 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM2Vec-Gen: Generative Embeddings from Large Language Models
Mar 11, 2026LLM-based text embedders typically encode the semantic content of their input. However, embedding tasks require mapping diverse inputs to similar outputs. Typically, this input-output is addressed by training embedding models with paired data using contrastive learning. In this work, we propose a novel self-supervised approach, LLM2Vec-Gen, which adopts a different paradigm: rather than encoding the input, we learn to represent the model's potential response. Specifically, we add trainable special tokens to the LLM's vocabulary, append them to input, and optimize them to represent the LLM's response in a fixed-length sequence. Training is guided by the LLM's own completion for the query, along with an unsupervised embedding teacher that provides distillation targets. This formulation helps to bridge the input-output gap and transfers LLM capabilities such as safety alignment and reasoning to embedding tasks. Crucially, the LLM backbone remains frozen and training requires only unlabeled queries. LLM2Vec-Gen achieves state-of-the-art self-supervised performance on the Massive Text Embedding Benchmark (MTEB), improving by 9.3% over the best unsupervised embedding teacher. We also observe up to 43.2% reduction in harmful content retrieval and 29.3% improvement in reasoning capabilities for embedding tasks. Finally, the learned embeddings are interpretable and can be decoded into text to reveal their semantic content.
ReCoVeR the Target Language: Language Steering without Sacrificing Task Performance
Sep 18, 2025


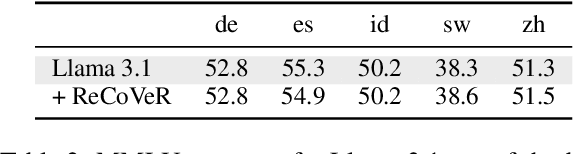
As they become increasingly multilingual, Large Language Models (LLMs) exhibit more language confusion, i.e., they tend to generate answers in a language different from the language of the prompt or the answer language explicitly requested by the user. In this work, we propose ReCoVeR (REducing language COnfusion in VEctor Representations), a novel lightweight approach for reducing language confusion based on language-specific steering vectors. We first isolate language vectors with the help of multi-parallel corpus and then effectively leverage those vectors for effective LLM steering via fixed (i.e., unsupervised) as well as trainable steering functions. Our extensive evaluation, encompassing three benchmarks and 18 languages, shows that ReCoVeR effectively mitigates language confusion in both monolingual and cross-lingual setups while at the same time -- and in contrast to prior language steering methods -- retaining task performance. Our data code is available at https://github.com/hSterz/recover.
mSTEB: Massively Multilingual Evaluation of LLMs on Speech and Text Tasks
Jun 10, 2025Large Language models (LLMs) have demonstrated impressive performance on a wide range of tasks, including in multimodal settings such as speech. However, their evaluation is often limited to English and a few high-resource languages. For low-resource languages, there is no standardized evaluation benchmark. In this paper, we address this gap by introducing mSTEB, a new benchmark to evaluate the performance of LLMs on a wide range of tasks covering language identification, text classification, question answering, and translation tasks on both speech and text modalities. We evaluated the performance of leading LLMs such as Gemini 2.0 Flash and GPT-4o (Audio) and state-of-the-art open models such as Qwen 2 Audio and Gemma 3 27B. Our evaluation shows a wide gap in performance between high-resource and low-resource languages, especially for languages spoken in Africa and Americas/Oceania. Our findings show that more investment is needed to address their under-representation in LLMs coverage.
On the Potential of Large Language Models to Solve Semantics-Aware Process Mining Tasks
Apr 29, 2025


Large language models (LLMs) have shown to be valuable tools for tackling process mining tasks. Existing studies report on their capability to support various data-driven process analyses and even, to some extent, that they are able to reason about how processes work. This reasoning ability suggests that there is potential for LLMs to tackle semantics-aware process mining tasks, which are tasks that rely on an understanding of the meaning of activities and their relationships. Examples of these include process discovery, where the meaning of activities can indicate their dependency, whereas in anomaly detection the meaning can be used to recognize process behavior that is abnormal. In this paper, we systematically explore the capabilities of LLMs for such tasks. Unlike prior work, which largely evaluates LLMs in their default state, we investigate their utility through both in-context learning and supervised fine-tuning. Concretely, we define five process mining tasks requiring semantic understanding and provide extensive benchmarking datasets for evaluation. Our experiments reveal that while LLMs struggle with challenging process mining tasks when used out of the box or with minimal in-context examples, they achieve strong performance when fine-tuned for these tasks across a broad range of process types and industries.
MVL-SIB: A Massively Multilingual Vision-Language Benchmark for Cross-Modal Topical Matching
Feb 18, 2025



Existing multilingual vision-language (VL) benchmarks often only cover a handful of languages. Consequently, evaluations of large vision-language models (LVLMs) predominantly target high-resource languages, underscoring the need for evaluation data for low-resource languages. To address this limitation, we introduce MVL-SIB, a massively multilingual vision-language benchmark that evaluates both cross-modal and text-only topical matching across 205 languages -- over 100 more than the most multilingual existing VL benchmarks encompass. We then benchmark a range of of open-weight LVLMs together with GPT-4o(-mini) on MVL-SIB. Our results reveal that LVLMs struggle in cross-modal topic matching in lower-resource languages, performing no better than chance on languages like N'Koo. Our analysis further reveals that VL support in LVLMs declines disproportionately relative to textual support for lower-resource languages, as evidenced by comparison of cross-modal and text-only topical matching performance. We further observe that open-weight LVLMs do not benefit from representing a topic with more than one image, suggesting that these models are not yet fully effective at handling multi-image tasks. By correlating performance on MVL-SIB with other multilingual VL benchmarks, we highlight that MVL-SIB serves as a comprehensive probe of multilingual VL understanding in LVLMs.
Fleurs-SLU: A Massively Multilingual Benchmark for Spoken Language Understanding
Jan 10, 2025While recent multilingual automatic speech recognition models claim to support thousands of languages, ASR for low-resource languages remains highly unreliable due to limited bimodal speech and text training data. Better multilingual spoken language understanding (SLU) can strengthen massively the robustness of multilingual ASR by levering language semantics to compensate for scarce training data, such as disambiguating utterances via context or exploiting semantic similarities across languages. Even more so, SLU is indispensable for inclusive speech technology in roughly half of all living languages that lack a formal writing system. However, the evaluation of multilingual SLU remains limited to shallower tasks such as intent classification or language identification. To address this, we present Fleurs-SLU, a multilingual SLU benchmark that encompasses topical speech classification in 102 languages and multiple-choice question answering through listening comprehension in 92 languages. We extensively evaluate both end-to-end speech classification models and cascaded systems that combine speech-to-text transcription with subsequent classification by large language models on Fleurs-SLU. Our results show that cascaded systems exhibit greater robustness in multilingual SLU tasks, though speech encoders can achieve competitive performance in topical speech classification when appropriately pre-trained. We further find a strong correlation between robust multilingual ASR, effective speech-to-text translation, and strong multilingual SLU, highlighting the mutual benefits between acoustic and semantic speech representations.
Evaluating the Ability of LLMs to Solve Semantics-Aware Process Mining Tasks
Jul 02, 2024



The process mining community has recently recognized the potential of large language models (LLMs) for tackling various process mining tasks. Initial studies report the capability of LLMs to support process analysis and even, to some extent, that they are able to reason about how processes work. This latter property suggests that LLMs could also be used to tackle process mining tasks that benefit from an understanding of process behavior. Examples of such tasks include (semantic) anomaly detection and next activity prediction, which both involve considerations of the meaning of activities and their inter-relations. In this paper, we investigate the capabilities of LLMs to tackle such semantics-aware process mining tasks. Furthermore, whereas most works on the intersection of LLMs and process mining only focus on testing these models out of the box, we provide a more principled investigation of the utility of LLMs for process mining, including their ability to obtain process mining knowledge post-hoc by means of in-context learning and supervised fine-tuning. Concretely, we define three process mining tasks that benefit from an understanding of process semantics and provide extensive benchmarking datasets for each of them. Our evaluation experiments reveal that (1) LLMs fail to solve challenging process mining tasks out of the box and when provided only a handful of in-context examples, (2) but they yield strong performance when fine-tuned for these tasks, consistently surpassing smaller, encoder-based language models.
Self-Distillation for Model Stacking Unlocks Cross-Lingual NLU in 200+ Languages
Jun 18, 2024



LLMs have become a go-to solution not just for text generation, but also for natural language understanding (NLU) tasks. Acquiring extensive knowledge through language modeling on web-scale corpora, they excel on English NLU, yet struggle to extend their NLU capabilities to underrepresented languages. In contrast, machine translation models (MT) produce excellent multilingual representations, resulting in strong translation performance even for low-resource languages. MT encoders, however, lack the knowledge necessary for comprehensive NLU that LLMs obtain through language modeling training on immense corpora. In this work, we get the best both worlds by integrating MT encoders directly into LLM backbones via sample-efficient self-distillation. The resulting MT-LLMs preserve the inherent multilingual representational alignment from the MT encoder, allowing lower-resource languages to tap into the rich knowledge embedded in English-centric LLMs. Merging the MT encoder and LLM in a single model, we mitigate the propagation of translation errors and inference overhead of MT decoding inherent to discrete translation-based cross-lingual transfer (e.g., translate-test). Evaluation spanning three prominent NLU tasks and 127 predominantly low-resource languages renders MT-LLMs highly effective in cross-lingual transfer. MT-LLMs substantially and consistently outperform translate-test based on the same MT model, showing that we truly unlock multilingual language understanding for LLMs.
News Without Borders: Domain Adaptation of Multilingual Sentence Embeddings for Cross-lingual News Recommendation
Jun 18, 2024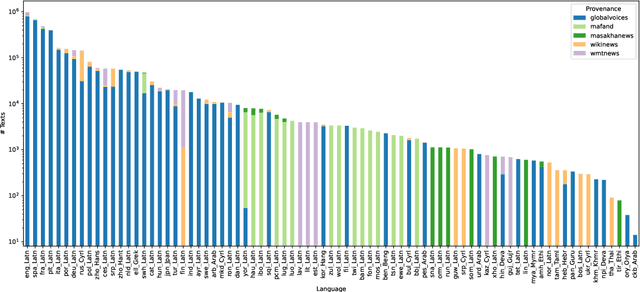
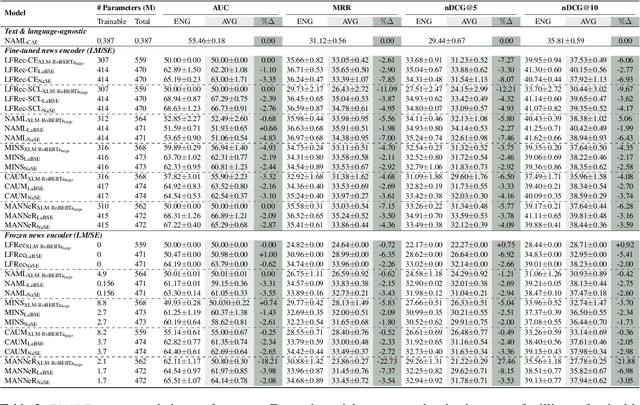
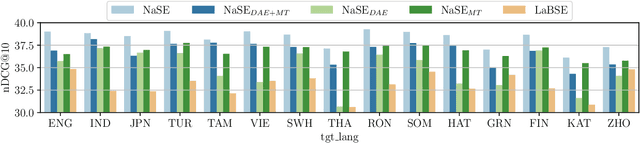
Rapidly growing numbers of multilingual news consumers pose an increasing challenge to news recommender systems in terms of providing customized recommendations. First, existing neural news recommenders, even when powered by multilingual language models (LMs), suffer substantial performance losses in zero-shot cross-lingual transfer (ZS-XLT). Second, the current paradigm of fine-tuning the backbone LM of a neural recommender on task-specific data is computationally expensive and infeasible in few-shot recommendation and cold-start setups, where data is scarce or completely unavailable. In this work, we propose a news-adapted sentence encoder (NaSE), domain-specialized from a pretrained massively multilingual sentence encoder (SE). To this end, we construct and leverage PolyNews and PolyNewsParallel, two multilingual news-specific corpora. With the news-adapted multilingual SE in place, we test the effectiveness of (i.e., question the need for) supervised fine-tuning for news recommendation, and propose a simple and strong baseline based on (i) frozen NaSE embeddings and (ii) late click-behavior fusion. We show that NaSE achieves state-of-the-art performance in ZS-XLT in true cold-start and few-shot news recommendation.
Knowledge Distillation vs. Pretraining from Scratch under a Fixed (Computation) Budget
Apr 30, 2024

Compared to standard language model (LM) pretraining (i.e., from scratch), Knowledge Distillation (KD) entails an additional forward pass through a teacher model that is typically substantially larger than the target student model. As such, KD in LM pretraining materially slows down throughput of pretraining instances vis-a-vis pretraining from scratch. Scaling laws of LM pretraining suggest that smaller models can close the gap to larger counterparts if trained on more data (i.e., processing more tokens)-and under a fixed computation budget, smaller models are able be process more data than larger models. We thus hypothesize that KD might, in fact, be suboptimal to pretraining from scratch for obtaining smaller LMs, when appropriately accounting for the compute budget. To test this, we compare pretraining from scratch against several KD strategies for masked language modeling (MLM) in a fair experimental setup, with respect to amount of computation as well as pretraining data. Downstream results on GLUE, however, do not confirm our hypothesis: while pretraining from scratch performs comparably to ordinary KD under a fixed computation budget, more sophisticated KD strategies, namely TinyBERT (Jiao et al., 2020) and MiniLM (Wang et al., 2023), outperform it by a notable margin. We further find that KD yields larger gains over pretraining from scratch when the data must be repeated under the fixed computation budget.