 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimensions underlying the representational alignment of deep neural networks with humans
Jun 27, 2024Determining the similarities and differences between humans and artificial intelligence is an important goal both in machine learning and cognitive neuroscience. However, similarities in representations only inform us about the degree of alignment, not the factors that determine it. Drawing upon recent developments in cognitive science, we propose a generic framework for yielding comparable representations in humans and deep neural networks (DNN). Applying this framework to humans and a DNN model of natural images revealed a low-dimensional DNN embedding of both visual and semantic dimensions. In contrast to humans, DNNs exhibited a clear dominance of visual over semantic features, indicating divergent strategies for representing images. While in-silico experiments showed seemingly-consistent interpretability of DNN dimensions, a direct comparison between human and DNN representations revealed substantial differences in how they process images. By making representations directly comparable, our results reveal important challenges for representational alignment, offering a means for improving their comparability.
Efficient Deep Reinforcement Learning with Predictive Processing Proximal Policy Optimization
Nov 11, 2022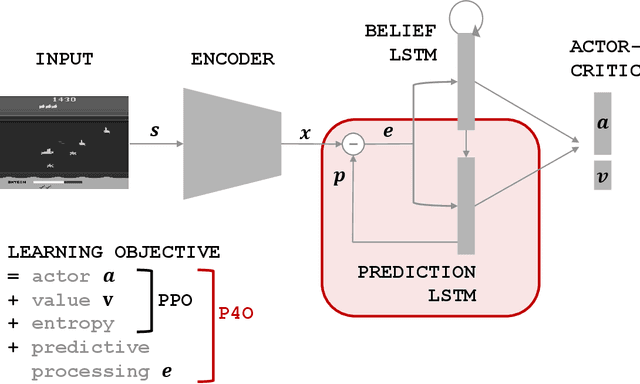

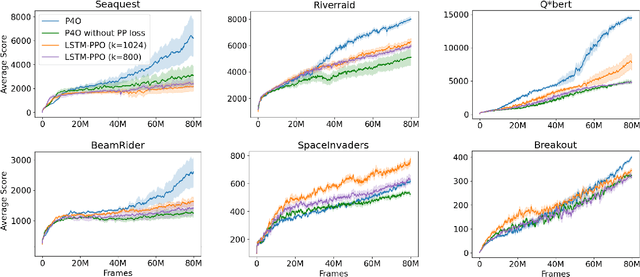
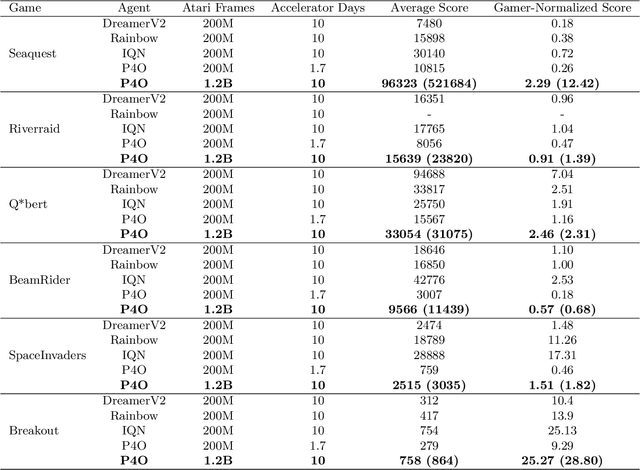
Advances in reinforcement learning (RL) often rely on massive compute resources and remain notoriously sample inefficient. In contrast, the human brain is able to efficiently learn effective control strategies using limited resources. This raises the question whether insights from neuroscience can be used to improve current RL methods. Predictive processing is a popular theoretical framework which maintains that the human brain is actively seeking to minimize surprise. We show that recurrent neural networks which predict their own sensory states can be leveraged to minimise surprise, yielding substantial gains in cumulative reward. Specifically, we present the Predictive Processing Proximal Policy Optimization (P4O) agent; an actor-critic reinforcement learning agent that applies predictive processing to a recurrent variant of the PPO algorithm by integrating a world model in its hidden state. P4O significantly outperforms a baseline recurrent variant of the PPO algorithm on multiple Atari games using a single GPU. It also outperforms other state-of-the-art agents given the same wall-clock time and exceeds human gamer performance on multiple games including Seaquest, which is a particularly challenging environment in the Atari domain. Altogether, our work underscores how insights from the field of neuroscience may support the development of more capable and efficient artificial agents.
Explainable 3D Convolutional Neural Networks by Learning Temporal Transformations
Jun 29, 2020


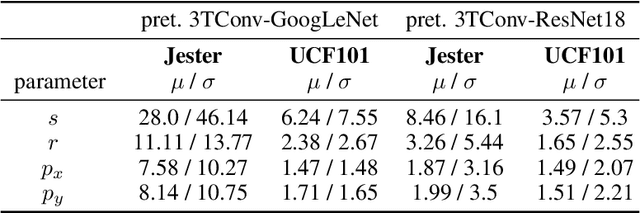
In this paper we introduce the temporally factorized 3D convolution (3TConv) as an interpretable alternative to the regular 3D convolution (3DConv). In a 3TConv the 3D convolutional filter is obtained by learning a 2D filter and a set of temporal transformation parameters, resulting in a sparse filter where the 2D slices are sequentially dependent on each other in the temporal dimension. We demonstrate that 3TConv learns temporal transformations that afford a direct interpretation. The temporal parameters can be used in combination with various existing 2D visualization methods. We also show that insight about what the model learns can be achieved by analyzing the transformation parameter statistics on a layer and model level. Finally, we implicitly demonstrate that, in popular ConvNets, the 2DConv can be replaced with a 3TConv and that the weights can be transferred to yield pretrained 3TConvs. pretrained 3TConvnets leverage more than a decade of work on traditional 2DConvNets by being able to make use of features that have been proven to deliver excellent results on image classification benchmarks.
The Indian Chefs Process
Jan 29, 2020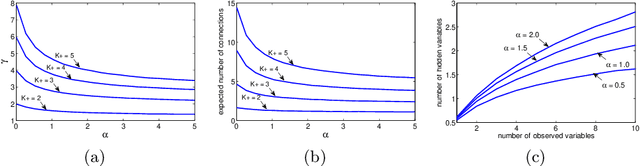


This paper introduces the Indian Chefs Process (ICP), a Bayesian nonparametric prior on the joint space of infinite directed acyclic graphs (DAGs) and orders that generalizes Indian Buffet Processes. As our construction shows, the proposed distribution relies on a latent Beta Process controlling both the orders and outgoing connection probabilities of the nodes, and yields a probability distribution on sparse infinite graphs. The main advantage of the ICP over previously proposed Bayesian nonparametric priors for DAG structures is its greater flexibility. To the best of our knowledge, the ICP is the first Bayesian nonparametric model supporting every possible DAG. We demonstrate the usefulness of the ICP on learning the structure of deep generative sigmoid networks as well as convolutional neural networks.
Background Hardly Matters: Understanding Personality Attribution in Deep Residual Networks
Dec 20, 2019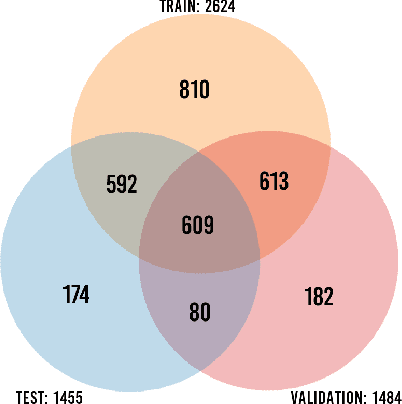
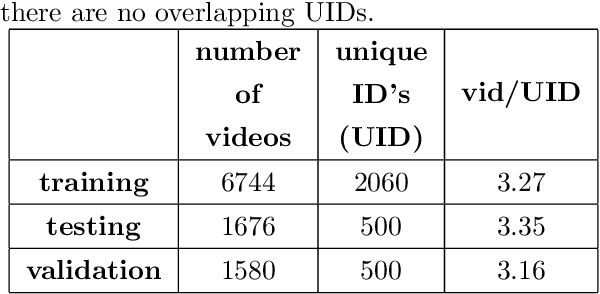

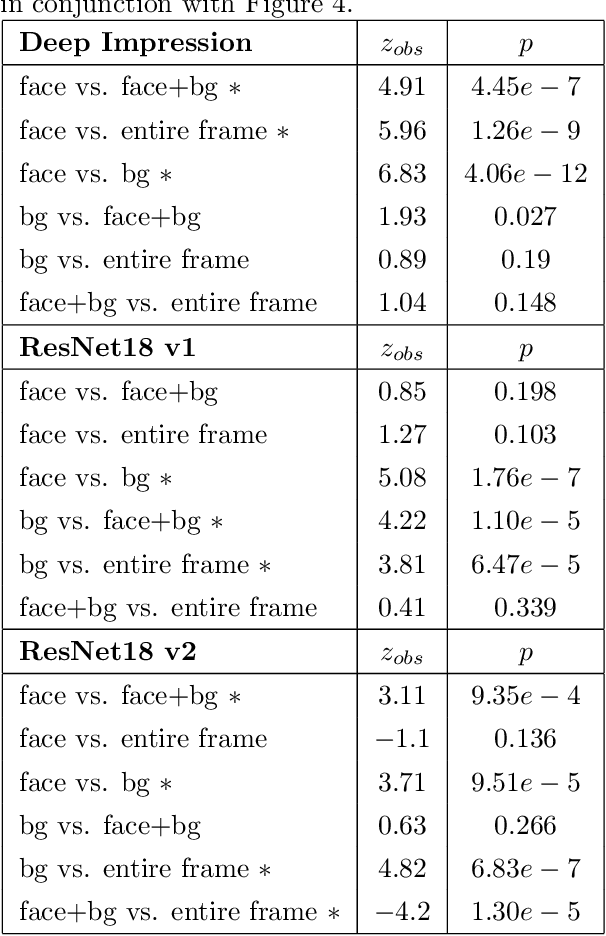
Perceived personality traits attributed to an individual do not have to correspond to their actual personality traits and may be determined in part by the context in which one encounters a person. These apparent traits determine, to a large extent, how other people will behave towards them. Deep neural networks are increasingly being used to perform automated personality attribution (e.g., job interviews). It is important that we understand the driving factors behind the predictions, in humans and in deep neural networks. This paper explicitly studies the effect of the image background on apparent personality prediction while addressing two important confounds present in existing literature; overlapping data splits and including facial information in the background. Surprisingly, we found no evidence that background information improves model predictions for apparent personality traits. In fact, when background is explicitly added to the input, a decrease in performance was measured across all models.
Temporal Factorization of 3D Convolutional Kernels
Dec 09, 2019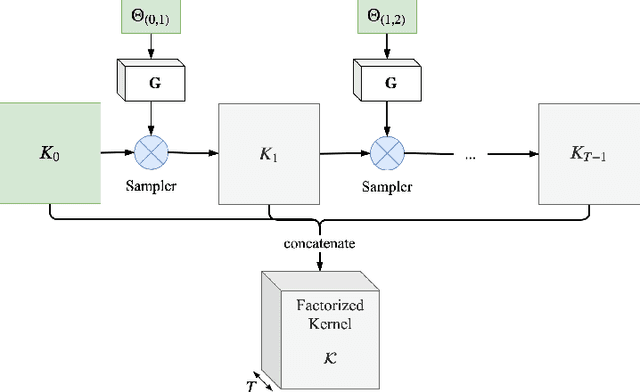


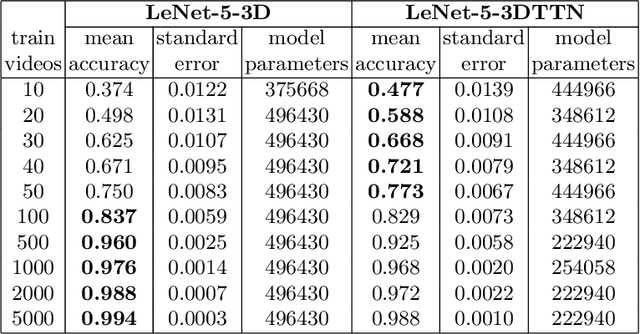
3D convolutional neural networks are difficult to train because they are parameter-expensive and data-hungry. To solve these problems we propose a simple technique for learning 3D convolutional kernels efficiently requiring less training data. We achieve this by factorizing the 3D kernel along the temporal dimension, reducing the number of parameters and making training from data more efficient. Additionally we introduce a novel dataset called Video-MNIST to demonstrate the performance of our method. Our method significantly outperforms the conventional 3D convolution in the low data regime (1 to 5 videos per class). Finally, our model achieves competitive results in the high data regime (>10 videos per class) using up to 45% fewer parameters.
k-GANs: Ensemble of Generative Models with Semi-Discrete Optimal Transport
Jul 09, 2019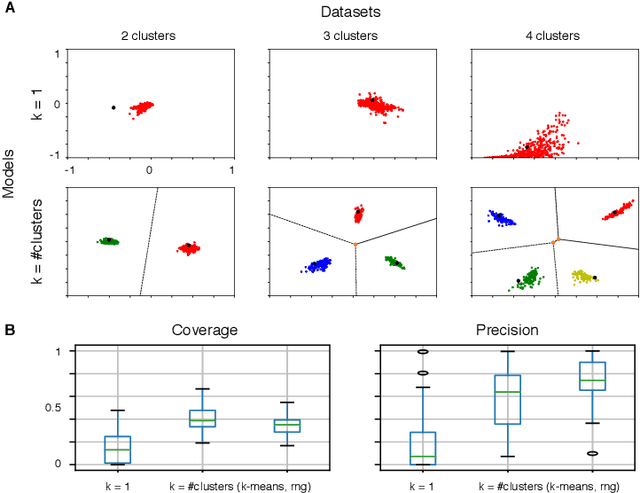
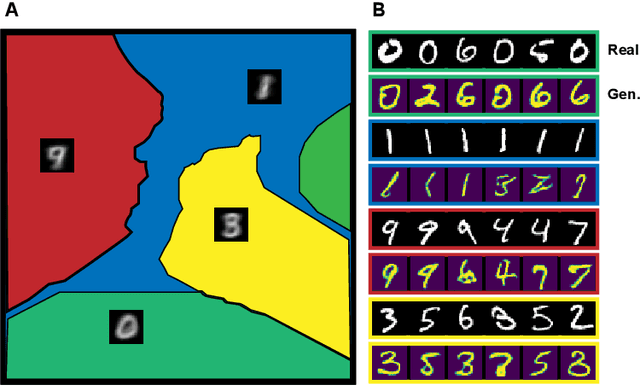

Generative adversarial networks (GANs) are the state of the art in generative modeling. Unfortunately, most GAN methods are susceptible to mode collapse, meaning that they tend to capture only a subset of the modes of the true distribution. A possible way of dealing with this problem is to use an ensemble of GANs, where (ideally) each network models a single mode. In this paper, we introduce a principled method for training an ensemble of GANs using semi-discrete optimal transport theory. In our approach, each generative network models the transportation map between a point mass (Dirac measure) and the restriction of the data distribution on a tile of a Voronoi tessellation that is defined by the location of the point masses. We iteratively train the generative networks and the point masses until convergence. The resulting k-GANs algorithm has strong theoretical connection with the k-medoids algorithm. In our experiments, we show that our ensemble method consistently outperforms baseline GANs.
Wasserstein Variational Inference
Jun 04, 2018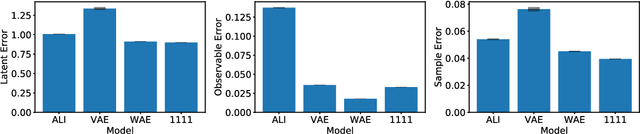
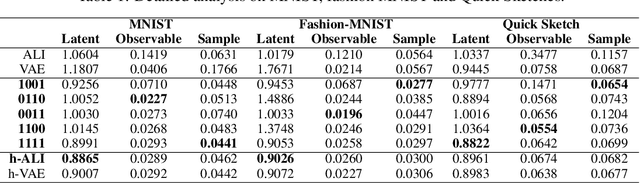

This paper introduces Wasserstein variational inference, a new form of approximate Bayesian inference based on optimal transport theory. Wasserstein variational inference uses a new family of divergences that includes both f-divergences and the Wasserstein distance as special cases. The gradients of the Wasserstein variational loss are obtained by backpropagating through the Sinkhorn iterations. This technique results in a very stable likelihood-free training method that can be used with implicit distributions and probabilistic programs. Using the Wasserstein variational inference framework, we introduce several new forms of autoencoders and test their robustness and performance against existing variational autoencoding techniques.
Forward Amortized Inference for Likelihood-Free Variational Marginalization
May 29, 2018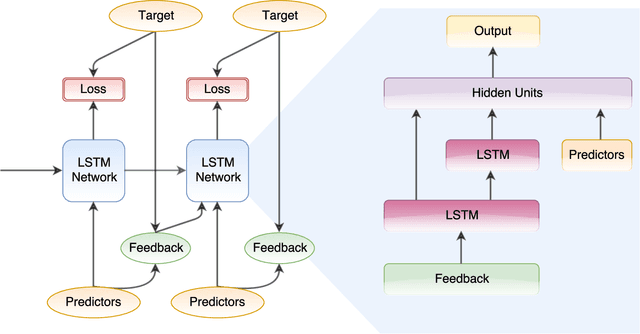
In this paper, we introduce a new form of amortized variational inference by using the forward KL divergence in a joint-contrastive variational loss. The resulting forward amortized variational inference is a likelihood-free method as its gradient can be sampled without bias and without requiring any evaluation of either the model joint distribution or its derivatives. We prove that our new variational loss is optimized by the exact posterior marginals in the fully factorized mean-field approximation, a property that is not shared with the more conventional reverse KL inference. Furthermore, we show that forward amortized inference can be easily marginalized over large families of latent variables in order to obtain a marginalized variational posterior. We consider two examples of variational marginalization. In our first example we train a Bayesian forecaster for predicting a simplified chaotic model of atmospheric convection. In the second example we train an amortized variational approximation of a Bayesian optimal classifier by marginalizing over the model space. The result is a powerful meta-classification network that can solve arbitrary classification problems without further training.
First Impressions: A Survey on Computer Vision-Based Apparent Personality Trait Analysis
Apr 21, 2018
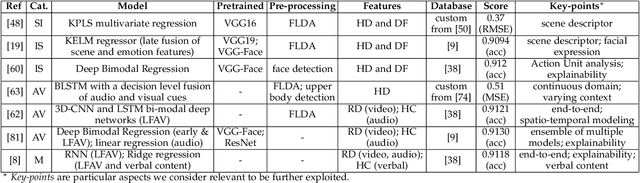
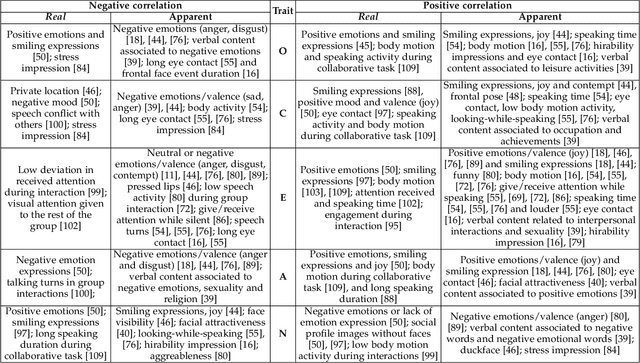
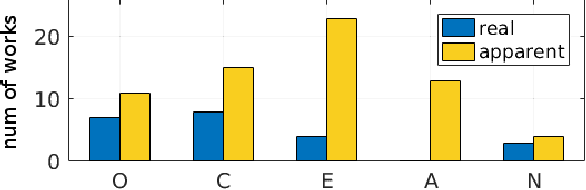
Personality analysis has been widely studied in psychology, neuropsychology, signal processing fields, among others. From the computing point of view, by far speech and text have been the most analyzed cues of information for analyzing personality. However, recently there has been an increasing interest form the computer vision community in analyzing personality starting from visual information. Recent computer vision approaches are able to accurately analyze human faces, body postures and behaviors, and use these information to infer apparent personality traits. Because of the overwhelming research interest in this topic, and of the potential impact that this sort of methods could have in society, we present in this paper an up-to-date review of existing computer vision-based visual and multimodal approaches for apparent personality trait recognition. We describe seminal and cutting edge works on the subject, discussing and comparing their distinctive features. More importantly, future venues of research in the field are identified and discussed. Furthermore, aspects on the subjectivity in data labeling/evaluation, as well as current datasets and challenges organized to push the research on the field are reviewed. Hence, the survey provides an up-to-date review of research progress in a wide range of aspects of this research theme.