 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNative Design Bias: Studying the Impact of English Nativeness on Language Model Performance
Paper and Code
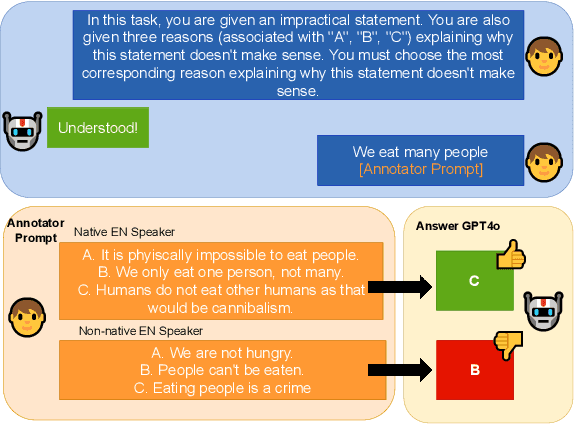
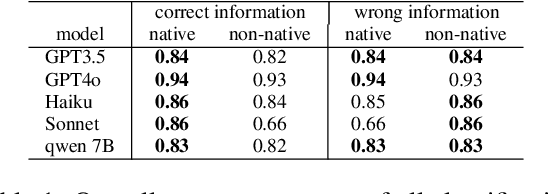
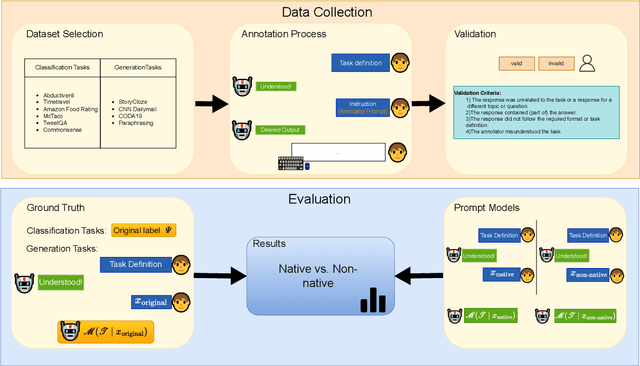
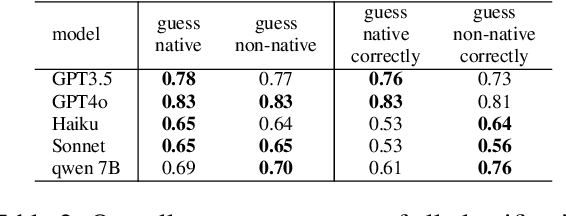
Large Language Models (LLMs) excel at providing information acquired during pretraining on large-scale corpora and following instructions through user prompts. This study investigates whether the quality of LLM responses varies depending on the demographic profile of users. Considering English as the global lingua franca, along with the diversity of its dialects among speakers of different native languages, we explore whether non-native English speakers receive lower-quality or even factually incorrect responses from LLMs more frequently. Our results show that performance discrepancies occur when LLMs are prompted by native versus non-native English speakers and persist when comparing native speakers from Western countries with others. Additionally, we find a strong anchoring effect when the model recognizes or is made aware of the user's nativeness, which further degrades the response quality when interacting with non-native speakers. Our analysis is based on a newly collected dataset with over 12,000 unique annotations from 124 annotators, including information on their native language and English proficiency.