 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedded Translations for Low-resource Automated Glossing
Paper and Code
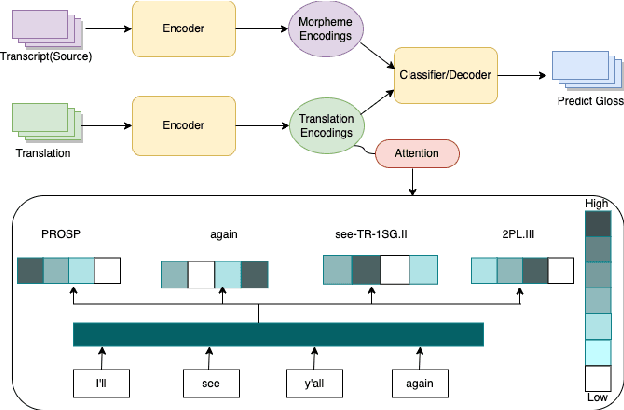
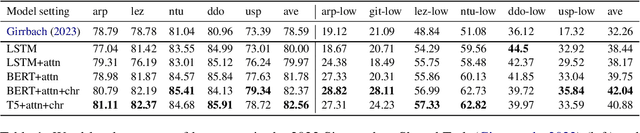
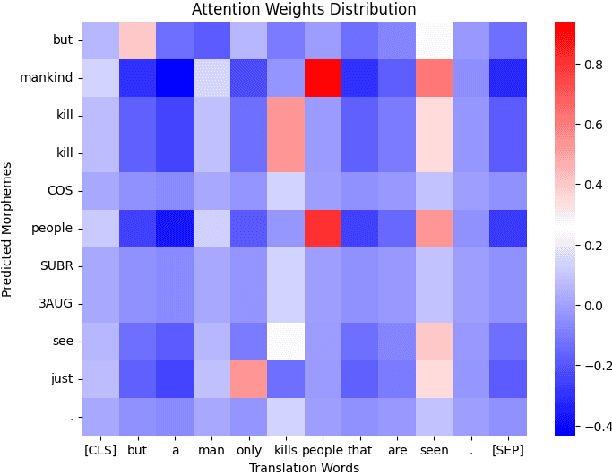
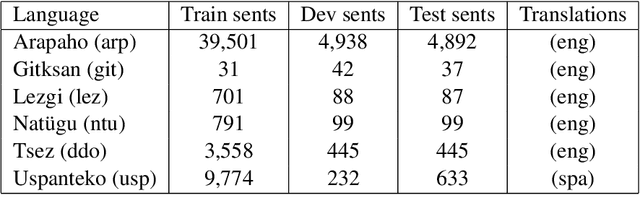
We investigate automatic interlinear glossing in low-resource settings. We augment a hard-attentional neural model with embedded translation information extracted from interlinear glossed text. After encoding these translations using large language models, specifically BERT and T5, we introduce a character-level decoder for generating glossed output. Aided by these enhancements, our model demonstrates an average improvement of 3.97\%-points over the previous state of the art on datasets from the SIGMORPHON 2023 Shared Task on Interlinear Glossing. In a simulated ultra low-resource setting, trained on as few as 100 sentences, our system achieves an average 9.78\%-point improvement over the plain hard-attentional baseline. These results highlight the critical role of translation information in boosting the system's performance, especially in processing and interpreting modest data sources. Our findings suggest a promising avenue for the documentation and preservation of languages, with our experiments on shared task datasets indicating significant advancements over the existing state of the art.