 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecorrelated Soft Actor-Critic for Efficient Deep Reinforcement Learning
Jan 31, 2025



The effectiveness of credit assignment in reinforcement learning (RL) when dealing with high-dimensional data is influenced by the success of representation learning via deep neural networks, and has implications for the sample efficiency of deep RL algorithms. Input decorrelation has been previously introduced as a method to speed up optimization in neural networks, and has proven impactful in both efficient deep learning and as a method for effective representation learning for deep RL algorithms. We propose a novel approach to online decorrelation in deep RL based on the decorrelated backpropagation algorithm that seamlessly integrates the decorrelation process into the RL training pipeline. Decorrelation matrices are added to each layer, which are updated using a separate decorrelation learning rule that minimizes the total decorrelation loss across all layers, in parallel to minimizing the usual RL loss. We used our approach in combination with the soft actor-critic (SAC) method, which we refer to as decorrelated soft actor-critic (DSAC). Experiments on the Atari 100k benchmark with DSAC shows, compared to the regular SAC baseline, faster training in five out of the seven games tested and improved reward performance in two games with around 50% reduction in wall-clock time, while maintaining performance levels on the other games. These results demonstrate the positive impact of network-wide decorrelation in deep RL for speeding up its sample efficiency through more effective credit assignment.
Efficient Deep Reinforcement Learning with Predictive Processing Proximal Policy Optimization
Nov 11, 2022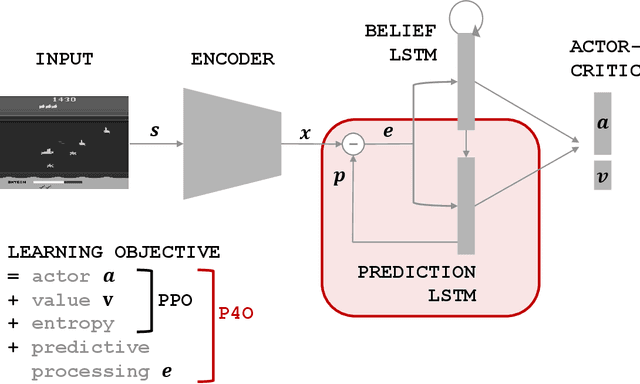

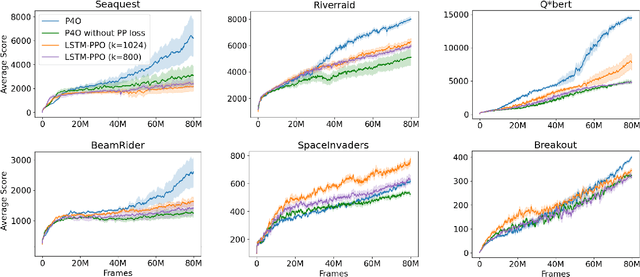
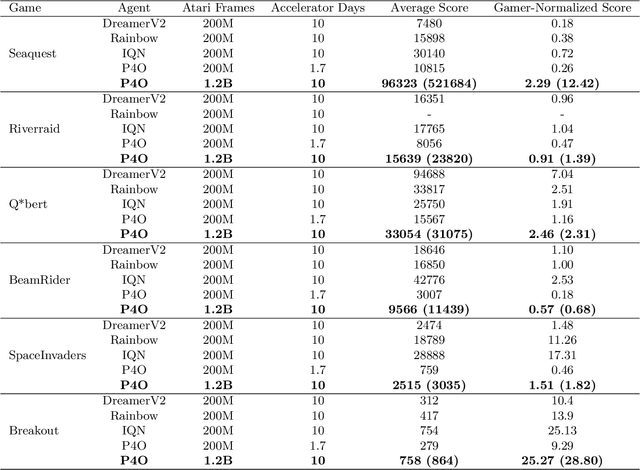
Advances in reinforcement learning (RL) often rely on massive compute resources and remain notoriously sample inefficient. In contrast, the human brain is able to efficiently learn effective control strategies using limited resources. This raises the question whether insights from neuroscience can be used to improve current RL methods. Predictive processing is a popular theoretical framework which maintains that the human brain is actively seeking to minimize surprise. We show that recurrent neural networks which predict their own sensory states can be leveraged to minimise surprise, yielding substantial gains in cumulative reward. Specifically, we present the Predictive Processing Proximal Policy Optimization (P4O) agent; an actor-critic reinforcement learning agent that applies predictive processing to a recurrent variant of the PPO algorithm by integrating a world model in its hidden state. P4O significantly outperforms a baseline recurrent variant of the PPO algorithm on multiple Atari games using a single GPU. It also outperforms other state-of-the-art agents given the same wall-clock time and exceeds human gamer performance on multiple games including Seaquest, which is a particularly challenging environment in the Atari domain. Altogether, our work underscores how insights from the field of neuroscience may support the development of more capable and efficient artificial agents.