 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Scripts and Formats on LLM Numeracy
Jan 21, 2026Large language models (LLMs) have achieved impressive proficiency in basic arithmetic, rivaling human-level performance on standard numerical tasks. However, little attention has been given to how these models perform when numerical expressions deviate from the prevailing conventions present in their training corpora. In this work, we investigate numerical reasoning across a wide range of numeral scripts and formats. We show that LLM accuracy drops substantially when numerical inputs are rendered in underrepresented scripts or formats, despite the underlying mathematical reasoning being identical. We further demonstrate that targeted prompting strategies, such as few-shot prompting and explicit numeral mapping, can greatly narrow this gap. Our findings highlight an overlooked challenge in multilingual numerical reasoning and provide actionable insights for working with LLMs to reliably interpret, manipulate, and generate numbers across diverse numeral scripts and formatting styles.
Improving Low-Resource Morphological Inflection via Self-Supervised Objectives
Jun 05, 2025Self-supervised objectives have driven major advances in NLP by leveraging large-scale unlabeled data, but such resources are scarce for many of the world's languages. Surprisingly, they have not been explored much for character-level tasks, where smaller amounts of data have the potential to be beneficial. We investigate the effectiveness of self-supervised auxiliary tasks for morphological inflection -- a character-level task highly relevant for language documentation -- in extremely low-resource settings, training encoder-decoder transformers for 19 languages and 13 auxiliary objectives. Autoencoding yields the best performance when unlabeled data is very limited, while character masked language modeling (CMLM) becomes more effective as data availability increases. Though objectives with stronger inductive biases influence model predictions intuitively, they rarely outperform standard CMLM. However, sampling masks based on known morpheme boundaries consistently improves performance, highlighting a promising direction for low-resource morphological modeling.
An Investigation of Noise in Morphological Inflection
May 26, 2023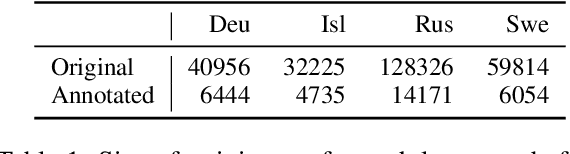
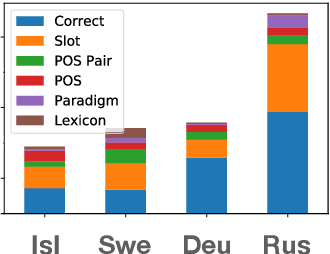
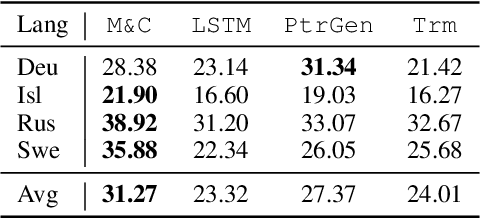
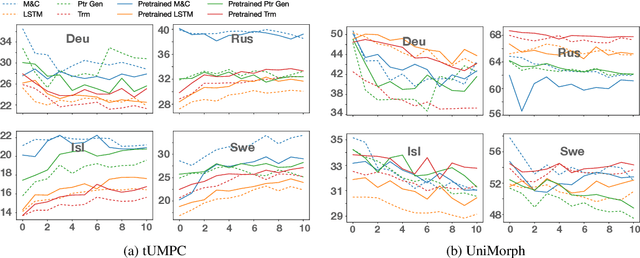
With a growing focus on morphological inflection systems for languages where high-quality data is scarce, training data noise is a serious but so far largely ignored concern. We aim at closing this gap by investigating the types of noise encountered within a pipeline for truly unsupervised morphological paradigm completion and its impact on morphological inflection systems: First, we propose an error taxonomy and annotation pipeline for inflection training data. Then, we compare the effect of different types of noise on multiple state-of-the-art inflection models. Finally, we propose a novel character-level masked language modeling (CMLM) pretraining objective and explore its impact on the models' resistance to noise. Our experiments show that various architectures are impacted differently by separate types of noise, but encoder-decoders tend to be more robust to noise than models trained with a copy bias. CMLM pretraining helps transformers, but has lower impact on LSTMs.
Morphological Processing of Low-Resource Languages: Where We Are and What's Next
Mar 16, 2022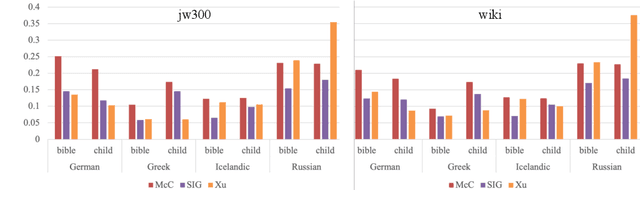
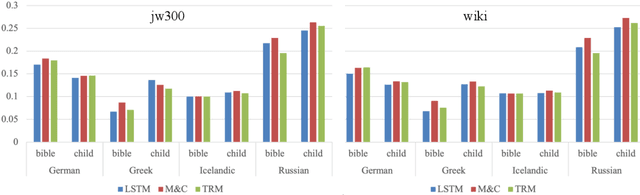
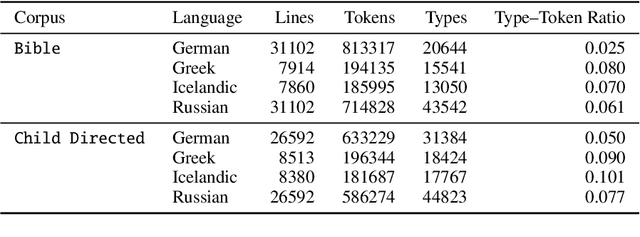
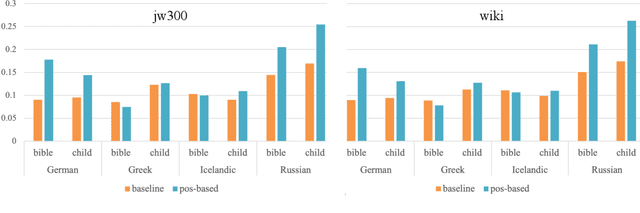
Automatic morphological processing can aid downstream natural language processing applications, especially for low-resource languages, and assist language documentation efforts for endangered languages. Having long been multilingual, the field of computational morphology is increasingly moving towards approaches suitable for languages with minimal or no annotated resources. First, we survey recent developments in computational morphology with a focus on low-resource languages. Second, we argue that the field is ready to tackle the logical next challenge: understanding a language's morphology from raw text alone. We perform an empirical study on a truly unsupervised version of the paradigm completion task and show that, while existing state-of-the-art models bridged by two newly proposed models we devise perform reasonably, there is still much room for improvement. The stakes are high: solving this task will increase the language coverage of morphological resources by a number of magnitudes.
From Algebraic Word Problem to Program: A Formalized Approach
Mar 11, 2020



In this paper, we propose a pipeline to convert grade school level algebraic word problem into program of a formal languageA-IMP. Using natural language processing tools, we break the problem into sentence fragments which can then be reduced to functions. The functions are categorized by the head verb of the sentence and its structure, as defined by (Hosseini et al., 2014). We define the function signature and extract its arguments from the text using dependency parsing. We have a working implementation of the entire pipeline which can be found on our github repository.