 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeenz bleibt Meenz, but Large Language Models Do Not Speak Its Dialect
Feb 18, 2026Meenzerisch, the dialect spoken in the German city of Mainz, is also the traditional language of the Mainz carnival, a yearly celebration well known throughout Germany. However, Meenzerisch is on the verge of dying out-a fate it shares with many other German dialects. Natural language processing (NLP) has the potential to help with the preservation and revival efforts of languages and dialects. However, so far no NLP research has looked at Meenzerisch. This work presents the first research in the field of NLP that is explicitly focused on the dialect of Mainz. We introduce a digital dictionary-an NLP-ready dataset derived from an existing resource (Schramm, 1966)-to support researchers in modeling and benchmarking the language. It contains 2,351 words in the dialect paired with their meanings described in Standard German. We then use this dataset to answer the following research questions: (1) Can state-of-the-art large language models (LLMs) generate definitions for dialect words? (2) Can LLMs generate words in Meenzerisch, given their definitions? Our experiments show that LLMs can do neither: the best model for definitions reaches only 6.27% accuracy and the best word generation model's accuracy is 1.51%. We then conduct two additional experiments in order to see if accuracy is improved by few-shot learning and by extracting rules from the training set, which are then passed to the LLM. While those approaches are able to improve the results, accuracy remains below 10%. This highlights that additional resources and an intensification of research efforts focused on German dialects are desperately needed.
Mitigating Label Length Bias in Large Language Models
Nov 18, 2025



Large language models (LLMs) are powerful zero- and few-shot learners. However, when predicting over a set of candidate options, LLMs suffer from label biases, and existing calibration methods overlook biases arising from multi-token class labels. We tackle an issue we call label length bias, where labels of different lengths are treated inconsistently, even after standard length normalization. To mitigate it, we propose normalized contextual calibration (NCC), an effective method that normalizes and calibrates predictions at the full-label level. NCC achieves statistically significant improvements over prior approaches across multiple datasets and models, with gains of up to 10% F1. Moreover, NCC extends bias mitigation to broader tasks such as multiple-choice question answering. Our analysis shows that, when combined with in-context learning, NCC is less sensitive to few-shot example selection, requires fewer examples for competitive performance, and produces more reliable confidence estimates. These findings highlight the importance of mitigating full-label biases to improve the performance and robustness of LLM-based methods, particularly in real-world applications where class labels naturally consist of multiple tokens.
JGU Mainz's Submission to the WMT25 Shared Task on LLMs with Limited Resources for Slavic Languages: MT and QA
Sep 26, 2025This paper presents the JGU Mainz submission to the WMT25 Shared Task on LLMs with Limited Resources for Slavic Languages: Machine Translation and Question Answering, focusing on Ukrainian, Upper Sorbian, and Lower Sorbian. For each language, we jointly fine-tune a Qwen2.5-3B-Instruct model for both tasks with parameter-efficient finetuning. Our pipeline integrates additional translation and multiple-choice question answering (QA) data. For Ukrainian QA, we further use retrieval-augmented generation. We also apply ensembling for QA in Upper and Lower Sorbian. Experiments show that our models outperform the baseline on both tasks.
Mind the Gap: A Closer Look at Tokenization for Multiple-Choice Question Answering with LLMs
Sep 18, 2025When evaluating large language models (LLMs) with multiple-choice question answering (MCQA), it is common to end the prompt with the string "Answer:" to facilitate automated answer extraction via next-token probabilities. However, there is no consensus on how to tokenize the space following the colon, often overlooked as a trivial choice. In this paper, we uncover accuracy differences of up to 11% due to this (seemingly irrelevant) tokenization variation as well as reshuffled model rankings, raising concerns about the reliability of LLM comparisons in prior work. Surprisingly, we are able to recommend one specific strategy -- tokenizing the space together with the answer letter -- as we observe consistent and statistically significant performance improvements. Additionally, it improves model calibration, enhancing the reliability of the model's confidence estimates. Our findings underscore the importance of careful evaluation design and highlight the need for standardized, transparent evaluation protocols to ensure reliable and comparable results.
Large Language Models Discriminate Against Speakers of German Dialects
Sep 17, 2025Dialects represent a significant component of human culture and are found across all regions of the world. In Germany, more than 40% of the population speaks a regional dialect (Adler and Hansen, 2022). However, despite cultural importance, individuals speaking dialects often face negative societal stereotypes. We examine whether such stereotypes are mirrored by large language models (LLMs). We draw on the sociolinguistic literature on dialect perception to analyze traits commonly associated with dialect speakers. Based on these traits, we assess the dialect naming bias and dialect usage bias expressed by LLMs in two tasks: an association task and a decision task. To assess a model's dialect usage bias, we construct a novel evaluation corpus that pairs sentences from seven regional German dialects (e.g., Alemannic and Bavarian) with their standard German counterparts. We find that: (1) in the association task, all evaluated LLMs exhibit significant dialect naming and dialect usage bias against German dialect speakers, reflected in negative adjective associations; (2) all models reproduce these dialect naming and dialect usage biases in their decision making; and (3) contrary to prior work showing minimal bias with explicit demographic mentions, we find that explicitly labeling linguistic demographics--German dialect speakers--amplifies bias more than implicit cues like dialect usage.
Improving Low-Resource Morphological Inflection via Self-Supervised Objectives
Jun 05, 2025Self-supervised objectives have driven major advances in NLP by leveraging large-scale unlabeled data, but such resources are scarce for many of the world's languages. Surprisingly, they have not been explored much for character-level tasks, where smaller amounts of data have the potential to be beneficial. We investigate the effectiveness of self-supervised auxiliary tasks for morphological inflection -- a character-level task highly relevant for language documentation -- in extremely low-resource settings, training encoder-decoder transformers for 19 languages and 13 auxiliary objectives. Autoencoding yields the best performance when unlabeled data is very limited, while character masked language modeling (CMLM) becomes more effective as data availability increases. Though objectives with stronger inductive biases influence model predictions intuitively, they rarely outperform standard CMLM. However, sampling masks based on known morpheme boundaries consistently improves performance, highlighting a promising direction for low-resource morphological modeling.
Implicitly Aligning Humans and Autonomous Agents through Shared Task Abstractions
May 07, 2025In collaborative tasks, autonomous agents fall short of humans in their capability to quickly adapt to new and unfamiliar teammates. We posit that a limiting factor for zero-shot coordination is the lack of shared task abstractions, a mechanism humans rely on to implicitly align with teammates. To address this gap, we introduce HA$^2$: Hierarchical Ad Hoc Agents, a framework leveraging hierarchical reinforcement learning to mimic the structured approach humans use in collaboration. We evaluate HA$^2$ in the Overcooked environment, demonstrating statistically significant improvement over existing baselines when paired with both unseen agents and humans, providing better resilience to environmental shifts, and outperforming all state-of-the-art methods.
Untangling the Influence of Typology, Data and Model Architecture on Ranking Transfer Languages for Cross-Lingual POS Tagging
Mar 25, 2025Cross-lingual transfer learning is an invaluable tool for overcoming data scarcity, yet selecting a suitable transfer language remains a challenge. The precise roles of linguistic typology, training data, and model architecture in transfer language choice are not fully understood. We take a holistic approach, examining how both dataset-specific and fine-grained typological features influence transfer language selection for part-of-speech tagging, considering two different sources for morphosyntactic features. While previous work examines these dynamics in the context of bilingual biLSTMS, we extend our analysis to a more modern transfer learning pipeline: zero-shot prediction with pretrained multilingual models. We train a series of transfer language ranking systems and examine how different feature inputs influence ranker performance across architectures. Word overlap, type-token ratio, and genealogical distance emerge as top features across all architectures. Our findings reveal that a combination of typological and dataset-dependent features leads to the best rankings, and that good performance can be obtained with either feature group on its own.
Corrective In-Context Learning: Evaluating Self-Correction in Large Language Models
Mar 20, 2025In-context learning (ICL) has transformed the use of large language models (LLMs) for NLP tasks, enabling few-shot learning by conditioning on labeled examples without finetuning. Despite its effectiveness, ICL is prone to errors, especially for challenging examples. With the goal of improving the performance of ICL, we propose corrective in-context learning (CICL), an approach that incorporates a model's incorrect predictions alongside ground truth corrections into the prompt, aiming to enhance classification accuracy through self-correction. However, contrary to our hypothesis, extensive experiments on text classification tasks demonstrate that CICL consistently underperforms standard ICL, with performance degrading as the proportion of corrections in the prompt increases. Our findings indicate that CICL introduces confusion by disrupting the model's task understanding, rather than refining its predictions. Additionally, we observe that presenting harder examples in standard ICL does not improve performance, suggesting that example difficulty alone may not be a reliable criterion for effective selection. By presenting these negative results, we provide important insights into the limitations of self-corrective mechanisms in LLMs and offer directions for future research.
CLIX: Cross-Lingual Explanations of Idiomatic Expressions
Jan 06, 2025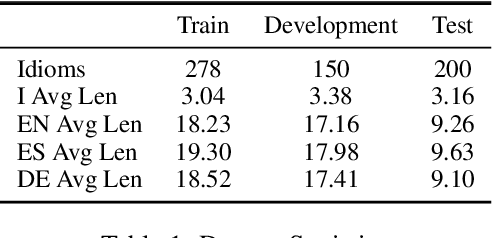
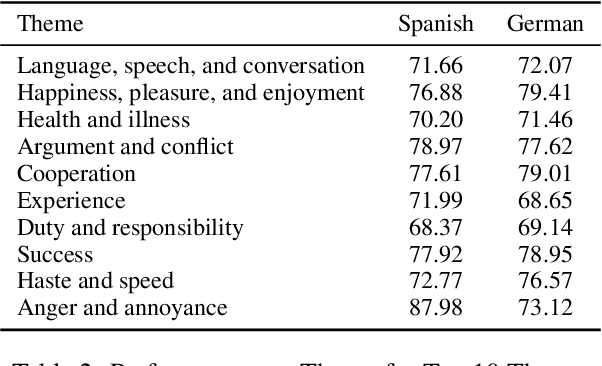
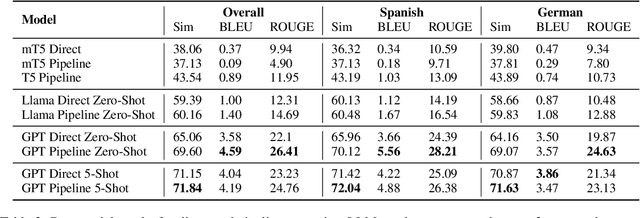
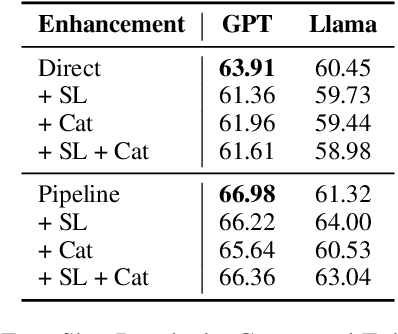
Automated definition generation systems have been proposed to support vocabulary expansion for language learners. The main barrier to the success of these systems is that learners often struggle to understand definitions due to the presence of potentially unfamiliar words and grammar, particularly when non-standard language is involved. To address these challenges, we propose CLIX, the task of Cross-Lingual explanations of Idiomatic eXpressions. We explore the capabilities of current NLP models for this task, and observe that while it remains challenging, large language models show promise. Finally, we perform a detailed error analysis to highlight the key challenges that need to be addressed before we can reliably incorporate these systems into educational tools.