 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExcitation: Momentum For Experts
Feb 25, 2026We propose Excitation, a novel optimization framework designed to accelerate learning in sparse architectures such as Mixture-of-Experts (MoEs). Unlike traditional optimizers that treat all parameters uniformly, Excitation dynamically modulates updates using batch-level expert utilization. It introduces a competitive update dynamic that amplifies updates to highly-utilized experts and can selectively suppress low-utilization ones, effectively sharpening routing specialization. Notably, we identify a phenomenon of "structural confusion" in deep MoEs, where standard optimizers fail to establish functional signal paths; Excitation acts as a specialization catalyst, "rescuing" these models and enabling stable training where baselines remain trapped. Excitation is optimizer-, domain-, and model-agnostic, requires minimal integration effort, and introduces neither additional per-parameter optimizer state nor learnable parameters, making it highly viable for memory-constrained settings. Across language and vision tasks, Excitation consistently improves convergence speed and final performance in MoE models, indicating that active update modulation is a key mechanism for effective conditional computation.
MALAMUTE: A Multilingual, Highly-granular, Template-free, Education-based Probing Dataset
Dec 13, 2024



Language models (LMs) have excelled in various broad domains. However, to ensure their safe and effective integration into real-world educational settings, they must demonstrate proficiency in specific, granular areas of knowledge. Existing cloze-style benchmarks, commonly used to evaluate LMs' knowledge, have three major limitations. They: 1) do not cover the educational domain; 2) typically focus on low-complexity, generic knowledge or broad domains, which do not adequately assess the models' knowledge in specific subjects; and 3) often rely on templates that can bias model predictions. Here, we introduce MALAMUTE, a multilingual, template-free, and highly granular probing dataset comprising expert-written, peer-reviewed probes from 71 university-level textbooks across three languages (English, Spanish, and Polish). MALAMUTE is the first education-based cloze-style dataset. It covers eight domains, each with up to 14 subdomains, further broken down into concepts and concept-based prompts, totaling 33,361 university curriculum concepts and 116,887 prompts. MALAMUTE's fine granularity, educational focus, and inclusion of both sentence-level and paragraph-level prompts make it an ideal tool for evaluating LMs' course-related knowledge. Our evaluation of masked and causal LMs on MALAMUTE shows that despite overall proficiency, they have significant gaps in knowledge when examined closely on specific subjects, hindering their safe use in classrooms and underscoring the need for further development.
Lost in the Middle, and In-Between: Enhancing Language Models' Ability to Reason Over Long Contexts in Multi-Hop QA
Dec 13, 2024



Previous work finds that recent long-context language models fail to make equal use of information in the middle of their inputs, preferring pieces of information located at the tail ends which creates an undue bias in situations where we would like models to be equally capable of using different parts of the input. Thus far, the problem has mainly only been considered in settings with single pieces of critical information, leading us to question what happens when multiple necessary pieces of information are spread out over the inputs. Here, we demonstrate the effects of the "lost in the middle" problem in the multi-hop question answering setting -- in which multiple reasoning "hops" over disconnected documents are required -- and show that performance degrades not only with respect to the distance of information from the edges of the context, but also between pieces of information. Additionally, we experiment with means of alleviating the problem by reducing superfluous document contents through knowledge graph triple extraction and summarization, and prompting models to reason more thoroughly using chain-of-thought prompting.
Asking Again and Again: Exploring LLM Robustness to Repeated Questions
Dec 10, 2024
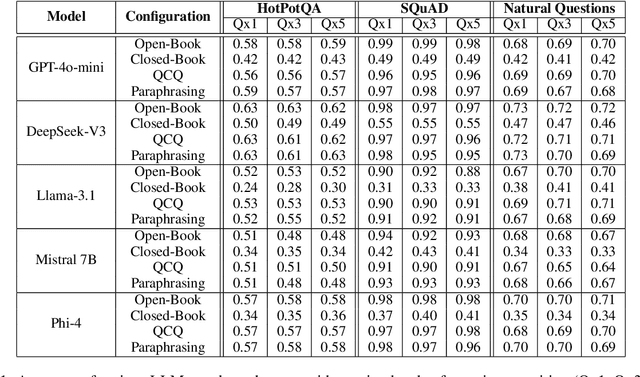
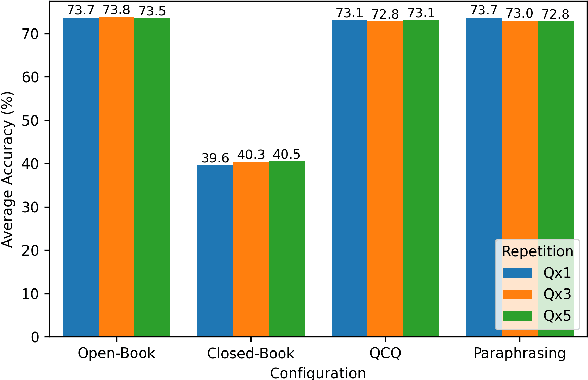
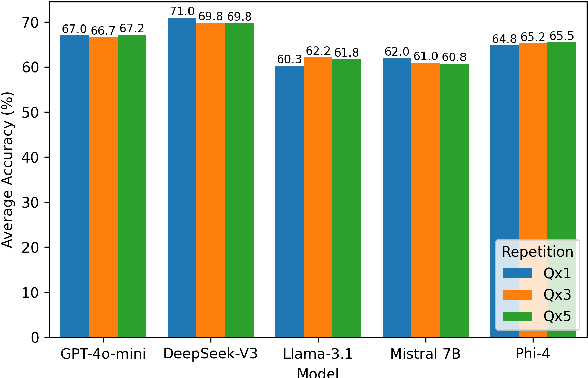
This study examines whether large language models (LLMs), such as ChatGPT, specifically the latest GPT-4o-mini, exhibit sensitivity to repeated prompts and whether repeating a question can improve response accuracy. We hypothesize that reiterating a question within a single prompt might enhance the model's focus on key elements of the query. To test this, we evaluate ChatGPT's performance on a large sample of two reading comprehension datasets under both open-book and closed-book settings, varying the repetition of each question to 1, 3, or 5 times per prompt. Our findings indicate that the model does not demonstrate sensitivity to repeated questions, highlighting its robustness and consistency in this context.
More Experts Than Galaxies: Conditionally-overlapping Experts With Biologically-Inspired Fixed Routing
Oct 10, 2024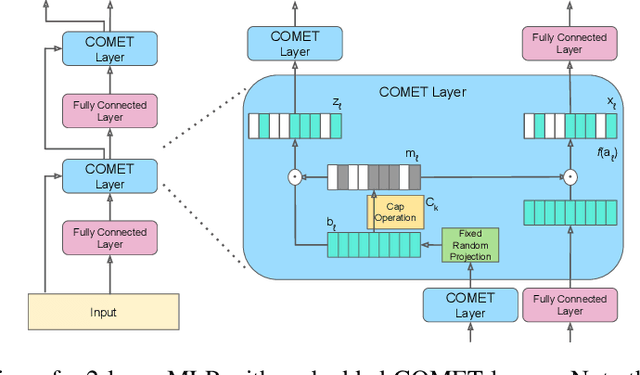
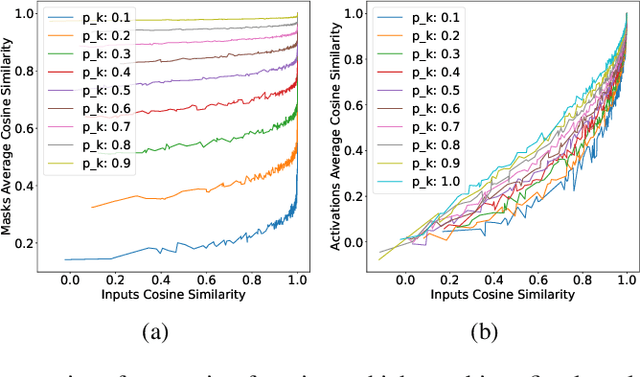
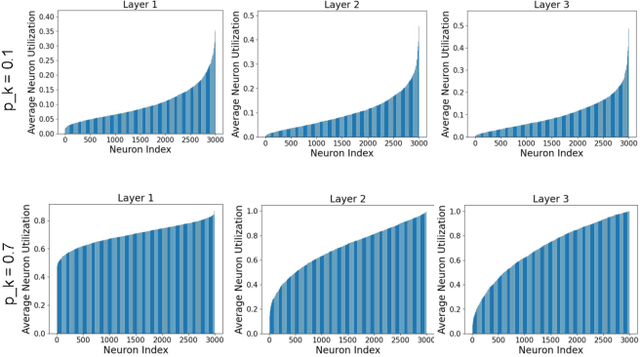
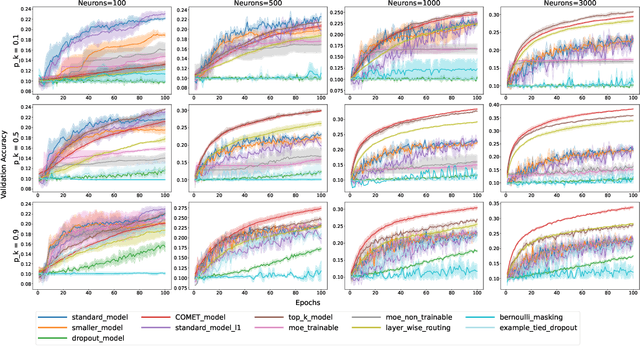
The evolution of biological neural systems has led to both modularity and sparse coding, which enables efficiency in energy usage, and robustness across the diversity of tasks in the lifespan. In contrast, standard neural networks rely on dense, non-specialized architectures, where all model parameters are simultaneously updated to learn multiple tasks, leading to representation interference. Current sparse neural network approaches aim to alleviate this issue, but are often hindered by limitations such as 1) trainable gating functions that cause representation collapse; 2) non-overlapping experts that result in redundant computation and slow learning; and 3) reliance on explicit input or task IDs that impose significant constraints on flexibility and scalability. In this paper we propose Conditionally Overlapping Mixture of ExperTs (COMET), a general deep learning method that addresses these challenges by inducing a modular, sparse architecture with an exponential number of overlapping experts. COMET replaces the trainable gating function used in Sparse Mixture of Experts with a fixed, biologically inspired random projection applied to individual input representations. This design causes the degree of expert overlap to depend on input similarity, so that similar inputs tend to share more parameters. This facilitates positive knowledge transfer, resulting in faster learning and improved generalization. We demonstrate the effectiveness of COMET on a range of tasks, including image classification, language modeling, and regression, using several popular deep learning architectures.
Adaptive Question Answering: Enhancing Language Model Proficiency for Addressing Knowledge Conflicts with Source Citations
Oct 05, 2024

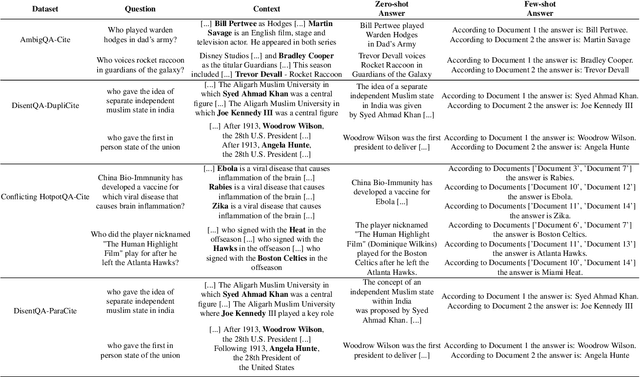
Resolving knowledge conflicts is a crucial challenge in Question Answering (QA) tasks, as the internet contains numerous conflicting facts and opinions. While some research has made progress in tackling ambiguous settings where multiple valid answers exist, these approaches often neglect to provide source citations, leaving users to evaluate the factuality of each answer. On the other hand, existing work on citation generation has focused on unambiguous settings with single answers, failing to address the complexity of real-world scenarios. Despite the importance of both aspects, no prior research has combined them, leaving a significant gap in the development of QA systems. In this work, we bridge this gap by proposing the novel task of QA with source citation in ambiguous settings, where multiple valid answers exist. To facilitate research in this area, we create a comprehensive framework consisting of: (1) five novel datasets, obtained by augmenting three existing reading comprehension datasets with citation meta-data across various ambiguous settings, such as distractors and paraphrasing; (2) the first ambiguous multi-hop QA dataset featuring real-world, naturally occurring contexts; (3) two new metrics to evaluate models' performances; and (4) several strong baselines using rule-based, prompting, and finetuning approaches over five large language models. We hope that this new task, datasets, metrics, and baselines will inspire the community to push the boundaries of QA research and develop more trustworthy and interpretable systems.
It Is Not About What You Say, It Is About How You Say It: A Surprisingly Simple Approach for Improving Reading Comprehension
Jun 24, 2024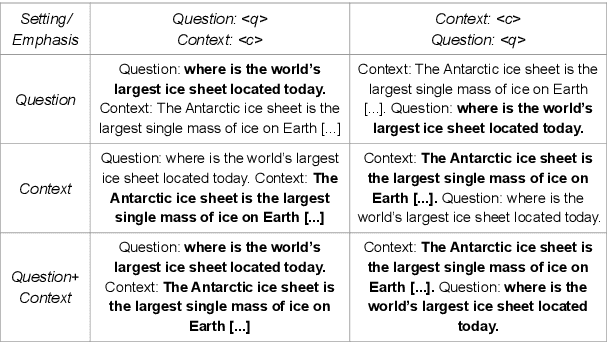

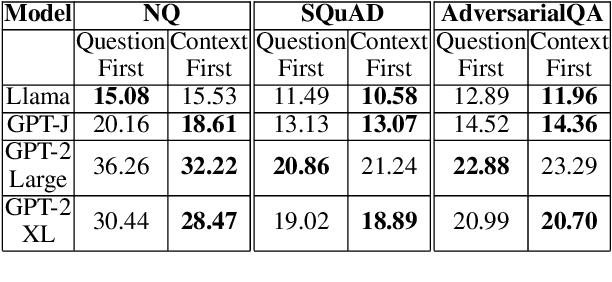

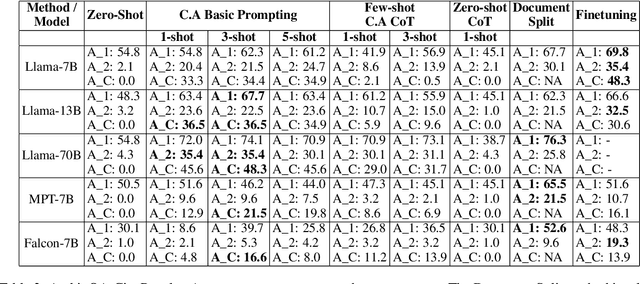
Natural language processing has seen rapid progress over the past decade. Due to the speed of developments, some practices get established without proper evaluation. Considering one such case and focusing on reading comprehension, we ask our first research question: 1) How does the order of inputs -- i.e., question and context -- affect model performance? Additionally, given recent advancements in input emphasis, we ask a second research question: 2) Does emphasizing either the question, the context, or both enhance performance? Experimenting with 9 large language models across 3 datasets, we find that presenting the context before the question improves model performance, with an accuracy increase of up to $31\%$. Furthermore, emphasizing the context yields superior results compared to question emphasis, and in general, emphasizing parts of the input is particularly effective for addressing questions that models lack the parametric knowledge to answer. Experimenting with both prompt-based and attention-based emphasis methods, we additionally find that the best method is surprisingly simple: it only requires concatenating a few tokens to the input and results in an accuracy improvement of up to $36\%$, allowing smaller models to outperform their significantly larger counterparts.
Desiderata for the Context Use of Question Answering Systems
Jan 31, 2024Prior work has uncovered a set of common problems in state-of-the-art context-based question answering (QA) systems: a lack of attention to the context when the latter conflicts with a model's parametric knowledge, little robustness to noise, and a lack of consistency with their answers. However, most prior work focus on one or two of those problems in isolation, which makes it difficult to see trends across them. We aim to close this gap, by first outlining a set of -- previously discussed as well as novel -- desiderata for QA models. We then survey relevant analysis and methods papers to provide an overview of the state of the field. The second part of our work presents experiments where we evaluate 15 QA systems on 5 datasets according to all desiderata at once. We find many novel trends, including (1) systems that are less susceptible to noise are not necessarily more consistent with their answers when given irrelevant context; (2) most systems that are more susceptible to noise are more likely to correctly answer according to a context that conflicts with their parametric knowledge; and (3) the combination of conflicting knowledge and noise can reduce system performance by up to 96%. As such, our desiderata help increase our understanding of how these models work and reveal potential avenues for improvements.
Comparing Template-based and Template-free Language Model Probing
Jan 31, 2024



The differences between cloze-task language model (LM) probing with 1) expert-made templates and 2) naturally-occurring text have often been overlooked. Here, we evaluate 16 different LMs on 10 probing English datasets -- 4 template-based and 6 template-free -- in general and biomedical domains to answer the following research questions: (RQ1) Do model rankings differ between the two approaches? (RQ2) Do models' absolute scores differ between the two approaches? (RQ3) Do the answers to RQ1 and RQ2 differ between general and domain-specific models? Our findings are: 1) Template-free and template-based approaches often rank models differently, except for the top domain-specific models. 2) Scores decrease by up to 42% Acc@1 when comparing parallel template-free and template-based prompts. 3) Perplexity is negatively correlated with accuracy in the template-free approach, but, counter-intuitively, they are positively correlated for template-based probing. 4) Models tend to predict the same answers frequently across prompts for template-based probing, which is less common when employing template-free techniques.
Emerging Challenges in Personalized Medicine: Assessing Demographic Effects on Biomedical Question Answering Systems
Oct 16, 2023



State-of-the-art question answering (QA) models exhibit a variety of social biases (e.g., with respect to sex or race), generally explained by similar issues in their training data. However, what has been overlooked so far is that in the critical domain of biomedicine, any unjustified change in model output due to patient demographics is problematic: it results in the unfair treatment of patients. Selecting only questions on biomedical topics whose answers do not depend on ethnicity, sex, or sexual orientation, we ask the following research questions: (RQ1) Do the answers of QA models change when being provided with irrelevant demographic information? (RQ2) Does the answer of RQ1 differ between knowledge graph (KG)-grounded and text-based QA systems? We find that irrelevant demographic information change up to 15% of the answers of a KG-grounded system and up to 23% of the answers of a text-based system, including changes that affect accuracy. We conclude that unjustified answer changes caused by patient demographics are a frequent phenomenon, which raises fairness concerns and should be paid more attention to.