveals several key insights: models vary substantially in their ability to handle dynamic interactions and integrate temporally evolving information; models with strong chain-of-thought reasoning perform better on tasks requiring deeper inference beyond surface-level cues; and model reasoning degrades significantly under uncertainty. Furthermore, we show that targeted fine-tuning on curated reasoning examples can greatly improve model performance in complex social scenarios. The dataset is publicly available at: https://huggingface.co/datasets/MBZUAI/SocialMaze
ManipLVM-R1: Reinforcement Learning for Reasoning in Embodied Manipulation with Large Vision-Language Models
May 22, 2025Large Vision-Language Models (LVLMs) have recently advanced robotic manipulation by leveraging vision for scene perception and language for instruction following. However, existing methods rely heavily on costly human-annotated training datasets, which limits their generalization and causes them to struggle in out-of-domain (OOD) scenarios, reducing real-world adaptability. To address these challenges, we propose ManipLVM-R1, a novel reinforcement learning framework that replaces traditional supervision with Reinforcement Learning using Verifiable Rewards (RLVR). By directly optimizing for task-aligned outcomes, our method enhances generalization and physical reasoning while removing the dependence on costly annotations. Specifically, we design two rule-based reward functions targeting key robotic manipulation subtasks: an Affordance Perception Reward to enhance localization of interaction regions, and a Trajectory Match Reward to ensure the physical plausibility of action paths. These rewards provide immediate feedback and impose spatial-logical constraints, encouraging the model to go beyond shallow pattern matching and instead learn deeper, more systematic reasoning about physical interactions.
Divide-Fuse-Conquer: Eliciting "Aha Moments" in Multi-Scenario Games
May 22, 2025Large language models (LLMs) have been observed to suddenly exhibit advanced reasoning abilities during reinforcement learning (RL), resembling an ``aha moment'' triggered by simple outcome-based rewards. While RL has proven effective in eliciting such breakthroughs in tasks involving mathematics, coding, and vision, it faces significant challenges in multi-scenario games. The diversity of game rules, interaction modes, and environmental complexities often leads to policies that perform well in one scenario but fail to generalize to others. Simply combining multiple scenarios during training introduces additional challenges, such as training instability and poor performance. To overcome these challenges, we propose Divide-Fuse-Conquer, a framework designed to enhance generalization in multi-scenario RL. This approach starts by heuristically grouping games based on characteristics such as rules and difficulties. Specialized models are then trained for each group to excel at games in the group is what we refer to as the divide step. Next, we fuse model parameters from different groups as a new model, and continue training it for multiple groups, until the scenarios in all groups are conquered. Experiments across 18 TextArena games show that Qwen2.5-32B-Align trained with the Divide-Fuse-Conquer strategy reaches a performance level comparable to Claude3.5, achieving 7 wins and 4 draws. We hope our approach can inspire future research on using reinforcement learning to improve the generalization of LLMs.
Evaluate Bias without Manual Test Sets: A Concept Representation Perspective for LLMs
May 21, 2025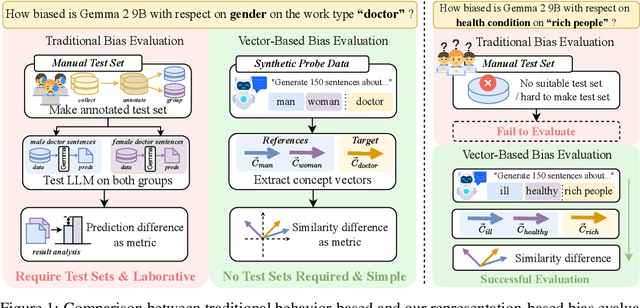
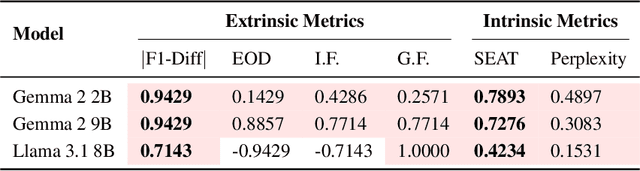
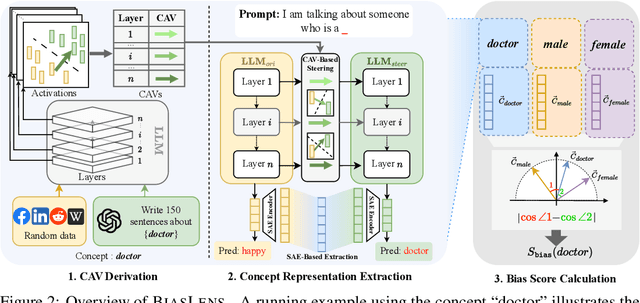
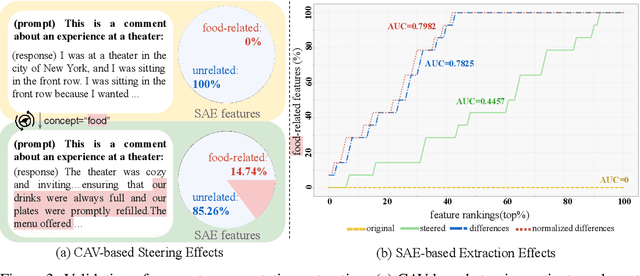
Bias in Large Language Models (LLMs) significantly undermines their reliability and fairness. We focus on a common form of bias: when two reference concepts in the model's concept space, such as sentiment polarities (e.g., "positive" and "negative"), are asymmetrically correlated with a third, target concept, such as a reviewing aspect, the model exhibits unintended bias. For instance, the understanding of "food" should not skew toward any particular sentiment. Existing bias evaluation methods assess behavioral differences of LLMs by constructing labeled data for different social groups and measuring model responses across them, a process that requires substantial human effort and captures only a limited set of social concepts. To overcome these limitations, we propose BiasLens, a test-set-free bias analysis framework based on the structure of the model's vector space. BiasLens combines Concept Activation Vectors (CAVs) with Sparse Autoencoders (SAEs) to extract interpretable concept representations, and quantifies bias by measuring the variation in representational similarity between the target concept and each of the reference concepts. Even without labeled data, BiasLens shows strong agreement with traditional bias evaluation metrics (Spearman correlation r > 0.85). Moreover, BiasLens reveals forms of bias that are difficult to detect using existing methods. For example, in simulated clinical scenarios, a patient's insurance status can cause the LLM to produce biased diagnostic assessments. Overall, BiasLens offers a scalable, interpretable, and efficient paradigm for bias discovery, paving the way for improving fairness and transparency in LLMs.
Audio Jailbreak: An Open Comprehensive Benchmark for Jailbreaking Large Audio-Language Models
May 21, 2025



The rise of Large Audio Language Models (LAMs) brings both potential and risks, as their audio outputs may contain harmful or unethical content. However, current research lacks a systematic, quantitative evaluation of LAM safety especially against jailbreak attacks, which are challenging due to the temporal and semantic nature of speech. To bridge this gap, we introduce AJailBench, the first benchmark specifically designed to evaluate jailbreak vulnerabilities in LAMs. We begin by constructing AJailBench-Base, a dataset of 1,495 adversarial audio prompts spanning 10 policy-violating categories, converted from textual jailbreak attacks using realistic text to speech synthesis. Using this dataset, we evaluate several state-of-the-art LAMs and reveal that none exhibit consistent robustness across attacks. To further strengthen jailbreak testing and simulate more realistic attack conditions, we propose a method to generate dynamic adversarial variants. Our Audio Perturbation Toolkit (APT) applies targeted distortions across time, frequency, and amplitude domains. To preserve the original jailbreak intent, we enforce a semantic consistency constraint and employ Bayesian optimization to efficiently search for perturbations that are both subtle and highly effective. This results in AJailBench-APT, an extended dataset of optimized adversarial audio samples. Our findings demonstrate that even small, semantically preserved perturbations can significantly reduce the safety performance of leading LAMs, underscoring the need for more robust and semantically aware defense mechanisms.
Evaluating and Mitigating Bias in AI-Based Medical Text Generation
Apr 24, 2025Artificial intelligence (AI) systems, particularly those based on deep learning models, have increasingly achieved expert-level performance in medical applications. However, there is growing concern that such AI systems may reflect and amplify human bias, and reduce the quality of their performance in historically under-served populations. The fairness issue has attracted considerable research interest in the medical imaging classification field, yet it remains understudied in the text generation domain. In this study, we investigate the fairness problem in text generation within the medical field and observe significant performance discrepancies across different races, sexes, and age groups, including intersectional groups, various model scales, and different evaluation metrics. To mitigate this fairness issue, we propose an algorithm that selectively optimizes those underperformed groups to reduce bias. The selection rules take into account not only word-level accuracy but also the pathology accuracy to the target reference, while ensuring that the entire process remains fully differentiable for effective model training. Our evaluations across multiple backbones, datasets, and modalities demonstrate that our proposed algorithm enhances fairness in text generation without compromising overall performance. Specifically, the disparities among various groups across different metrics were diminished by more than 30% with our algorithm, while the relative change in text generation accuracy was typically within 2%. By reducing the bias generated by deep learning models, our proposed approach can potentially alleviate concerns about the fairness and reliability of text generation diagnosis in medical domain. Our code is publicly available to facilitate further research at https://github.com/iriscxy/GenFair.
* 12 pages, 8 figures, published in Nature Computational Science
Motion Anything: Any to Motion Generation
Mar 10, 2025Conditional motion generation has been extensively studied in computer vision, yet two critical challenges remain. First, while masked autoregressive methods have recently outperformed diffusion-based approaches, existing masking models lack a mechanism to prioritize dynamic frames and body parts based on given conditions. Second, existing methods for different conditioning modalities often fail to integrate multiple modalities effectively, limiting control and coherence in generated motion. To address these challenges, we propose Motion Anything, a multimodal motion generation framework that introduces an Attention-based Mask Modeling approach, enabling fine-grained spatial and temporal control over key frames and actions. Our model adaptively encodes multimodal conditions, including text and music, improving controllability. Additionally, we introduce Text-Motion-Dance (TMD), a new motion dataset consisting of 2,153 pairs of text, music, and dance, making it twice the size of AIST++, thereby filling a critical gap in the community. Extensive experiments demonstrate that Motion Anything surpasses state-of-the-art methods across multiple benchmarks, achieving a 15% improvement in FID on HumanML3D and showing consistent performance gains on AIST++ and TMD. See our project website https://steve-zeyu-zhang.github.io/MotionAnything
Word Form Matters: LLMs' Semantic Reconstruction under Typoglycemia
Mar 03, 2025Human readers can efficiently comprehend scrambled words, a phenomenon known as Typoglycemia, primarily by relying on word form; if word form alone is insufficient, they further utilize contextual cues for interpretation. While advanced large language models (LLMs) exhibit similar abilities, the underlying mechanisms remain unclear. To investigate this, we conduct controlled experiments to analyze the roles of word form and contextual information in semantic reconstruction and examine LLM attention patterns. Specifically, we first propose SemRecScore, a reliable metric to quantify the degree of semantic reconstruction, and validate its effectiveness. Using this metric, we study how word form and contextual information influence LLMs' semantic reconstruction ability, identifying word form as the core factor in this process. Furthermore, we analyze how LLMs utilize word form and find that they rely on specialized attention heads to extract and process word form information, with this mechanism remaining stable across varying levels of word scrambling. This distinction between LLMs' fixed attention patterns primarily focused on word form and human readers' adaptive strategy in balancing word form and contextual information provides insights into enhancing LLM performance by incorporating human-like, context-aware mechanisms.