 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark for Deep Information Synthesis
Feb 24, 2026Large language model (LLM)-based agents are increasingly used to solve complex tasks involving tool use, such as web browsing, code execution, and data analysis. However, current evaluation benchmarks do not adequately assess their ability to solve real-world tasks that require synthesizing information from multiple sources and inferring insights beyond simple fact retrieval. To address this, we introduce DEEPSYNTH, a novel benchmark designed to evaluate agents on realistic, time-consuming problems that combine information gathering, synthesis, and structured reasoning to produce insights. DEEPSYNTH contains 120 tasks collected across 7 domains and data sources covering 67 countries. DEEPSYNTH is constructed using a multi-stage data collection pipeline that requires annotators to collect official data sources, create hypotheses, perform manual analysis, and design tasks with verifiable answers. When evaluated on DEEPSYNTH, 11 state-of-the-art LLMs and deep research agents achieve a maximum F1 score of 8.97 and 17.5 on the LLM-judge metric, underscoring the difficulty of the benchmark. Our analysis reveals that current agents struggle with hallucinations and reasoning over large information spaces, highlighting DEEPSYNTH as a crucial benchmark for guiding future research.
Bridging Language Gaps: Enhancing Few-Shot Language Adaptation
Aug 26, 2025The disparity in language resources poses a challenge in multilingual NLP, with high-resource languages benefiting from extensive data, while low-resource languages lack sufficient data for effective training. Our Contrastive Language Alignment with Prompting (CoLAP) method addresses this gap by integrating contrastive learning with cross-lingual representations, facilitating task-specific knowledge transfer from high-resource to lower-resource languages. The primary advantage of our approach is its data efficiency, enabling rapid adaptation to new languages and reducing the need for large labeled datasets. We conduct experiments with multilingual encoder-only and decoder-only language models on natural language understanding tasks, including natural language inference and relation extraction, evaluating performance across both high- and low-resource languages. Our results demonstrate that CoLAP outperforms few-shot cross-lingual transfer baselines and in-context learning, even with limited available data. This effectively narrows the cross-lingual performance gap, contributing to the development of more efficient multilingual NLP techniques.
Language Fusion for Parameter-Efficient Cross-lingual Transfer
Jan 12, 2025Limited availability of multilingual text corpora for training language models often leads to poor performance on downstream tasks due to undertrained representation spaces for languages other than English. This 'under-representation' has motivated recent cross-lingual transfer methods to leverage the English representation space by e.g. mixing English and 'non-English' tokens at the input level or extending model parameters to accommodate new languages. However, these approaches often come at the cost of increased computational complexity. We propose Fusion forLanguage Representations (FLARE) in adapters, a novel method that enhances representation quality and downstream performance for languages other than English while maintaining parameter efficiency. FLARE integrates source and target language representations within low-rank (LoRA) adapters using lightweight linear transformations, maintaining parameter efficiency while improving transfer performance. A series of experiments across representative cross-lingual natural language understanding tasks, including natural language inference, question-answering and sentiment analysis, demonstrate FLARE's effectiveness. FLARE achieves performance improvements of 4.9% for Llama 3.1 and 2.2% for Gemma~2 compared to standard LoRA fine-tuning on question-answering tasks, as measured by the exact match metric.
Native Design Bias: Studying the Impact of English Nativeness on Language Model Performance
Jun 25, 2024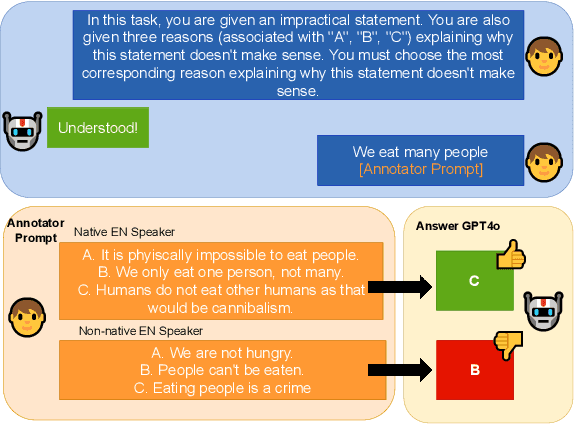
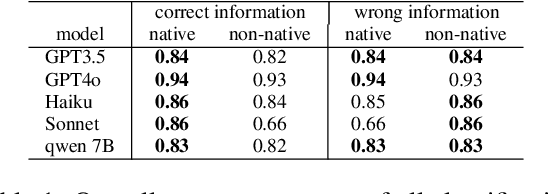
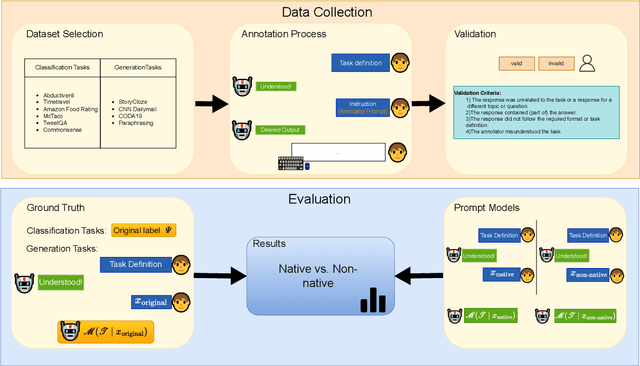
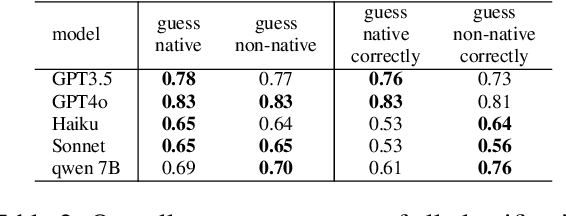
Large Language Models (LLMs) excel at providing information acquired during pretraining on large-scale corpora and following instructions through user prompts. This study investigates whether the quality of LLM responses varies depending on the demographic profile of users. Considering English as the global lingua franca, along with the diversity of its dialects among speakers of different native languages, we explore whether non-native English speakers receive lower-quality or even factually incorrect responses from LLMs more frequently. Our results show that performance discrepancies occur when LLMs are prompted by native versus non-native English speakers and persist when comparing native speakers from Western countries with others. Additionally, we find a strong anchoring effect when the model recognizes or is made aware of the user's nativeness, which further degrades the response quality when interacting with non-native speakers. Our analysis is based on a newly collected dataset with over 12,000 unique annotations from 124 annotators, including information on their native language and English proficiency.
Self-Distillation for Model Stacking Unlocks Cross-Lingual NLU in 200+ Languages
Jun 18, 2024



LLMs have become a go-to solution not just for text generation, but also for natural language understanding (NLU) tasks. Acquiring extensive knowledge through language modeling on web-scale corpora, they excel on English NLU, yet struggle to extend their NLU capabilities to underrepresented languages. In contrast, machine translation models (MT) produce excellent multilingual representations, resulting in strong translation performance even for low-resource languages. MT encoders, however, lack the knowledge necessary for comprehensive NLU that LLMs obtain through language modeling training on immense corpora. In this work, we get the best both worlds by integrating MT encoders directly into LLM backbones via sample-efficient self-distillation. The resulting MT-LLMs preserve the inherent multilingual representational alignment from the MT encoder, allowing lower-resource languages to tap into the rich knowledge embedded in English-centric LLMs. Merging the MT encoder and LLM in a single model, we mitigate the propagation of translation errors and inference overhead of MT decoding inherent to discrete translation-based cross-lingual transfer (e.g., translate-test). Evaluation spanning three prominent NLU tasks and 127 predominantly low-resource languages renders MT-LLMs highly effective in cross-lingual transfer. MT-LLMs substantially and consistently outperform translate-test based on the same MT model, showing that we truly unlock multilingual language understanding for LLMs.
Efficient Information Extraction in Few-Shot Relation Classification through Contrastive Representation Learning
Mar 25, 2024Differentiating relationships between entity pairs with limited labeled instances poses a significant challenge in few-shot relation classification. Representations of textual data extract rich information spanning the domain, entities, and relations. In this paper, we introduce a novel approach to enhance information extraction combining multiple sentence representations and contrastive learning. While representations in relation classification are commonly extracted using entity marker tokens, we argue that substantial information within the internal model representations remains untapped. To address this, we propose aligning multiple sentence representations, such as the [CLS] token, the [MASK] token used in prompting, and entity marker tokens. Our method employs contrastive learning to extract complementary discriminative information from these individual representations. This is particularly relevant in low-resource settings where information is scarce. Leveraging multiple sentence representations is especially effective in distilling discriminative information for relation classification when additional information, like relation descriptions, are not available. We validate the adaptability of our approach, maintaining robust performance in scenarios that include relation descriptions, and showcasing its flexibility to adapt to different resource constraints.
SEER : A Knapsack approach to Exemplar Selection for In-Context HybridQA
Oct 20, 2023



Question answering over hybrid contexts is a complex task, which requires the combination of information extracted from unstructured texts and structured tables in various ways. Recently, In-Context Learning demonstrated significant performance advances for reasoning tasks. In this paradigm, a large language model performs predictions based on a small set of supporting exemplars. The performance of In-Context Learning depends heavily on the selection procedure of the supporting exemplars, particularly in the case of HybridQA, where considering the diversity of reasoning chains and the large size of the hybrid contexts becomes crucial. In this work, we present Selection of ExEmplars for hybrid Reasoning (SEER), a novel method for selecting a set of exemplars that is both representative and diverse. The key novelty of SEER is that it formulates exemplar selection as a Knapsack Integer Linear Program. The Knapsack framework provides the flexibility to incorporate diversity constraints that prioritize exemplars with desirable attributes, and capacity constraints that ensure that the prompt size respects the provided capacity budgets. The effectiveness of SEER is demonstrated on FinQA and TAT-QA, two real-world benchmarks for HybridQA, where it outperforms previous exemplar selection methods.
CORE: A Few-Shot Company Relation Classification Dataset for Robust Domain Adaptation
Oct 18, 2023We introduce CORE, a dataset for few-shot relation classification (RC) focused on company relations and business entities. CORE includes 4,708 instances of 12 relation types with corresponding textual evidence extracted from company Wikipedia pages. Company names and business entities pose a challenge for few-shot RC models due to the rich and diverse information associated with them. For example, a company name may represent the legal entity, products, people, or business divisions depending on the context. Therefore, deriving the relation type between entities is highly dependent on textual context. To evaluate the performance of state-of-the-art RC models on the CORE dataset, we conduct experiments in the few-shot domain adaptation setting. Our results reveal substantial performance gaps, confirming that models trained on different domains struggle to adapt to CORE. Interestingly, we find that models trained on CORE showcase improved out-of-domain performance, which highlights the importance of high-quality data for robust domain adaptation. Specifically, the information richness embedded in business entities allows models to focus on contextual nuances, reducing their reliance on superficial clues such as relation-specific verbs. In addition to the dataset, we provide relevant code snippets to facilitate reproducibility and encourage further research in the field.
Investigating Bias in Multilingual Language Models: Cross-Lingual Transfer of Debiasing Techniques
Oct 16, 2023



This paper investigates the transferability of debiasing techniques across different languages within multilingual models. We examine the applicability of these techniques in English, French, German, and Dutch. Using multilingual BERT (mBERT), we demonstrate that cross-lingual transfer of debiasing techniques is not only feasible but also yields promising results. Surprisingly, our findings reveal no performance disadvantages when applying these techniques to non-English languages. Using translations of the CrowS-Pairs dataset, our analysis identifies SentenceDebias as the best technique across different languages, reducing bias in mBERT by an average of 13%. We also find that debiasing techniques with additional pretraining exhibit enhanced cross-lingual effectiveness for the languages included in the analyses, particularly in lower-resource languages. These novel insights contribute to a deeper understanding of bias mitigation in multilingual language models and provide practical guidance for debiasing techniques in different language contexts.