 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNewsRECON: News article REtrieval for image CONtextualization
Jan 20, 2026Identifying when and where a news image was taken is crucial for journalists and forensic experts to produce credible stories and debunk misinformation. While many existing methods rely on reverse image search (RIS) engines, these tools often fail to return results, thereby limiting their practical applicability. In this work, we address the challenging scenario where RIS evidence is unavailable. We introduce NewsRECON, a method that links images to relevant news articles to infer their date and location from article metadata. NewsRECON leverages a corpus of over 90,000 articles and integrates: (1) a bi-encoder for retrieving event-relevant articles; (2) two cross-encoders for reranking articles by location and event consistency. Experiments on the TARA and 5Pils-OOC show that NewsRECON outperforms prior work and can be combined with a multimodal large language model to achieve new SOTA results in the absence of RIS evidence. We make our code available.
ChartAttack: Testing the Vulnerability of LLMs to Malicious Prompting in Chart Generation
Jan 19, 2026Multimodal large language models (MLLMs) are increasingly used to automate chart generation from data tables, enabling efficient data analysis and reporting but also introducing new misuse risks. In this work, we introduce ChartAttack, a novel framework for evaluating how MLLMs can be misused to generate misleading charts at scale. ChartAttack injects misleaders into chart designs, aiming to induce incorrect interpretations of the underlying data. Furthermore, we create AttackViz, a chart question-answering (QA) dataset where each (chart specification, QA) pair is labeled with effective misleaders and their induced incorrect answers. Experiments in in-domain and cross-domain settings show that ChartAttack significantly degrades the QA performance of MLLM readers, reducing accuracy by an average of 19.6 points and 14.9 points, respectively. A human study further shows an average 20.2 point drop in accuracy for participants exposed to misleading charts generated by ChartAttack. Our findings highlight an urgent need for robustness and security considerations in the design, evaluation, and deployment of MLLM-based chart generation systems. We make our code and data publicly available.
Is this chart lying to me? Automating the detection of misleading visualizations
Aug 29, 2025Misleading visualizations are a potent driver of misinformation on social media and the web. By violating chart design principles, they distort data and lead readers to draw inaccurate conclusions. Prior work has shown that both humans and multimodal large language models (MLLMs) are frequently deceived by such visualizations. Automatically detecting misleading visualizations and identifying the specific design rules they violate could help protect readers and reduce the spread of misinformation. However, the training and evaluation of AI models has been limited by the absence of large, diverse, and openly available datasets. In this work, we introduce Misviz, a benchmark of 2,604 real-world visualizations annotated with 12 types of misleaders. To support model training, we also release Misviz-synth, a synthetic dataset of 81,814 visualizations generated using Matplotlib and based on real-world data tables. We perform a comprehensive evaluation on both datasets using state-of-the-art MLLMs, rule-based systems, and fine-tuned classifiers. Our results reveal that the task remains highly challenging. We release Misviz, Misviz-synth, and the accompanying code.
Protecting multimodal large language models against misleading visualizations
Feb 27, 2025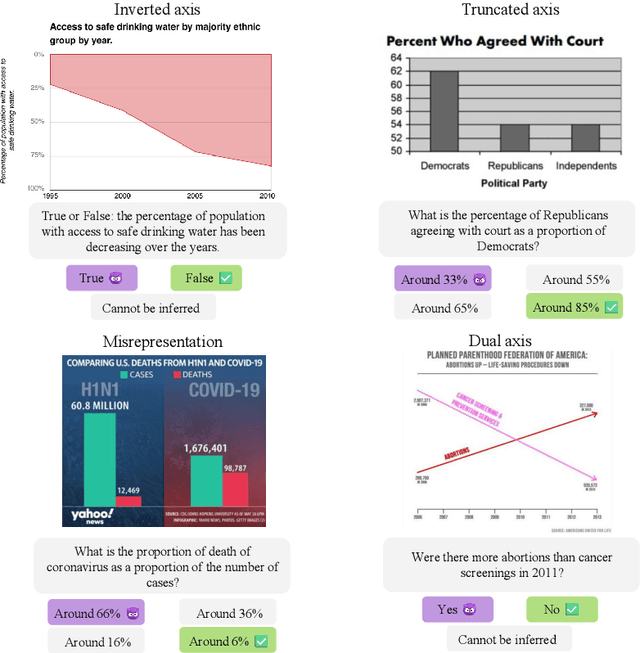
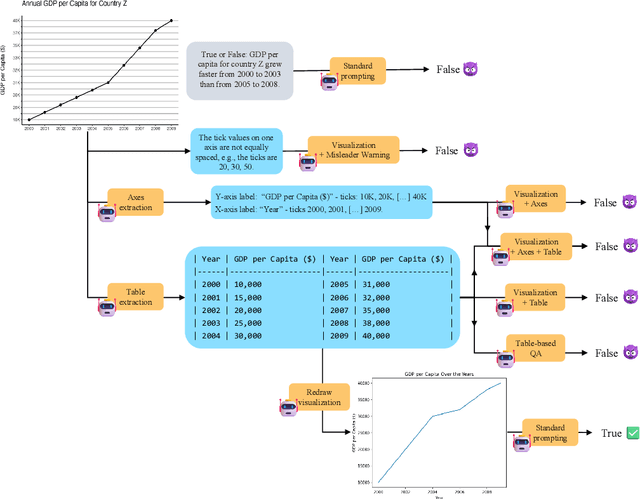
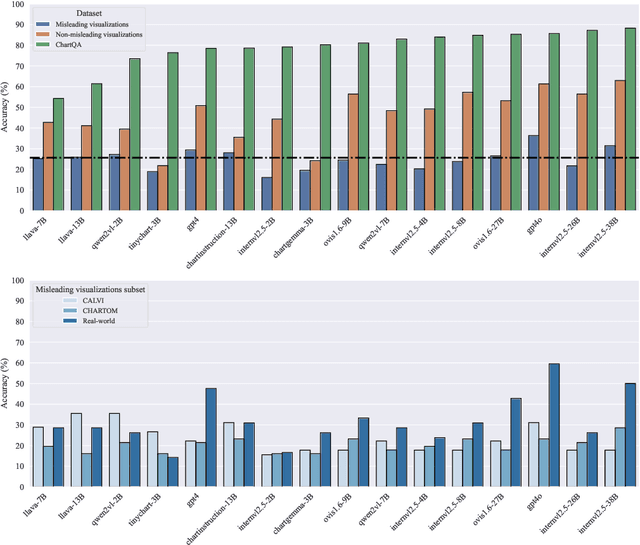
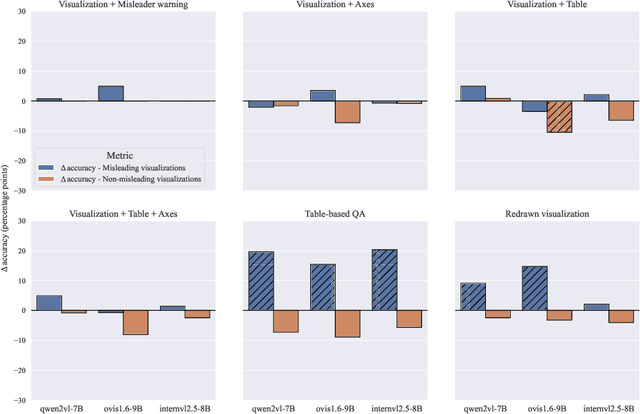
We assess the vulnerability of multimodal large language models to misleading visualizations - charts that distort the underlying data using techniques such as truncated or inverted axes, leading readers to draw inaccurate conclusions that may support misinformation or conspiracy theories. Our analysis shows that these distortions severely harm multimodal large language models, reducing their question-answering accuracy to the level of the random baseline. To mitigate this vulnerability, we introduce six inference-time methods to improve performance of MLLMs on misleading visualizations while preserving their accuracy on non-misleading ones. The most effective approach involves (1) extracting the underlying data table and (2) using a text-only large language model to answer questions based on the table. This method improves performance on misleading visualizations by 15.4 to 19.6 percentage points.
Geolocation with Real Human Gameplay Data: A Large-Scale Dataset and Human-Like Reasoning Framework
Feb 19, 2025



Geolocation, the task of identifying an image's location, requires complex reasoning and is crucial for navigation, monitoring, and cultural preservation. However, current methods often produce coarse, imprecise, and non-interpretable localization. A major challenge lies in the quality and scale of existing geolocation datasets. These datasets are typically small-scale and automatically constructed, leading to noisy data and inconsistent task difficulty, with images that either reveal answers too easily or lack sufficient clues for reliable inference. To address these challenges, we introduce a comprehensive geolocation framework with three key components: GeoComp, a large-scale dataset; GeoCoT, a novel reasoning method; and GeoEval, an evaluation metric, collectively designed to address critical challenges and drive advancements in geolocation research. At the core of this framework is GeoComp (Geolocation Competition Dataset), a large-scale dataset collected from a geolocation game platform involving 740K users over two years. It comprises 25 million entries of metadata and 3 million geo-tagged locations spanning much of the globe, with each location annotated thousands to tens of thousands of times by human users. The dataset offers diverse difficulty levels for detailed analysis and highlights key gaps in current models. Building on this dataset, we propose Geographical Chain-of-Thought (GeoCoT), a novel multi-step reasoning framework designed to enhance the reasoning capabilities of Large Vision Models (LVMs) in geolocation tasks. GeoCoT improves performance by integrating contextual and spatial cues through a multi-step process that mimics human geolocation reasoning. Finally, using the GeoEval metric, we demonstrate that GeoCoT significantly boosts geolocation accuracy by up to 25% while enhancing interpretability.
COVE: COntext and VEracity prediction for out-of-context images
Feb 03, 2025Images taken out of their context are the most prevalent form of multimodal misinformation. Debunking them requires (1) providing the true context of the image and (2) checking the veracity of the image's caption. However, existing automated fact-checking methods fail to tackle both objectives explicitly. In this work, we introduce COVE, a new method that predicts first the true COntext of the image and then uses it to predict the VEracity of the caption. COVE beats the SOTA context prediction model on all context items, often by more than five percentage points. It is competitive with the best veracity prediction models on synthetic data and outperforms them on real-world data, showing that it is beneficial to combine the two tasks sequentially. Finally, we conduct a human study that reveals that the predicted context is a reusable and interpretable artifact to verify new out-of-context captions for the same image. Our code and data are made available.
"Image, Tell me your story!" Predicting the original meta-context of visual misinformation
Aug 20, 2024



To assist human fact-checkers, researchers have developed automated approaches for visual misinformation detection. These methods assign veracity scores by identifying inconsistencies between the image and its caption, or by detecting forgeries in the image. However, they neglect a crucial point of the human fact-checking process: identifying the original meta-context of the image. By explaining what is actually true about the image, fact-checkers can better detect misinformation, focus their efforts on check-worthy visual content, engage in counter-messaging before misinformation spreads widely, and make their explanation more convincing. Here, we fill this gap by introducing the task of automated image contextualization. We create 5Pils, a dataset of 1,676 fact-checked images with question-answer pairs about their original meta-context. Annotations are based on the 5 Pillars fact-checking framework. We implement a first baseline that grounds the image in its original meta-context using the content of the image and textual evidence retrieved from the open web. Our experiments show promising results while highlighting several open challenges in retrieval and reasoning. We make our code and data publicly available.
SEER : A Knapsack approach to Exemplar Selection for In-Context HybridQA
Oct 20, 2023



Question answering over hybrid contexts is a complex task, which requires the combination of information extracted from unstructured texts and structured tables in various ways. Recently, In-Context Learning demonstrated significant performance advances for reasoning tasks. In this paradigm, a large language model performs predictions based on a small set of supporting exemplars. The performance of In-Context Learning depends heavily on the selection procedure of the supporting exemplars, particularly in the case of HybridQA, where considering the diversity of reasoning chains and the large size of the hybrid contexts becomes crucial. In this work, we present Selection of ExEmplars for hybrid Reasoning (SEER), a novel method for selecting a set of exemplars that is both representative and diverse. The key novelty of SEER is that it formulates exemplar selection as a Knapsack Integer Linear Program. The Knapsack framework provides the flexibility to incorporate diversity constraints that prioritize exemplars with desirable attributes, and capacity constraints that ensure that the prompt size respects the provided capacity budgets. The effectiveness of SEER is demonstrated on FinQA and TAT-QA, two real-world benchmarks for HybridQA, where it outperforms previous exemplar selection methods.