 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimensions underlying the representational alignment of deep neural networks with humans
Jun 27, 2024Determining the similarities and differences between humans and artificial intelligence is an important goal both in machine learning and cognitive neuroscience. However, similarities in representations only inform us about the degree of alignment, not the factors that determine it. Drawing upon recent developments in cognitive science, we propose a generic framework for yielding comparable representations in humans and deep neural networks (DNN). Applying this framework to humans and a DNN model of natural images revealed a low-dimensional DNN embedding of both visual and semantic dimensions. In contrast to humans, DNNs exhibited a clear dominance of visual over semantic features, indicating divergent strategies for representing images. While in-silico experiments showed seemingly-consistent interpretability of DNN dimensions, a direct comparison between human and DNN representations revealed substantial differences in how they process images. By making representations directly comparable, our results reveal important challenges for representational alignment, offering a means for improving their comparability.
Getting aligned on representational alignment
Nov 02, 2023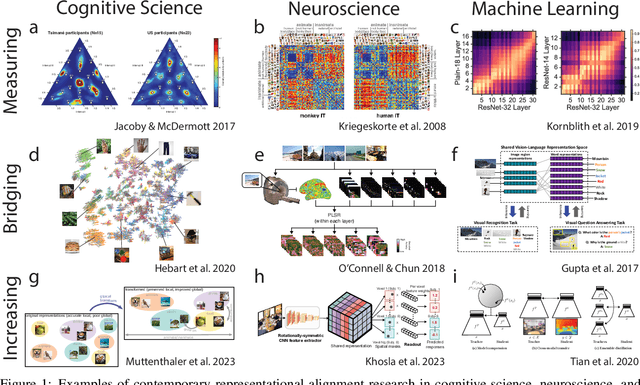
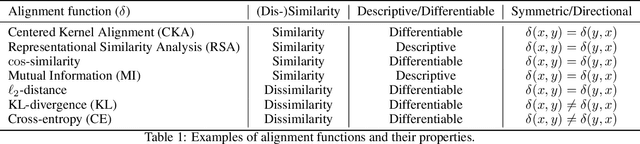
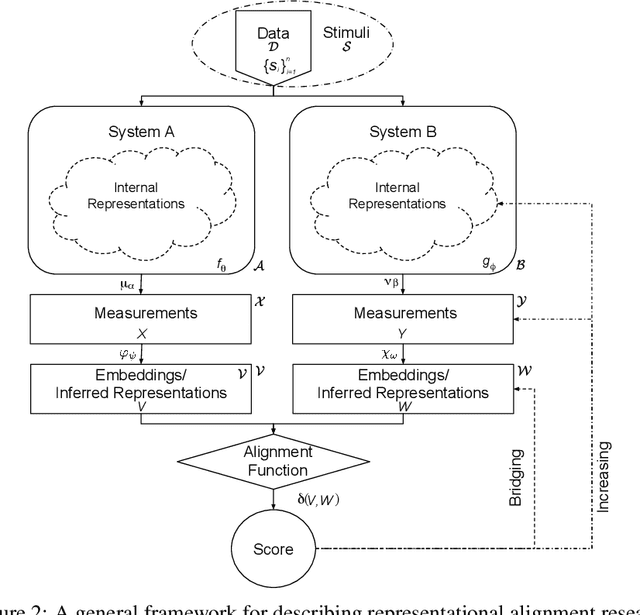
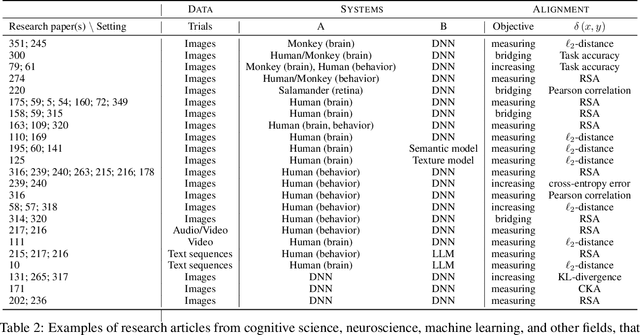
Biological and artificial information processing systems form representations that they can use to categorize, reason, plan, navigate, and make decisions. How can we measure the extent to which the representations formed by these diverse systems agree? Do similarities in representations then translate into similar behavior? How can a system's representations be modified to better match those of another system? These questions pertaining to the study of representational alignment are at the heart of some of the most active research areas in cognitive science, neuroscience, and machine learning. For example, cognitive scientists measure the representational alignment of multiple individuals to identify shared cognitive priors, neuroscientists align fMRI responses from multiple individuals into a shared representational space for group-level analyses, and ML researchers distill knowledge from teacher models into student models by increasing their alignment. Unfortunately, there is limited knowledge transfer between research communities interested in representational alignment, so progress in one field often ends up being rediscovered independently in another. Thus, greater cross-field communication would be advantageous. To improve communication between these fields, we propose a unifying framework that can serve as a common language between researchers studying representational alignment. We survey the literature from all three fields and demonstrate how prior work fits into this framework. Finally, we lay out open problems in representational alignment where progress can benefit all three of these fields. We hope that our work can catalyze cross-disciplinary collaboration and accelerate progress for all communities studying and developing information processing systems. We note that this is a working paper and encourage readers to reach out with their suggestions for future revisions.
VICE: Variational Interpretable Concept Embeddings
May 13, 2022

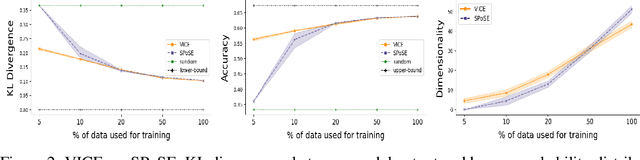
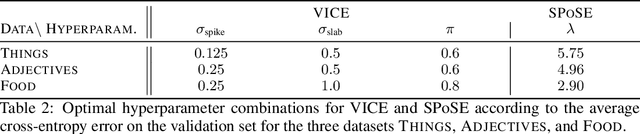
A central goal in the cognitive sciences is the development of computational models of mental representations of object concepts. This paper introduces Variational Interpretable Concept Embeddings (VICE), an approximate Bayesian method for learning interpretable object concept embeddings from human behavior in an odd-one-out triplet task. We use variational inference to obtain a sparse, non-negative solution with uncertainty estimates about each embedding value. We exploit these estimates to select the dimensions that explain the data automatically. We introduce a PAC learning bound for VICE that can be used to estimate generalization performance or determine a sufficient sample size for different experimental designs. VICE rivals or outperforms its predecessor, SPoSE, at predicting human behavior in the odd-one-out triplet task. Furthermore, VICE object representations are substantially more reproducible and consistent across random initializations.
Semantic features of object concepts generated with GPT-3
Feb 08, 2022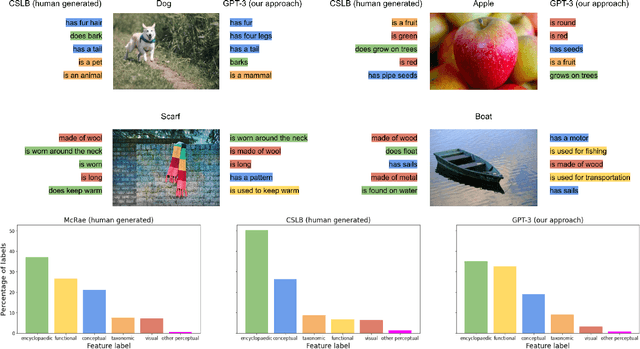

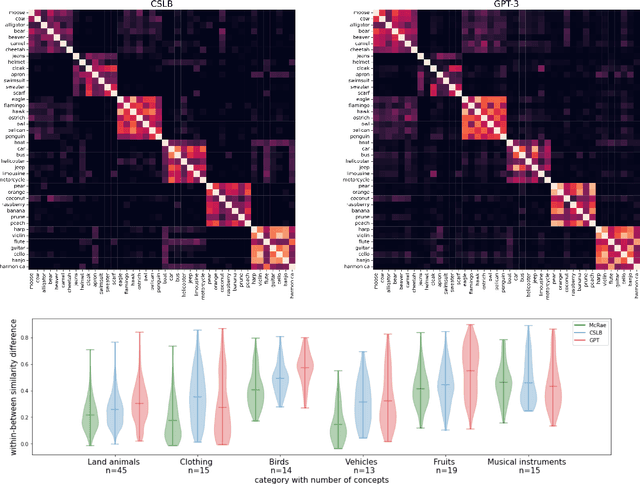
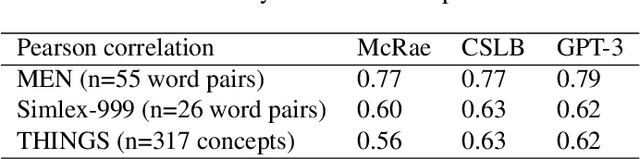
Semantic features have been playing a central role in investigating the nature of our conceptual representations. Yet the enormous time and effort required to empirically sample and norm features from human raters has restricted their use to a limited set of manually curated concepts. Given recent promising developments with transformer-based language models, here we asked whether it was possible to use such models to automatically generate meaningful lists of properties for arbitrary object concepts and whether these models would produce features similar to those found in humans. To this end, we probed a GPT-3 model to generate semantic features for 1,854 objects and compared automatically-generated features to existing human feature norms. GPT-3 generated many more features than humans, yet showed a similar distribution in the types of generated features. Generated feature norms rivaled human norms in predicting similarity, relatedness, and category membership, while variance partitioning demonstrated that these predictions were driven by similar variance in humans and GPT-3. Together, these results highlight the potential of large language models to capture important facets of human knowledge and yield a new approach for automatically generating interpretable feature sets, thus drastically expanding the potential use of semantic features in psychological and linguistic studies.
Revealing interpretable object representations from human behavior
Jan 09, 2019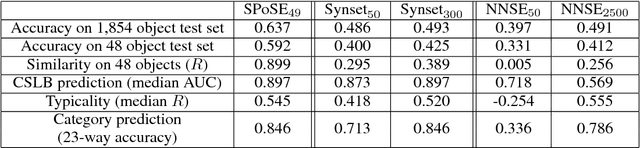
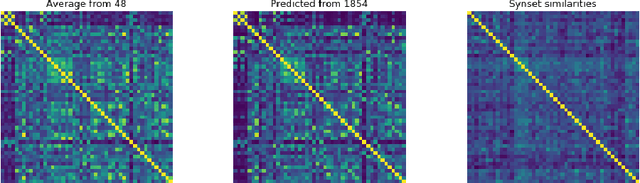

To study how mental object representations are related to behavior, we estimated sparse, non-negative representations of objects using human behavioral judgments on images representative of 1,854 object categories. These representations predicted a latent similarity structure between objects, which captured most of the explainable variance in human behavioral judgments. Individual dimensions in the low-dimensional embedding were found to be highly reproducible and interpretable as conveying degrees of taxonomic membership, functionality, and perceptual attributes. We further demonstrated the predictive power of the embeddings for explaining other forms of human behavior, including categorization, typicality judgments, and feature ratings, suggesting that the dimensions reflect human conceptual representations of objects beyond the specific task.