 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom If-Statements to ML Pipelines: Revisiting Bias in Code-Generation
Apr 23, 2026Prior work evaluates code generation bias primarily through simple conditional statements, which represent only a narrow slice of real-world programming and reveal solely overt, explicitly encoded bias. We demonstrate that this approach dramatically underestimates bias in practice by examining a more realistic task: generating machine learning (ML) pipelines. Testing both code-specialized and general-instruction large language models, we find that generated pipelines exhibit significant bias during feature selection. Sensitive attributes appear in 87.7% of cases on average, despite models demonstrably excluding irrelevant features (e.g., including "race" while dropping "favorite color" for credit scoring). This bias is substantially more prevalent than that captured by conditional statements, where sensitive attributes appear in only 59.2% of cases. These findings are robust across prompt mitigation strategies, varying numbers of attributes, and different pipeline difficulty levels. Our results challenge simple conditionals as valid proxies for bias evaluation and suggest current benchmarks underestimate bias risk in practical deployments.
Greater accessibility can amplify discrimination in generative AI
Mar 23, 2026Hundreds of millions of people rely on large language models (LLMs) for education, work, and even healthcare. Yet these models are known to reproduce and amplify social biases present in their training data. Moreover, text-based interfaces remain a barrier for many, for example, users with limited literacy, motor impairments, or mobile-only devices. Voice interaction promises to expand accessibility, but unlike text, speech carries identity cues that users cannot easily mask, raising concerns about whether accessibility gains may come at the cost of equitable treatment. Here we show that audio-enabled LLMs exhibit systematic gender discrimination, shifting responses toward gender-stereotyped adjectives and occupations solely on the basis of speaker voice, and amplifying bias beyond that observed in text-based interaction. Thus, voice interfaces do not merely extend text models to a new modality but introduce distinct bias mechanisms tied to paralinguistic cues. Complementary survey evidence ($n=1,000$) shows that infrequent chatbot users are most hesitant to undisclosed attribute inference and most likely to disengage when such practices are revealed. To demonstrate a potential mitigation strategy, we show that pitch manipulation can systematically regulate gender-discriminatory outputs. Overall, our findings reveal a critical tension in AI development: efforts to expand accessibility through voice interfaces simultaneously create new pathways for discrimination, demanding that fairness and accessibility be addressed in tandem.
Meenz bleibt Meenz, but Large Language Models Do Not Speak Its Dialect
Feb 18, 2026Meenzerisch, the dialect spoken in the German city of Mainz, is also the traditional language of the Mainz carnival, a yearly celebration well known throughout Germany. However, Meenzerisch is on the verge of dying out-a fate it shares with many other German dialects. Natural language processing (NLP) has the potential to help with the preservation and revival efforts of languages and dialects. However, so far no NLP research has looked at Meenzerisch. This work presents the first research in the field of NLP that is explicitly focused on the dialect of Mainz. We introduce a digital dictionary-an NLP-ready dataset derived from an existing resource (Schramm, 1966)-to support researchers in modeling and benchmarking the language. It contains 2,351 words in the dialect paired with their meanings described in Standard German. We then use this dataset to answer the following research questions: (1) Can state-of-the-art large language models (LLMs) generate definitions for dialect words? (2) Can LLMs generate words in Meenzerisch, given their definitions? Our experiments show that LLMs can do neither: the best model for definitions reaches only 6.27% accuracy and the best word generation model's accuracy is 1.51%. We then conduct two additional experiments in order to see if accuracy is improved by few-shot learning and by extracting rules from the training set, which are then passed to the LLM. While those approaches are able to improve the results, accuracy remains below 10%. This highlights that additional resources and an intensification of research efforts focused on German dialects are desperately needed.
JGU Mainz's Submission to the WMT25 Shared Task on LLMs with Limited Resources for Slavic Languages: MT and QA
Sep 26, 2025This paper presents the JGU Mainz submission to the WMT25 Shared Task on LLMs with Limited Resources for Slavic Languages: Machine Translation and Question Answering, focusing on Ukrainian, Upper Sorbian, and Lower Sorbian. For each language, we jointly fine-tune a Qwen2.5-3B-Instruct model for both tasks with parameter-efficient finetuning. Our pipeline integrates additional translation and multiple-choice question answering (QA) data. For Ukrainian QA, we further use retrieval-augmented generation. We also apply ensembling for QA in Upper and Lower Sorbian. Experiments show that our models outperform the baseline on both tasks.
Mind the Gap: A Closer Look at Tokenization for Multiple-Choice Question Answering with LLMs
Sep 18, 2025When evaluating large language models (LLMs) with multiple-choice question answering (MCQA), it is common to end the prompt with the string "Answer:" to facilitate automated answer extraction via next-token probabilities. However, there is no consensus on how to tokenize the space following the colon, often overlooked as a trivial choice. In this paper, we uncover accuracy differences of up to 11% due to this (seemingly irrelevant) tokenization variation as well as reshuffled model rankings, raising concerns about the reliability of LLM comparisons in prior work. Surprisingly, we are able to recommend one specific strategy -- tokenizing the space together with the answer letter -- as we observe consistent and statistically significant performance improvements. Additionally, it improves model calibration, enhancing the reliability of the model's confidence estimates. Our findings underscore the importance of careful evaluation design and highlight the need for standardized, transparent evaluation protocols to ensure reliable and comparable results.
Large Language Models Discriminate Against Speakers of German Dialects
Sep 17, 2025Dialects represent a significant component of human culture and are found across all regions of the world. In Germany, more than 40% of the population speaks a regional dialect (Adler and Hansen, 2022). However, despite cultural importance, individuals speaking dialects often face negative societal stereotypes. We examine whether such stereotypes are mirrored by large language models (LLMs). We draw on the sociolinguistic literature on dialect perception to analyze traits commonly associated with dialect speakers. Based on these traits, we assess the dialect naming bias and dialect usage bias expressed by LLMs in two tasks: an association task and a decision task. To assess a model's dialect usage bias, we construct a novel evaluation corpus that pairs sentences from seven regional German dialects (e.g., Alemannic and Bavarian) with their standard German counterparts. We find that: (1) in the association task, all evaluated LLMs exhibit significant dialect naming and dialect usage bias against German dialect speakers, reflected in negative adjective associations; (2) all models reproduce these dialect naming and dialect usage biases in their decision making; and (3) contrary to prior work showing minimal bias with explicit demographic mentions, we find that explicitly labeling linguistic demographics--German dialect speakers--amplifies bias more than implicit cues like dialect usage.
Multi3Hate: Multimodal, Multilingual, and Multicultural Hate Speech Detection with Vision-Language Models
Nov 06, 2024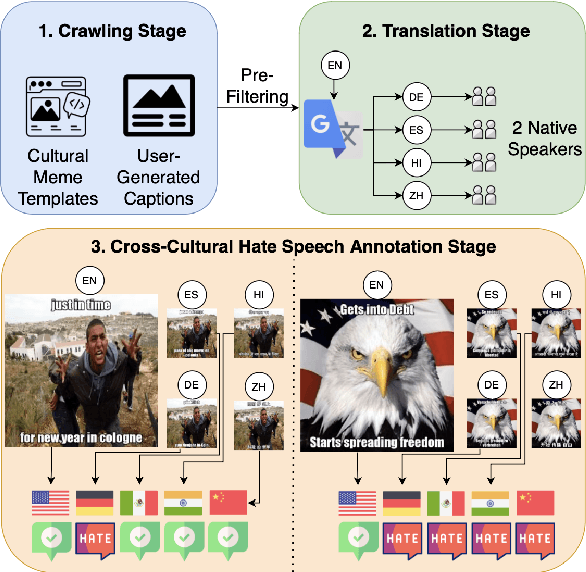

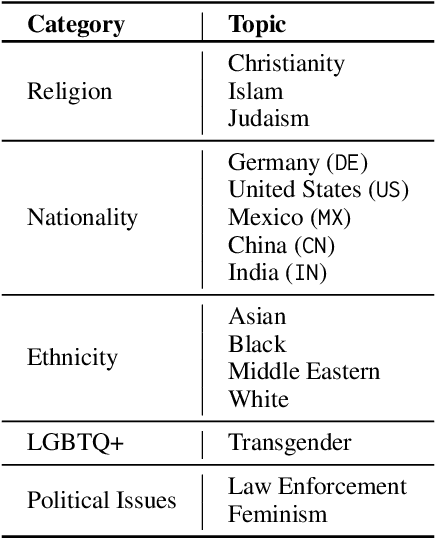

Warning: this paper contains content that may be offensive or upsetting Hate speech moderation on global platforms poses unique challenges due to the multimodal and multilingual nature of content, along with the varying cultural perceptions. How well do current vision-language models (VLMs) navigate these nuances? To investigate this, we create the first multimodal and multilingual parallel hate speech dataset, annotated by a multicultural set of annotators, called Multi3Hate. It contains 300 parallel meme samples across 5 languages: English, German, Spanish, Hindi, and Mandarin. We demonstrate that cultural background significantly affects multimodal hate speech annotation in our dataset. The average pairwise agreement among countries is just 74%, significantly lower than that of randomly selected annotator groups. Our qualitative analysis indicates that the lowest pairwise label agreement-only 67% between the USA and India-can be attributed to cultural factors. We then conduct experiments with 5 large VLMs in a zero-shot setting, finding that these models align more closely with annotations from the US than with those from other cultures, even when the memes and prompts are presented in the dominant language of the other culture. Code and dataset are available at https://github.com/MinhDucBui/Multi3Hate.
The Trade-off between Performance, Efficiency, and Fairness in Adapter Modules for Text Classification
May 03, 2024Current natural language processing (NLP) research tends to focus on only one or, less frequently, two dimensions - e.g., performance, privacy, fairness, or efficiency - at a time, which may lead to suboptimal conclusions and often overlooking the broader goal of achieving trustworthy NLP. Work on adapter modules (Houlsby et al., 2019; Hu et al., 2021) focuses on improving performance and efficiency, with no investigation of unintended consequences on other aspects such as fairness. To address this gap, we conduct experiments on three text classification datasets by either (1) finetuning all parameters or (2) using adapter modules. Regarding performance and efficiency, we confirm prior findings that the accuracy of adapter-enhanced models is roughly on par with that of fully finetuned models, while training time is substantially reduced. Regarding fairness, we show that adapter modules result in mixed fairness across sensitive groups. Further investigation reveals that, when the standard fine-tuned model exhibits limited biases, adapter modules typically do not introduce extra bias. On the other hand, when the finetuned model exhibits increased bias, the impact of adapter modules on bias becomes more unpredictable, introducing the risk of significantly magnifying these biases for certain groups. Our findings highlight the need for a case-by-case evaluation rather than a one-size-fits-all judgment.
Knowledge Distillation vs. Pretraining from Scratch under a Fixed (Computation) Budget
Apr 30, 2024

Compared to standard language model (LM) pretraining (i.e., from scratch), Knowledge Distillation (KD) entails an additional forward pass through a teacher model that is typically substantially larger than the target student model. As such, KD in LM pretraining materially slows down throughput of pretraining instances vis-a-vis pretraining from scratch. Scaling laws of LM pretraining suggest that smaller models can close the gap to larger counterparts if trained on more data (i.e., processing more tokens)-and under a fixed computation budget, smaller models are able be process more data than larger models. We thus hypothesize that KD might, in fact, be suboptimal to pretraining from scratch for obtaining smaller LMs, when appropriately accounting for the compute budget. To test this, we compare pretraining from scratch against several KD strategies for masked language modeling (MLM) in a fair experimental setup, with respect to amount of computation as well as pretraining data. Downstream results on GLUE, however, do not confirm our hypothesis: while pretraining from scratch performs comparably to ordinary KD under a fixed computation budget, more sophisticated KD strategies, namely TinyBERT (Jiao et al., 2020) and MiniLM (Wang et al., 2023), outperform it by a notable margin. We further find that KD yields larger gains over pretraining from scratch when the data must be repeated under the fixed computation budget.