Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsking Again and Again: Exploring LLM Robustness to Repeated Questions
Paper and Code
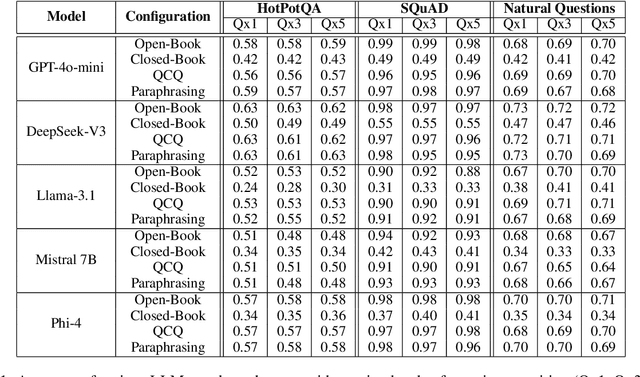
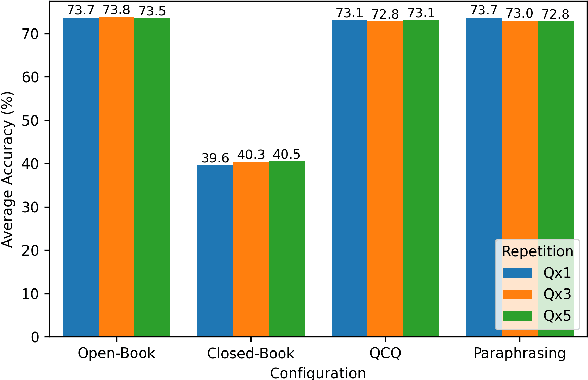
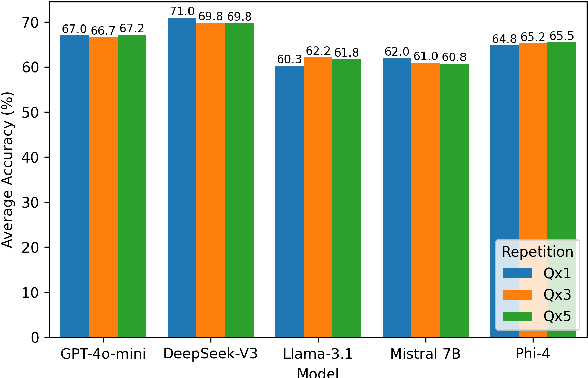
This study examines whether large language models (LLMs), such as ChatGPT, specifically the latest GPT-4o-mini, exhibit sensitivity to repeated prompts and whether repeating a question can improve response accuracy. We hypothesize that reiterating a question within a single prompt might enhance the model's focus on key elements of the query. To test this, we evaluate ChatGPT's performance on a large sample of two reading comprehension datasets under both open-book and closed-book settings, varying the repetition of each question to 1, 3, or 5 times per prompt. Our findings indicate that the model does not demonstrate sensitivity to repeated questions, highlighting its robustness and consistency in this context.
View paper on