 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Beyond Limits: Multitask Learning and Synthetic Data for Low-Resource Canonical Morpheme Segmentation
May 22, 2025



We introduce a transformer-based morpheme segmentation system that augments a low-resource training signal through multitask learning and LLM-generated synthetic data. Our framework jointly predicts morphological segments and glosses from orthographic input, leveraging shared linguistic representations obtained through a common documentary process to enhance model generalization. To further address data scarcity, we integrate synthetic training data generated by large language models (LLMs) using in-context learning. Experimental results on the SIGMORPHON 2023 dataset show that our approach significantly improves word-level segmentation accuracy and morpheme-level F1-score across multiple low-resource languages.
Parsing Through Boundaries in Chinese Word Segmentation
Mar 29, 2025

Chinese word segmentation is a foundational task in natural language processing (NLP), with far-reaching effects on syntactic analysis. Unlike alphabetic languages like English, Chinese lacks explicit word boundaries, making segmentation both necessary and inherently ambiguous. This study highlights the intricate relationship between word segmentation and syntactic parsing, providing a clearer understanding of how different segmentation strategies shape dependency structures in Chinese. Focusing on the Chinese GSD treebank, we analyze multiple word boundary schemes, each reflecting distinct linguistic and computational assumptions, and examine how they influence the resulting syntactic structures. To support detailed comparison, we introduce an interactive web-based visualization tool that displays parsing outcomes across segmentation methods.
Developing multilingual speech synthesis system for Ojibwe, Mi'kmaq, and Maliseet
Feb 04, 2025


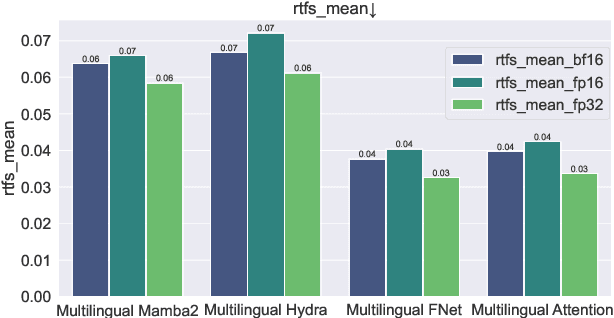
We present lightweight flow matching multilingual text-to-speech (TTS) systems for Ojibwe, Mi'kmaq, and Maliseet, three Indigenous languages in North America. Our results show that training a multilingual TTS model on three typologically similar languages can improve the performance over monolingual models, especially when data are scarce. Attention-free architectures are highly competitive with self-attention architecture with higher memory efficiency. Our research not only advances technical development for the revitalization of low-resource languages but also highlights the cultural gap in human evaluation protocols, calling for a more community-centered approach to human evaluation.
Multiple Sources are Better Than One: Incorporating External Knowledge in Low-Resource Glossing
Jun 16, 2024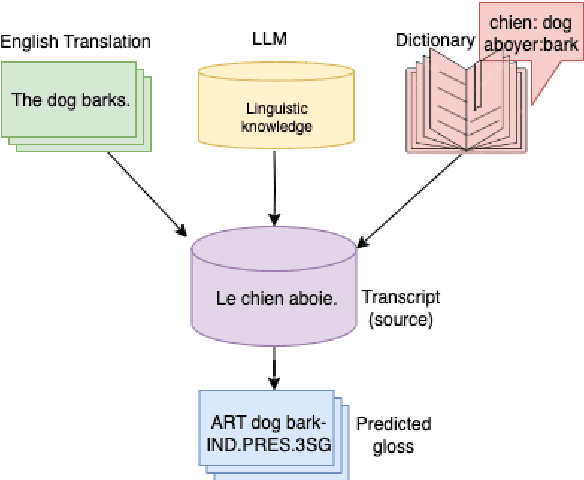
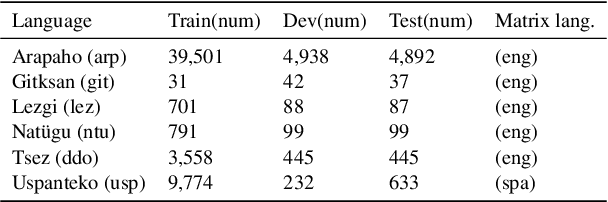
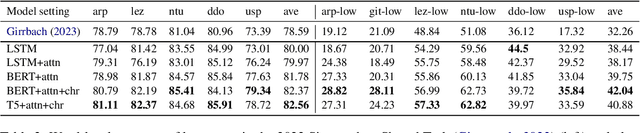
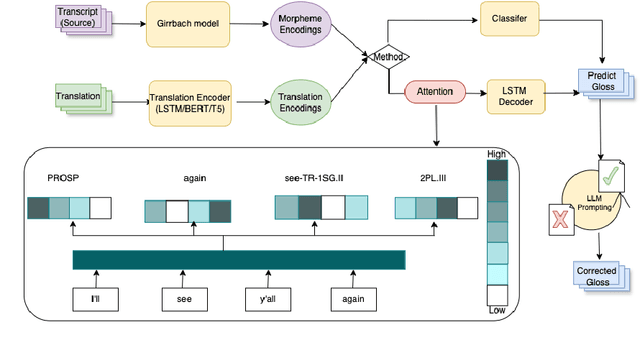
In this paper, we address the data scarcity problem in automatic data-driven glossing for low-resource languages by coordinating multiple sources of linguistic expertise. We supplement models with translations at both the token and sentence level as well as leverage the extensive linguistic capability of modern LLMs. Our enhancements lead to an average absolute improvement of 5%-points in word-level accuracy over the previous state of the art on a typologically diverse dataset spanning six low-resource languages. The improvements are particularly noticeable for the lowest-resourced language Gitksan, where we achieve a 10%-point improvement. Furthermore, in a simulated ultra-low resource setting for the same six languages, training on fewer than 100 glossed sentences, we establish an average 10%-point improvement in word-level accuracy over the previous state-of-the-art system.
Embedded Translations for Low-resource Automated Glossing
Mar 13, 2024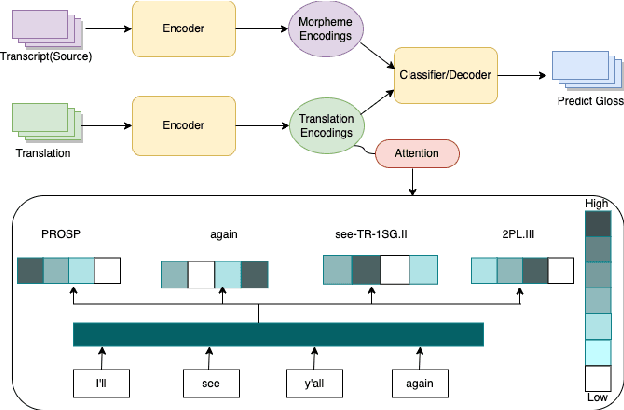
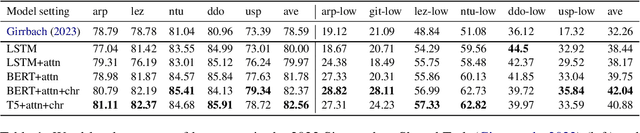
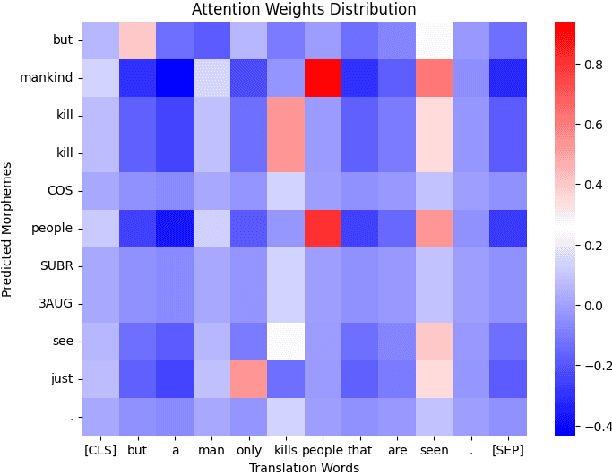
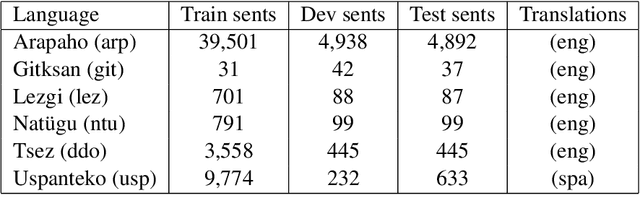
We investigate automatic interlinear glossing in low-resource settings. We augment a hard-attentional neural model with embedded translation information extracted from interlinear glossed text. After encoding these translations using large language models, specifically BERT and T5, we introduce a character-level decoder for generating glossed output. Aided by these enhancements, our model demonstrates an average improvement of 3.97\%-points over the previous state of the art on datasets from the SIGMORPHON 2023 Shared Task on Interlinear Glossing. In a simulated ultra low-resource setting, trained on as few as 100 sentences, our system achieves an average 9.78\%-point improvement over the plain hard-attentional baseline. These results highlight the critical role of translation information in boosting the system's performance, especially in processing and interpreting modest data sources. Our findings suggest a promising avenue for the documentation and preservation of languages, with our experiments on shared task datasets indicating significant advancements over the existing state of the art.
Open-vocabulary keyword spotting in any language through multilingual contrastive speech-phoneme pretraining
Nov 14, 2023



In this paper, we introduce a massively multilingual speech corpora with fine-grained phonemic transcriptions, encompassing more than 115 languages from diverse language families. Based on this multilingual dataset, we propose CLAP-IPA, a multilingual phoneme-speech contrastive embedding model capable of open-vocabulary matching between speech signals and phonemically transcribed keywords or arbitrary phrases. The proposed model has been tested on two fieldwork speech corpora in 97 unseen languages, exhibiting strong generalizability across languages. Comparison with a text-based model shows that using phonemes as modeling units enables much better crosslinguistic generalization than orthographic texts.
An Investigation of Noise in Morphological Inflection
May 26, 2023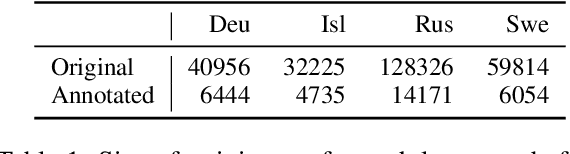
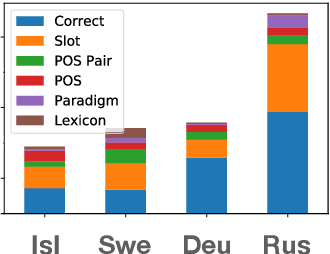
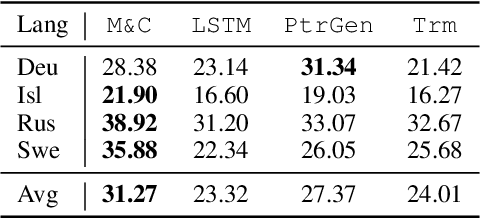
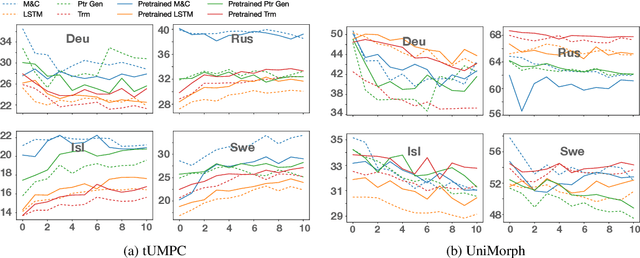
With a growing focus on morphological inflection systems for languages where high-quality data is scarce, training data noise is a serious but so far largely ignored concern. We aim at closing this gap by investigating the types of noise encountered within a pipeline for truly unsupervised morphological paradigm completion and its impact on morphological inflection systems: First, we propose an error taxonomy and annotation pipeline for inflection training data. Then, we compare the effect of different types of noise on multiple state-of-the-art inflection models. Finally, we propose a novel character-level masked language modeling (CMLM) pretraining objective and explore its impact on the models' resistance to noise. Our experiments show that various architectures are impacted differently by separate types of noise, but encoder-decoders tend to be more robust to noise than models trained with a copy bias. CMLM pretraining helps transformers, but has lower impact on LSTMs.
Dim Wihl Gat Tun: The Case for Linguistic Expertise in NLP for Underdocumented Languages
Mar 17, 2022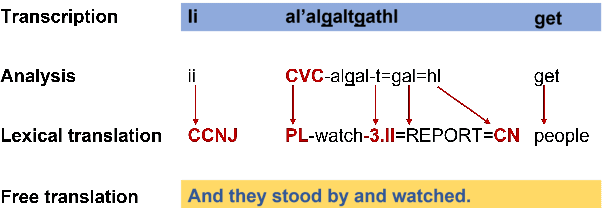
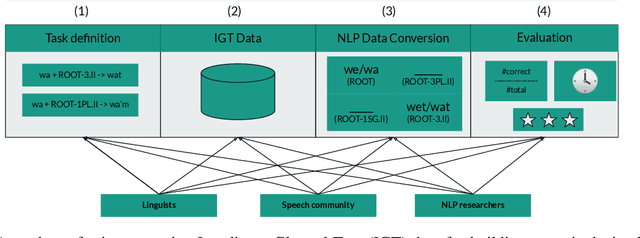
Recent progress in NLP is driven by pretrained models leveraging massive datasets and has predominantly benefited the world's political and economic superpowers. Technologically underserved languages are left behind because they lack such resources. Hundreds of underserved languages, nevertheless, have available data sources in the form of interlinear glossed text (IGT) from language documentation efforts. IGT remains underutilized in NLP work, perhaps because its annotations are only semi-structured and often language-specific. With this paper, we make the case that IGT data can be leveraged successfully provided that target language expertise is available. We specifically advocate for collaboration with documentary linguists. Our paper provides a roadmap for successful projects utilizing IGT data: (1) It is essential to define which NLP tasks can be accomplished with the given IGT data and how these will benefit the speech community. (2) Great care and target language expertise is required when converting the data into structured formats commonly employed in NLP. (3) Task-specific and user-specific evaluation can help to ascertain that the tools which are created benefit the target language speech community. We illustrate each step through a case study on developing a morphological reinflection system for the Tsimchianic language Gitksan.
Morphological Processing of Low-Resource Languages: Where We Are and What's Next
Mar 16, 2022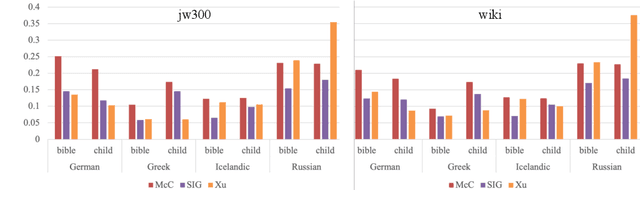
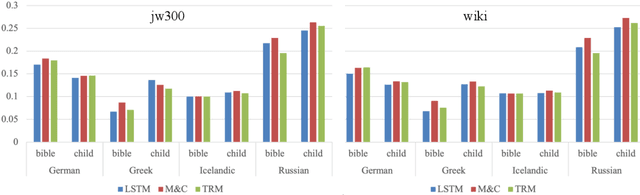
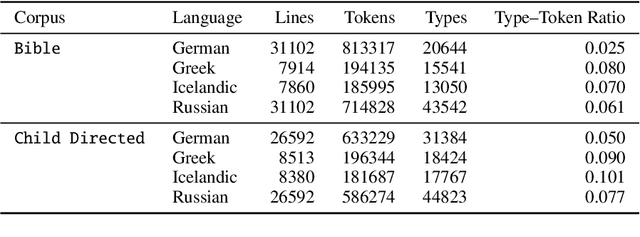
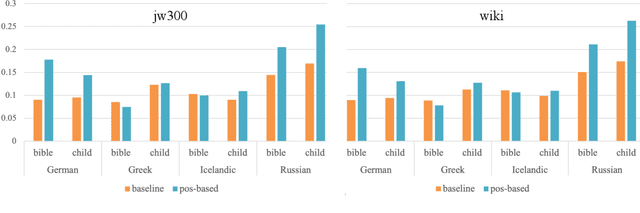
Automatic morphological processing can aid downstream natural language processing applications, especially for low-resource languages, and assist language documentation efforts for endangered languages. Having long been multilingual, the field of computational morphology is increasingly moving towards approaches suitable for languages with minimal or no annotated resources. First, we survey recent developments in computational morphology with a focus on low-resource languages. Second, we argue that the field is ready to tackle the logical next challenge: understanding a language's morphology from raw text alone. We perform an empirical study on a truly unsupervised version of the paradigm completion task and show that, while existing state-of-the-art models bridged by two newly proposed models we devise perform reasonably, there is still much room for improvement. The stakes are high: solving this task will increase the language coverage of morphological resources by a number of magnitudes.
CLiMP: A Benchmark for Chinese Language Model Evaluation
Jan 26, 2021
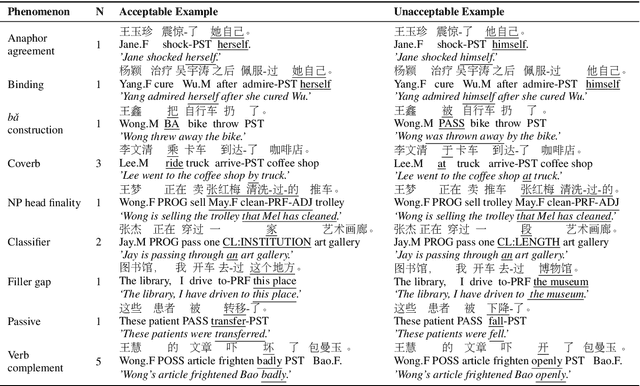
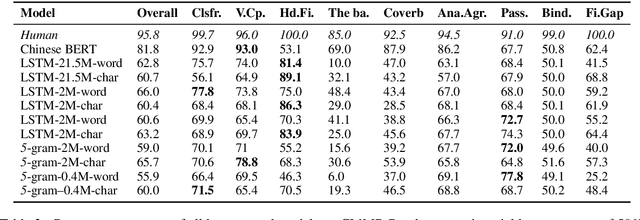
Linguistically informed analyses of language models (LMs) contribute to the understanding and improvement of these models. Here, we introduce the corpus of Chinese linguistic minimal pairs (CLiMP), which can be used to investigate what knowledge Chinese LMs acquire. CLiMP consists of sets of 1,000 minimal pairs (MPs) for 16 syntactic contrasts in Mandarin, covering 9 major Mandarin linguistic phenomena. The MPs are semi-automatically generated, and human agreement with the labels in CLiMP is 95.8%. We evaluated 11 different LMs on CLiMP, covering n-grams, LSTMs, and Chinese BERT. We find that classifier-noun agreement and verb complement selection are the phenomena that models generally perform best at. However, models struggle the most with the ba construction, binding, and filler-gap dependencies. Overall, Chinese BERT achieves an 81.8% average accuracy, while the performances of LSTMs and 5-grams are only moderately above chance level.