 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Consumer Behavior Theory: Foundations of a Novel Research Field
Jun 16, 2026Large language models (LLMs) are increasingly deployed as autonomous agents that make consumption decisions on behalf of users. This shift raises fundamental questions for consumer theory, which has traditionally modeled humans as the primary decision-makers. In this paper, we introduce LLM Consumer Behavior Theory, a new field of study concerned with analyzing consumer behavior in agentic markets. Drawing on classical and behavioral economics alongside recent advances in Natural Language Processing, we formalize how human preferences are reflected and acted upon by LLM-based agents, and how agent-level decisions aggregate into market demand. We unify previously fragmented literature on LLM decision-making, human behavior simulation, and preference elicitation under a common economic lens, highlighting where assumptions, such as rationality and heterogeneity, may fail in agentic markets. Rather than providing empirical validation, this paper outlines the scope of LLM consumer behavior and identifies open research questions related to alignment, preference representation, and market dynamics.
Would a Large Language Model Pay Extra for a View? Inferring Willingness to Pay from Subjective Choices
Feb 10, 2026As Large Language Models (LLMs) are increasingly deployed in applications such as travel assistance and purchasing support, they are often required to make subjective choices on behalf of users in settings where no objectively correct answer exists. We study LLM decision-making in a travel-assistant context by presenting models with choice dilemmas and analyzing their responses using multinomial logit models to derive implied willingness to pay (WTP) estimates. These WTP values are subsequently compared to human benchmark values from the economics literature. In addition to a baseline setting, we examine how model behavior changes under more realistic conditions, including the provision of information about users' past choices and persona-based prompting. Our results show that while meaningful WTP values can be derived for larger LLMs, they also display systematic deviations at the attribute level. Additionally, they tend to overestimate human WTP overall, particularly when expensive options or business-oriented personas are introduced. Conditioning models on prior preferences for cheaper options yields valuations that are closer to human benchmarks. Overall, our findings highlight both the potential and the limitations of using LLMs for subjective decision support and underscore the importance of careful model selection, prompt design, and user representation when deploying such systems in practice.
On the Performance of LLMs for Real Estate Appraisal
Jun 13, 2025The real estate market is vital to global economies but suffers from significant information asymmetry. This study examines how Large Language Models (LLMs) can democratize access to real estate insights by generating competitive and interpretable house price estimates through optimized In-Context Learning (ICL) strategies. We systematically evaluate leading LLMs on diverse international housing datasets, comparing zero-shot, few-shot, market report-enhanced, and hybrid prompting techniques. Our results show that LLMs effectively leverage hedonic variables, such as property size and amenities, to produce meaningful estimates. While traditional machine learning models remain strong for pure predictive accuracy, LLMs offer a more accessible, interactive and interpretable alternative. Although self-explanations require cautious interpretation, we find that LLMs explain their predictions in agreement with state-of-the-art models, confirming their trustworthiness. Carefully selected in-context examples based on feature similarity and geographic proximity, significantly enhance LLM performance, yet LLMs struggle with overconfidence in price intervals and limited spatial reasoning. We offer practical guidance for structured prediction tasks through prompt optimization. Our findings highlight LLMs' potential to improve transparency in real estate appraisal and provide actionable insights for stakeholders.
Native Design Bias: Studying the Impact of English Nativeness on Language Model Performance
Jun 25, 2024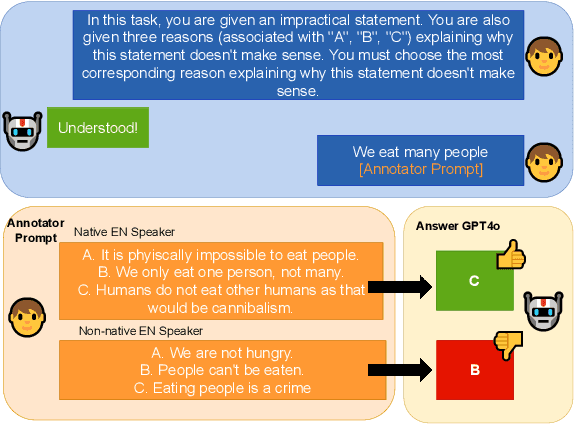
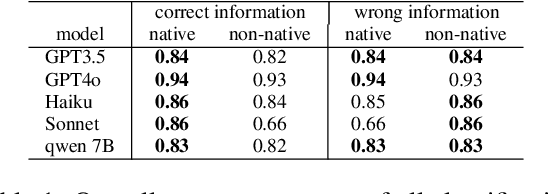
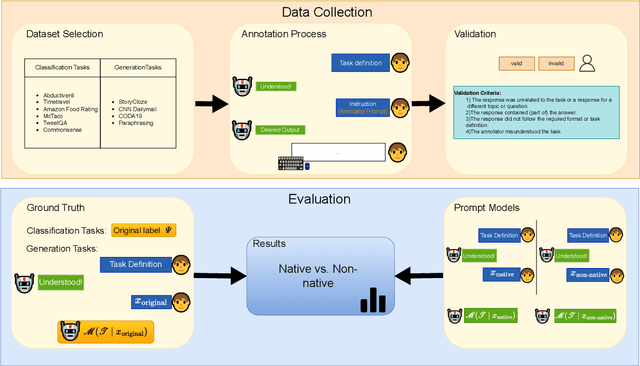
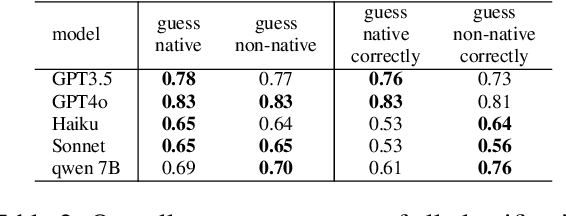
Large Language Models (LLMs) excel at providing information acquired during pretraining on large-scale corpora and following instructions through user prompts. This study investigates whether the quality of LLM responses varies depending on the demographic profile of users. Considering English as the global lingua franca, along with the diversity of its dialects among speakers of different native languages, we explore whether non-native English speakers receive lower-quality or even factually incorrect responses from LLMs more frequently. Our results show that performance discrepancies occur when LLMs are prompted by native versus non-native English speakers and persist when comparing native speakers from Western countries with others. Additionally, we find a strong anchoring effect when the model recognizes or is made aware of the user's nativeness, which further degrades the response quality when interacting with non-native speakers. Our analysis is based on a newly collected dataset with over 12,000 unique annotations from 124 annotators, including information on their native language and English proficiency.
SEER : A Knapsack approach to Exemplar Selection for In-Context HybridQA
Oct 20, 2023



Question answering over hybrid contexts is a complex task, which requires the combination of information extracted from unstructured texts and structured tables in various ways. Recently, In-Context Learning demonstrated significant performance advances for reasoning tasks. In this paradigm, a large language model performs predictions based on a small set of supporting exemplars. The performance of In-Context Learning depends heavily on the selection procedure of the supporting exemplars, particularly in the case of HybridQA, where considering the diversity of reasoning chains and the large size of the hybrid contexts becomes crucial. In this work, we present Selection of ExEmplars for hybrid Reasoning (SEER), a novel method for selecting a set of exemplars that is both representative and diverse. The key novelty of SEER is that it formulates exemplar selection as a Knapsack Integer Linear Program. The Knapsack framework provides the flexibility to incorporate diversity constraints that prioritize exemplars with desirable attributes, and capacity constraints that ensure that the prompt size respects the provided capacity budgets. The effectiveness of SEER is demonstrated on FinQA and TAT-QA, two real-world benchmarks for HybridQA, where it outperforms previous exemplar selection methods.
Investigating Bias in Multilingual Language Models: Cross-Lingual Transfer of Debiasing Techniques
Oct 16, 2023



This paper investigates the transferability of debiasing techniques across different languages within multilingual models. We examine the applicability of these techniques in English, French, German, and Dutch. Using multilingual BERT (mBERT), we demonstrate that cross-lingual transfer of debiasing techniques is not only feasible but also yields promising results. Surprisingly, our findings reveal no performance disadvantages when applying these techniques to non-English languages. Using translations of the CrowS-Pairs dataset, our analysis identifies SentenceDebias as the best technique across different languages, reducing bias in mBERT by an average of 13%. We also find that debiasing techniques with additional pretraining exhibit enhanced cross-lingual effectiveness for the languages included in the analyses, particularly in lower-resource languages. These novel insights contribute to a deeper understanding of bias mitigation in multilingual language models and provide practical guidance for debiasing techniques in different language contexts.