 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Infant Crying Detection with Gradient Boosting for Improved Emotional and Mental Health Diagnostics
Oct 11, 2024Infant crying can serve as a crucial indicator of various physiological and emotional states. This paper introduces a comprehensive approach for detecting infant cries within audio data. We integrate Meta's Wav2Vec with traditional audio features, such as Mel-frequency cepstral coefficients (MFCCs), chroma, and spectral contrast, employing Gradient Boosting Machines (GBM) for cry classification. We validate our approach on a real-world dataset, demonstrating significant performance improvements over existing methods.
More Experts Than Galaxies: Conditionally-overlapping Experts With Biologically-Inspired Fixed Routing
Oct 10, 2024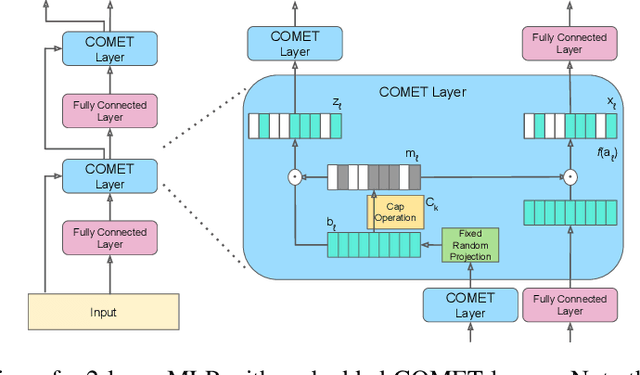
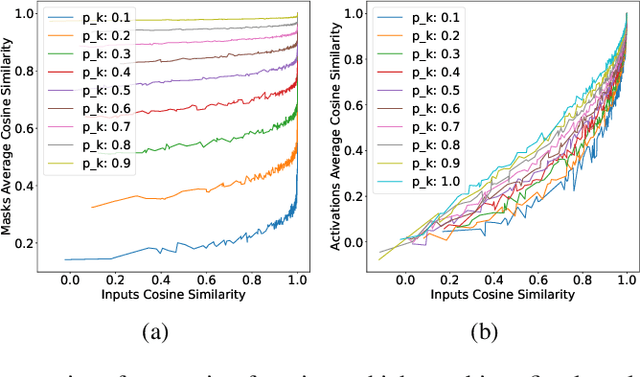
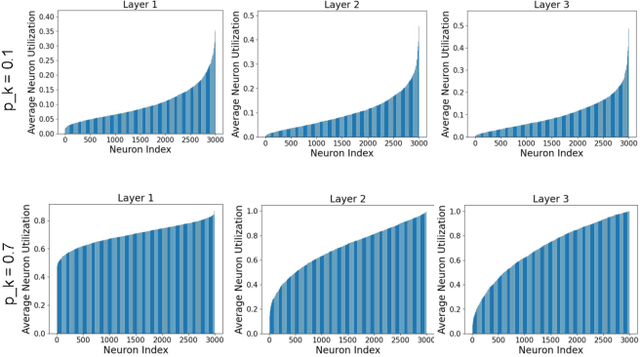
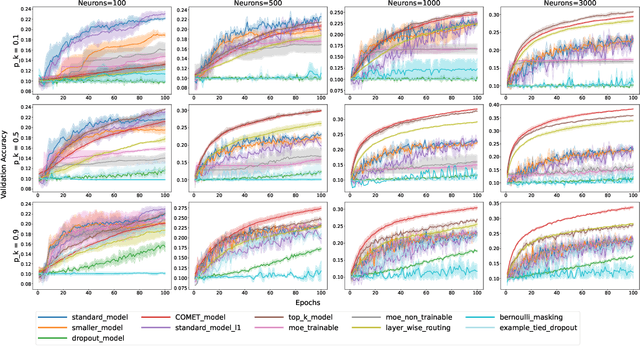
The evolution of biological neural systems has led to both modularity and sparse coding, which enables efficiency in energy usage, and robustness across the diversity of tasks in the lifespan. In contrast, standard neural networks rely on dense, non-specialized architectures, where all model parameters are simultaneously updated to learn multiple tasks, leading to representation interference. Current sparse neural network approaches aim to alleviate this issue, but are often hindered by limitations such as 1) trainable gating functions that cause representation collapse; 2) non-overlapping experts that result in redundant computation and slow learning; and 3) reliance on explicit input or task IDs that impose significant constraints on flexibility and scalability. In this paper we propose Conditionally Overlapping Mixture of ExperTs (COMET), a general deep learning method that addresses these challenges by inducing a modular, sparse architecture with an exponential number of overlapping experts. COMET replaces the trainable gating function used in Sparse Mixture of Experts with a fixed, biologically inspired random projection applied to individual input representations. This design causes the degree of expert overlap to depend on input similarity, so that similar inputs tend to share more parameters. This facilitates positive knowledge transfer, resulting in faster learning and improved generalization. We demonstrate the effectiveness of COMET on a range of tasks, including image classification, language modeling, and regression, using several popular deep learning architectures.
Interpretable factorization of clinical questionnaires to identify latent factors of psychopathology
Dec 12, 2023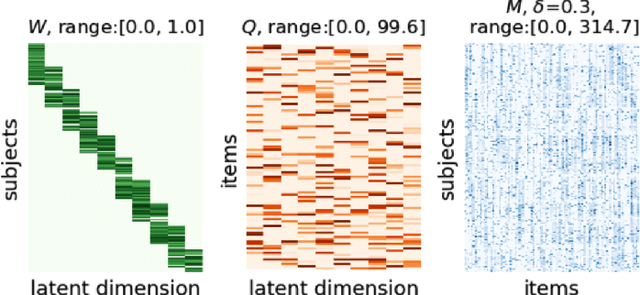
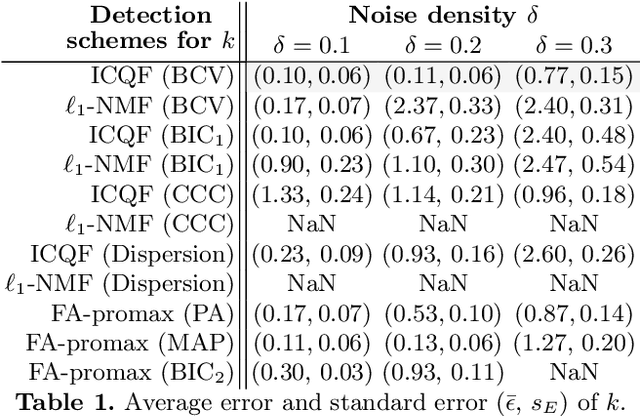
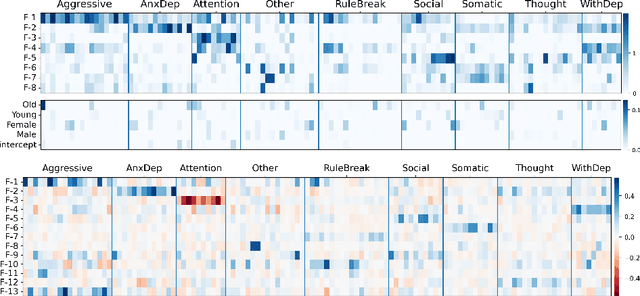
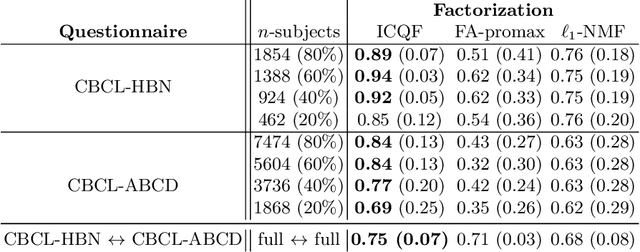
Psychiatry research seeks to understand the manifestations of psychopathology in behavior, as measured in questionnaire data, by identifying a small number of latent factors that explain them. While factor analysis is the traditional tool for this purpose, the resulting factors may not be interpretable, and may also be subject to confounding variables. Moreover, missing data are common, and explicit imputation is often required. To overcome these limitations, we introduce interpretability constrained questionnaire factorization (ICQF), a non-negative matrix factorization method with regularization tailored for questionnaire data. Our method aims to promote factor interpretability and solution stability. We provide an optimization procedure with theoretical convergence guarantees, and an automated procedure to detect latent dimensionality accurately. We validate these procedures using realistic synthetic data. We demonstrate the effectiveness of our method in a widely used general-purpose questionnaire, in two independent datasets (the Healthy Brain Network and Adolescent Brain Cognitive Development studies). Specifically, we show that ICQF improves interpretability, as defined by domain experts, while preserving diagnostic information across a range of disorders, and outperforms competing methods for smaller dataset sizes. This suggests that the regularization in our method matches domain characteristics. The python implementation for ICQF is available at \url{https://github.com/jefferykclam/ICQF}.
Testing for context-dependent changes in neural encoding in naturalistic experiments
Nov 17, 2022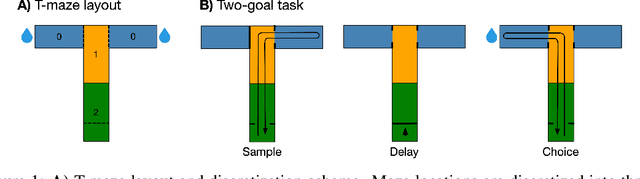
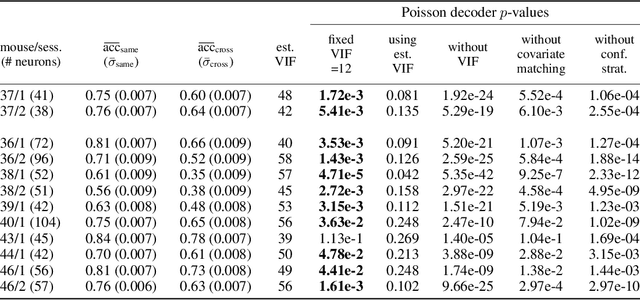
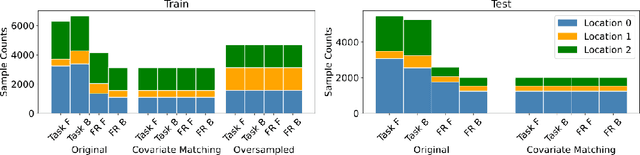
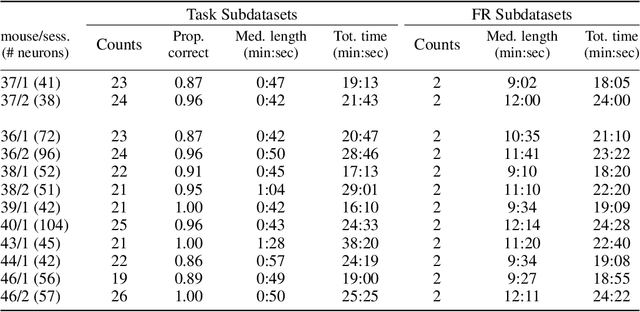
We propose a decoding-based approach to detect context effects on neural codes in longitudinal neural recording data. The approach is agnostic to how information is encoded in neural activity, and can control for a variety of possible confounding factors present in the data. We demonstrate our approach by determining whether it is possible to decode location encoding from prefrontal cortex in the mouse and, further, testing whether the encoding changes due to task engagement.
Representation learning of rare temporal conditions for travel time prediction
Aug 09, 2022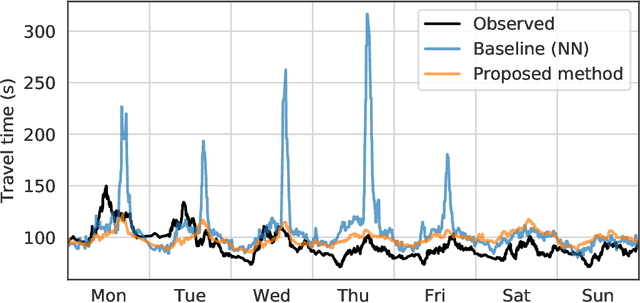
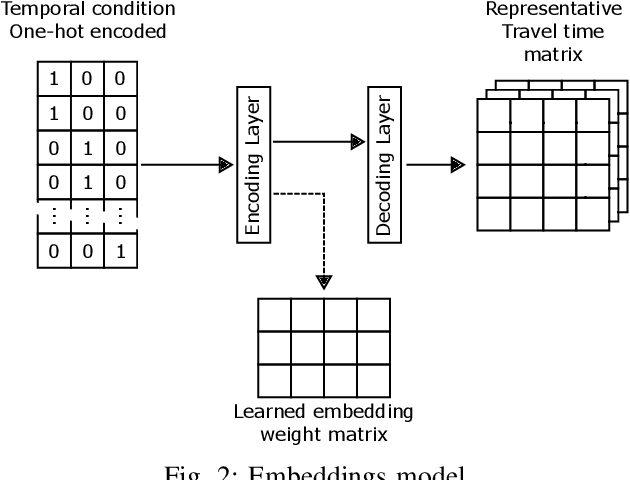
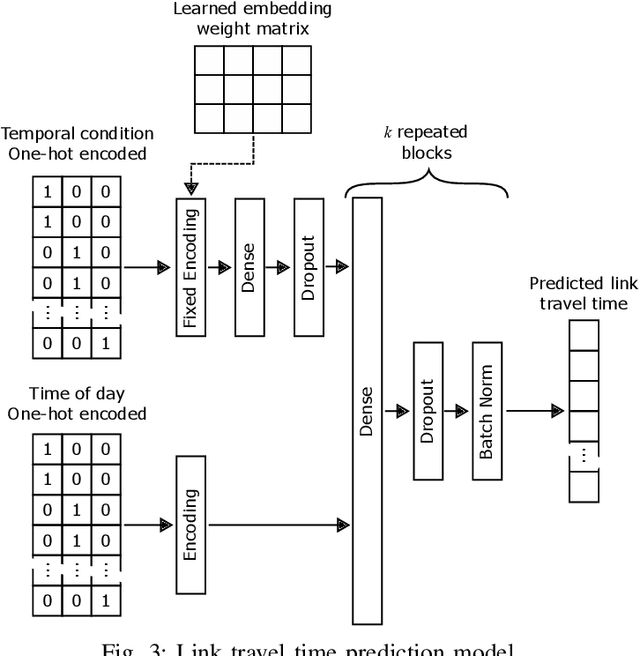
Predicting travel time under rare temporal conditions (e.g., public holidays, school vacation period, etc.) constitutes a challenge due to the limitation of historical data. If at all available, historical data often form a heterogeneous time series due to high probability of other changes over long periods of time (e.g., road works, introduced traffic calming initiatives, etc.). This is especially prominent in cities and suburban areas. We present a vector-space model for encoding rare temporal conditions, that allows coherent representation learning across different temporal conditions. We show increased performance for travel time prediction over different baselines when utilizing the vector-space encoding for representing the temporal setting.
VICE: Variational Interpretable Concept Embeddings
May 13, 2022

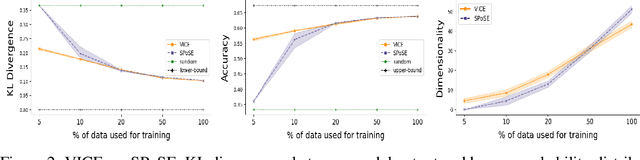
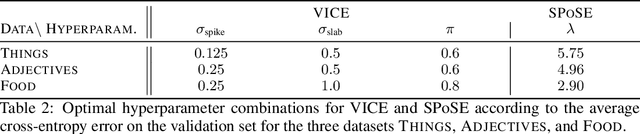
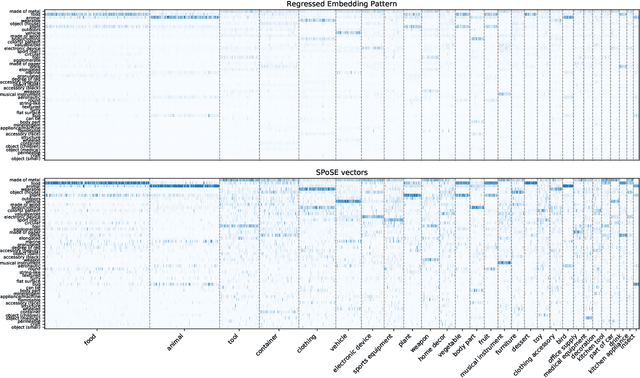
A central goal in the cognitive sciences is the development of computational models of mental representations of object concepts. This paper introduces Variational Interpretable Concept Embeddings (VICE), an approximate Bayesian method for learning interpretable object concept embeddings from human behavior in an odd-one-out triplet task. We use variational inference to obtain a sparse, non-negative solution with uncertainty estimates about each embedding value. We exploit these estimates to select the dimensions that explain the data automatically. We introduce a PAC learning bound for VICE that can be used to estimate generalization performance or determine a sufficient sample size for different experimental designs. VICE rivals or outperforms its predecessor, SPoSE, at predicting human behavior in the odd-one-out triplet task. Furthermore, VICE object representations are substantially more reproducible and consistent across random initializations.
A Deep Neural Network Tool for Automatic Segmentation of Human Body Parts in Natural Scenes
Sep 08, 2020
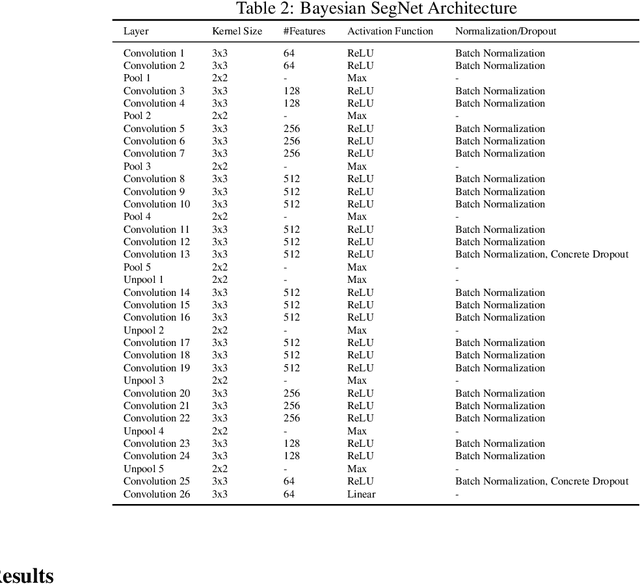

This short article describes a deep neural network trained to perform automatic segmentation of human body parts in natural scenes. More specifically, we trained a Bayesian SegNet with concrete dropout on the Pascal-Parts dataset to predict whether each pixel in a given frame was part of a person's hair, head, ear, eyebrows, legs, arms, mouth, neck, nose, or torso.
Understanding Object Affordances Through Verb Usage Patterns
Jun 22, 2020
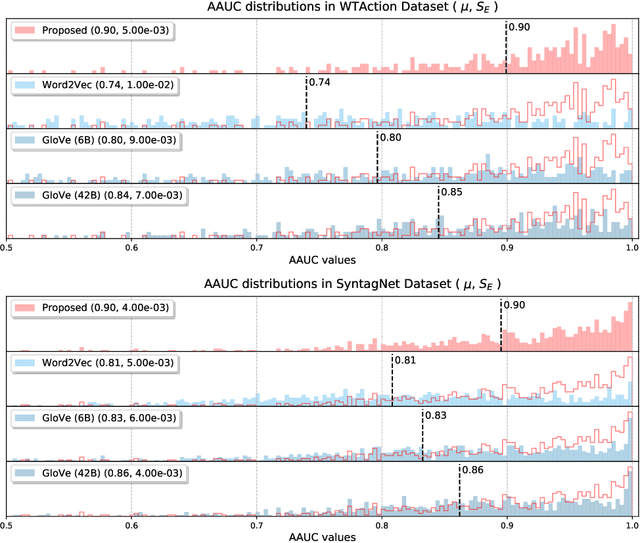

In order to interact with objects in our environment, we rely on an understanding of the actions that can be performed on them, and the extent to which they rely or have an effect on the properties of the object. This knowledge is called the object "affordance". We propose an approach for creating an embedding of objects in an affordance space, in which each dimension corresponds to an aspect of meaning shared by many actions, using text corpora. This embedding makes it possible to predict which verbs will be applicable to a given object, as captured in human judgments of affordance. We show that the dimensions learned are interpretable, and that they correspond to patterns of interaction with objects. Finally, we show that they can be used to predict other dimensions of object representation that have been shown to underpin human judgments of object similarity.
Evaluating Adversarial Robustness for Deep Neural Network Interpretability using fMRI Decoding
Apr 23, 2020

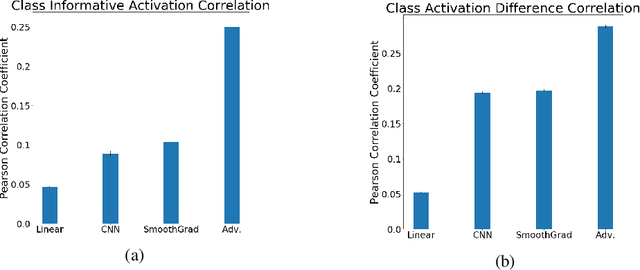
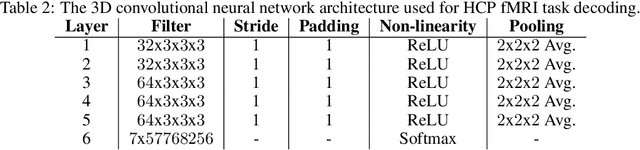
While deep neural networks (DNNs) are being increasingly used to make predictions from high-dimensional, complex data, they are widely seen as uninterpretable "black boxes", since it can be difficult to discover what input information is used to make predictions. This ability is particularly important for applications in cognitive neuroscience and neuroinformatics. A saliency map is a common approach for producing interpretable visualizations of the relative importance of input features for a prediction. However, many methods for creating these maps fail due to focusing too much on the input or being extremely sensitive to small input noise. It is also challenging to quantitatively evaluate how well saliency maps correspond to the truly relevant input information. In this paper, we develop two quantitative evaluation procedures for saliency methods, using the fact that the Human Connectome Project (HCP) dataset contains functional magnetic resonance imaging(fMRI) data from multiple tasks per subject to create ground truth saliency maps.We then introduce an adversarial training method that makes DNNs robust to small input noise, and use these evaluations to demonstrate that it greatly improves interpretability.
Bayesian Automatic Relevance Determination for Utility Function Specification in Discrete Choice Models
Jun 10, 2019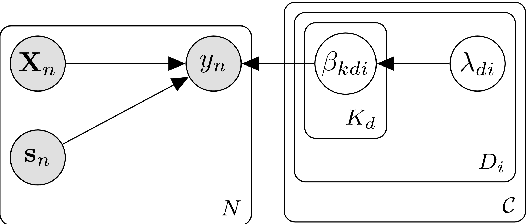

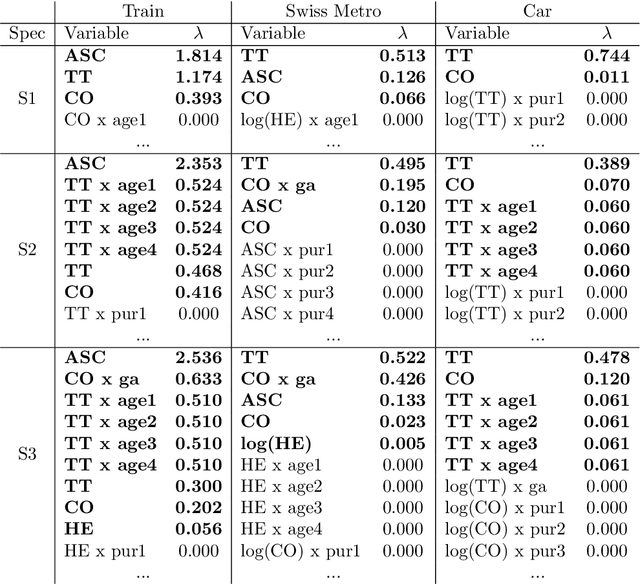

Specifying utility functions is a key step towards applying the discrete choice framework for understanding the behaviour processes that govern user choices. However, identifying the utility function specifications that best model and explain the observed choices can be a very challenging and time-consuming task. This paper seeks to help modellers by leveraging the Bayesian framework and the concept of automatic relevance determination (ARD), in order to automatically determine an optimal utility function specification from an exponentially large set of possible specifications in a purely data-driven manner. Based on recent advances in approximate Bayesian inference, a doubly stochastic variational inference is developed, which allows the proposed DCM-ARD model to scale to very large and high-dimensional datasets. Using semi-artificial choice data, the proposed approach is shown to very accurately recover the true utility function specifications that govern the observed choices. Moreover, when applied to real choice data, DCM-ARD is shown to be able discover high quality specifications that can outperform previous ones from the literature according to multiple criteria, thereby demonstrating its practical applicability.