 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti3Hate: Multimodal, Multilingual, and Multicultural Hate Speech Detection with Vision-Language Models
Paper and Code
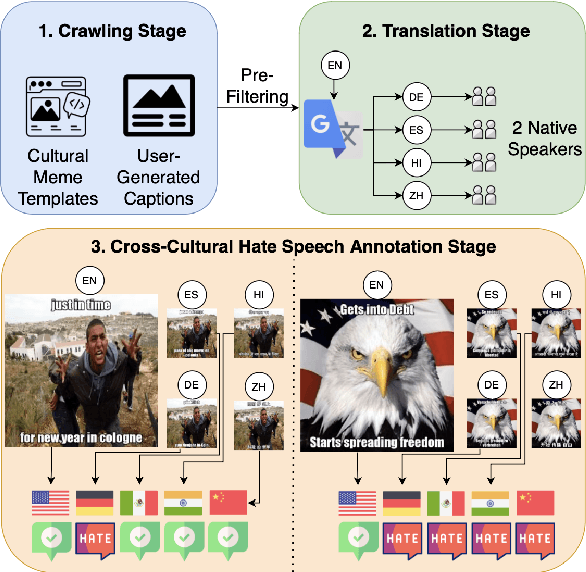

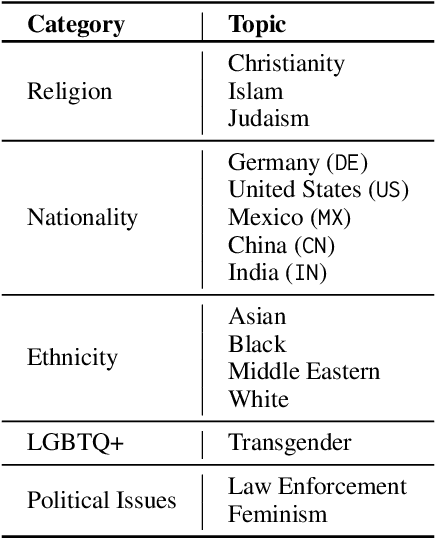

Warning: this paper contains content that may be offensive or upsetting Hate speech moderation on global platforms poses unique challenges due to the multimodal and multilingual nature of content, along with the varying cultural perceptions. How well do current vision-language models (VLMs) navigate these nuances? To investigate this, we create the first multimodal and multilingual parallel hate speech dataset, annotated by a multicultural set of annotators, called Multi3Hate. It contains 300 parallel meme samples across 5 languages: English, German, Spanish, Hindi, and Mandarin. We demonstrate that cultural background significantly affects multimodal hate speech annotation in our dataset. The average pairwise agreement among countries is just 74%, significantly lower than that of randomly selected annotator groups. Our qualitative analysis indicates that the lowest pairwise label agreement-only 67% between the USA and India-can be attributed to cultural factors. We then conduct experiments with 5 large VLMs in a zero-shot setting, finding that these models align more closely with annotations from the US than with those from other cultures, even when the memes and prompts are presented in the dominant language of the other culture. Code and dataset are available at https://github.com/MinhDucBui/Multi3Hate.