 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Perspective on Optimization in Machine Learning and Neuroscience: From Gradient Descent to Neural Adaptation
Oct 21, 2025
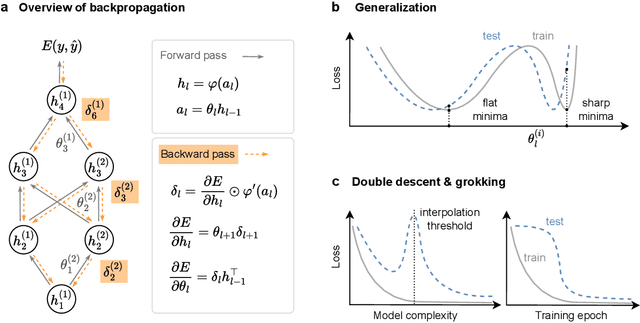

Iterative optimization is central to modern artificial intelligence (AI) and provides a crucial framework for understanding adaptive systems. This review provides a unified perspective on this subject, bridging classic theory with neural network training and biological learning. Although gradient-based methods, powered by the efficient but biologically implausible backpropagation (BP), dominate machine learning, their computational demands can hinder scalability in high-dimensional settings. In contrast, derivative-free or zeroth-order (ZO) optimization feature computationally lighter approaches that rely only on function evaluations and randomness. While generally less sample efficient, recent breakthroughs demonstrate that modern ZO methods can effectively approximate gradients and achieve performance competitive with BP in neural network models. This ZO paradigm is also particularly relevant for biology. Its core principles of random exploration (probing) and feedback-guided adaptation (reinforcing) parallel key mechanisms of biological learning, offering a mathematically principled perspective on how the brain learns. In this review, we begin by categorizing optimization approaches based on the order of derivative information they utilize, ranging from first-, second-, and higher-order gradient-based to ZO methods. We then explore how these methods are adapted to the unique challenges of neural network training and the resulting learning dynamics. Finally, we build upon these insights to view biological learning through an optimization lens, arguing that a ZO paradigm leverages the brain's intrinsic noise as a computational resource. This framework not only illuminates our understanding of natural intelligence but also holds vast implications for neuromorphic hardware, helping us design fast and energy-efficient AI systems that exploit intrinsic hardware noise.
Spiking neurons as predictive controllers of linear systems
Jul 22, 2025Neurons communicate with downstream systems via sparse and incredibly brief electrical pulses, or spikes. Using these events, they control various targets such as neuromuscular units, neurosecretory systems, and other neurons in connected circuits. This gave rise to the idea of spiking neurons as controllers, in which spikes are the control signal. Using instantaneous events directly as the control inputs, also called `impulse control', is challenging as it does not scale well to larger networks and has low analytical tractability. Therefore, current spiking control usually relies on filtering the spike signal to approximate analog control. This ultimately means spiking neural networks (SNNs) have to output a continuous control signal, necessitating continuous energy input into downstream systems. Here, we circumvent the need for rate-based representations, providing a scalable method for task-specific spiking control with sparse neural activity. In doing so, we take inspiration from both optimal control and neuroscience theory, and define a spiking rule where spikes are only emitted if they bring a dynamical system closer to a target. From this principle, we derive the required connectivity for an SNN, and show that it can successfully control linear systems. We show that for physically constrained systems, predictive control is required, and the control signal ends up exploiting the passive dynamics of the downstream system to reach a target. Finally, we show that the control method scales to both high-dimensional networks and systems. Importantly, in all cases, we maintain a closed-form mathematical derivation of the network connectivity, the network dynamics and the control objective. This work advances the understanding of SNNs as biologically-inspired controllers, providing insight into how real neurons could exert control, and enabling applications in neuromorphic hardware design.
Real-Time Decorrelation-Based Anomaly Detection for Multivariate Time Series
Jul 10, 2025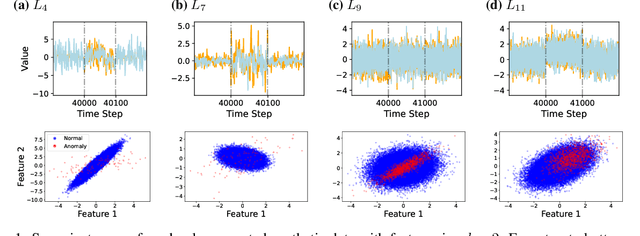
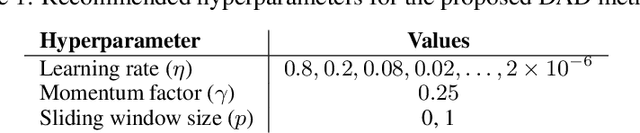
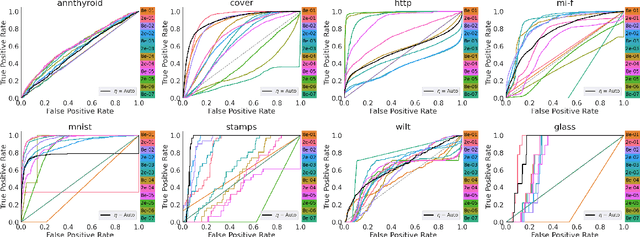
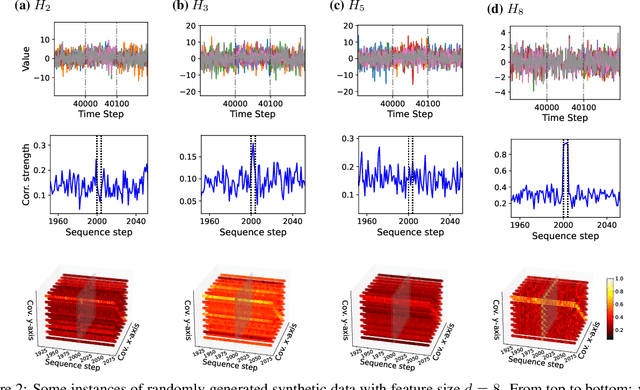
Anomaly detection (AD) plays a vital role across a wide range of real-world domains by identifying data instances that deviate from expected patterns, potentially signaling critical events such as system failures, fraudulent activities, or rare medical conditions. The demand for real-time AD has surged with the rise of the (Industrial) Internet of Things, where massive volumes of multivariate sensor data must be processed instantaneously. Real-time AD requires methods that not only handle high-dimensional streaming data but also operate in a single-pass manner, without the burden of storing historical instances, thereby ensuring minimal memory usage and fast decision-making. We propose DAD, a novel real-time decorrelation-based anomaly detection method for multivariate time series, based on an online decorrelation learning approach. Unlike traditional proximity-based or reconstruction-based detectors that process entire data or windowed instances, DAD dynamically learns and monitors the correlation structure of data sample by sample in a single pass, enabling efficient and effective detection. To support more realistic benchmarking practices, we also introduce a practical hyperparameter tuning strategy tailored for real-time anomaly detection scenarios. Extensive experiments on widely used benchmark datasets demonstrate that DAD achieves the most consistent and superior performance across diverse anomaly types compared to state-of-the-art methods. Crucially, its robustness to increasing dimensionality makes it particularly well-suited for real-time, high-dimensional data streams. Ultimately, DAD not only strikes an optimal balance between detection efficacy and computational efficiency but also sets a new standard for real-time, memory-constrained anomaly detection.
Probabilistic Pontryagin's Maximum Principle for Continuous-Time Model-Based Reinforcement Learning
Apr 03, 2025Without exact knowledge of the true system dynamics, optimal control of non-linear continuous-time systems requires careful treatment of epistemic uncertainty. In this work, we propose a probabilistic extension to Pontryagin's maximum principle by minimizing the mean Hamiltonian with respect to epistemic uncertainty. We show minimization of the mean Hamiltonian is a necessary optimality condition when optimizing the mean cost, and propose a multiple shooting numerical method scalable to large-scale probabilistic dynamical models, including ensemble neural ordinary differential equations. Comparisons against state-of-the-art methods in online and offline model-based reinforcement learning tasks show that our probabilistic Hamiltonian formulation leads to reduced trial costs in offline settings and achieves competitive performance in online scenarios. By bridging optimal control and reinforcement learning, our approach offers a principled and practical framework for controlling uncertain systems with learned dynamics.
Noise-based reward-modulated learning
Mar 31, 2025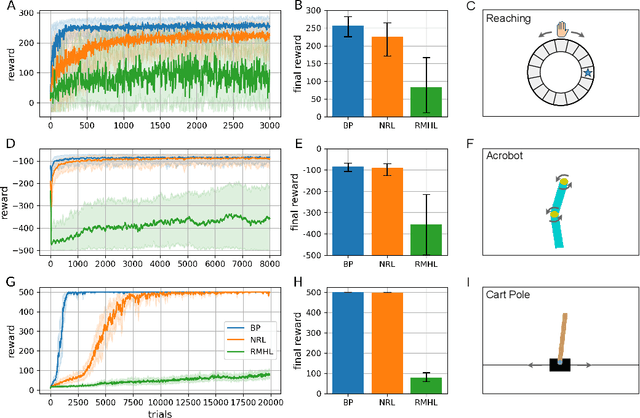

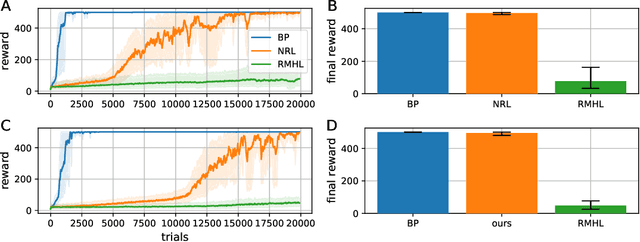

Recent advances in reinforcement learning (RL) have led to significant improvements in task performance. However, training neural networks in an RL regime is typically achieved in combination with backpropagation, limiting their applicability in resource-constrained environments or when using non-differentiable neural networks. While noise-based alternatives like reward-modulated Hebbian learning (RMHL) have been proposed, their performance has remained limited, especially in scenarios with delayed rewards, which require retrospective credit assignment over time. Here, we derive a novel noise-based learning rule that addresses these challenges. Our approach combines directional derivative theory with Hebbian-like updates to enable efficient, gradient-free learning in RL. It features stochastic noisy neurons which can approximate gradients, and produces local synaptic updates modulated by a global reward signal. Drawing on concepts from neuroscience, our method uses reward prediction error as its optimization target to generate increasingly advantageous behavior, and incorporates an eligibility trace to facilitate temporal credit assignment in environments with delayed rewards. Its formulation relies on local information alone, making it compatible with implementations in neuromorphic hardware. Experimental validation shows that our approach significantly outperforms RMHL and is competitive with BP-based baselines, highlighting the promise of noise-based, biologically inspired learning for low-power and real-time applications.
Probabilistic Forecasting via Autoregressive Flow Matching
Mar 13, 2025

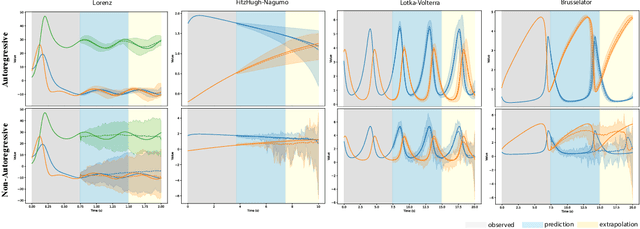

In this work, we propose FlowTime, a generative model for probabilistic forecasting of multivariate timeseries data. Given historical measurements and optional future covariates, we formulate forecasting as sampling from a learned conditional distribution over future trajectories. Specifically, we decompose the joint distribution of future observations into a sequence of conditional densities, each modeled via a shared flow that transforms a simple base distribution into the next observation distribution, conditioned on observed covariates. To achieve this, we leverage the flow matching (FM) framework, enabling scalable and simulation-free learning of these transformations. By combining this factorization with the FM objective, FlowTime retains the benefits of autoregressive models -- including strong extrapolation performance, compact model size, and well-calibrated uncertainty estimates -- while also capturing complex multi-modal conditional distributions, as seen in modern transport-based generative models. We demonstrate the effectiveness of FlowTime on multiple dynamical systems and real-world forecasting tasks.
Decorrelated Soft Actor-Critic for Efficient Deep Reinforcement Learning
Jan 31, 2025



The effectiveness of credit assignment in reinforcement learning (RL) when dealing with high-dimensional data is influenced by the success of representation learning via deep neural networks, and has implications for the sample efficiency of deep RL algorithms. Input decorrelation has been previously introduced as a method to speed up optimization in neural networks, and has proven impactful in both efficient deep learning and as a method for effective representation learning for deep RL algorithms. We propose a novel approach to online decorrelation in deep RL based on the decorrelated backpropagation algorithm that seamlessly integrates the decorrelation process into the RL training pipeline. Decorrelation matrices are added to each layer, which are updated using a separate decorrelation learning rule that minimizes the total decorrelation loss across all layers, in parallel to minimizing the usual RL loss. We used our approach in combination with the soft actor-critic (SAC) method, which we refer to as decorrelated soft actor-critic (DSAC). Experiments on the Atari 100k benchmark with DSAC shows, compared to the regular SAC baseline, faster training in five out of the seven games tested and improved reward performance in two games with around 50% reduction in wall-clock time, while maintaining performance levels on the other games. These results demonstrate the positive impact of network-wide decorrelation in deep RL for speeding up its sample efficiency through more effective credit assignment.
Leveraging Spatial Cues from Cochlear Implant Microphones to Efficiently Enhance Speech Separation in Real-World Listening Scenes
Jan 24, 2025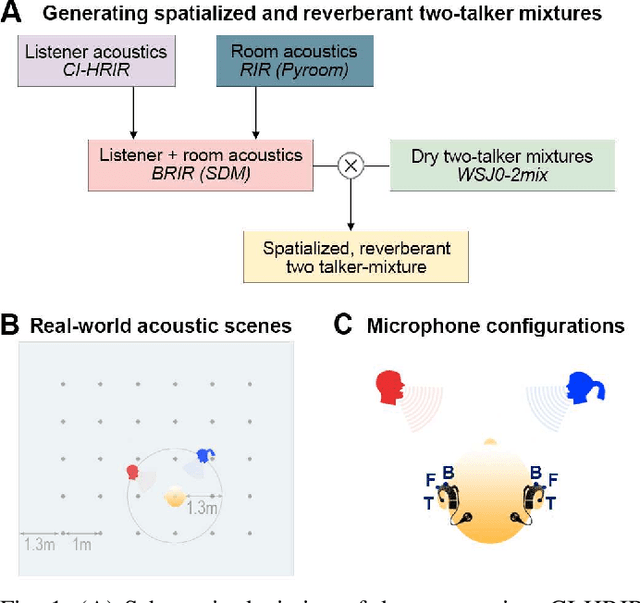
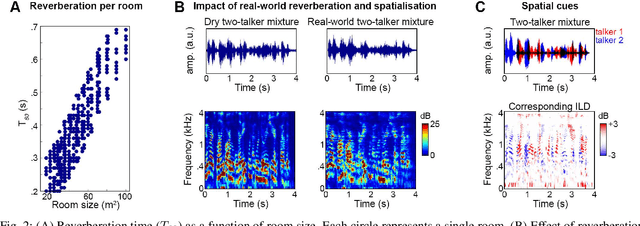
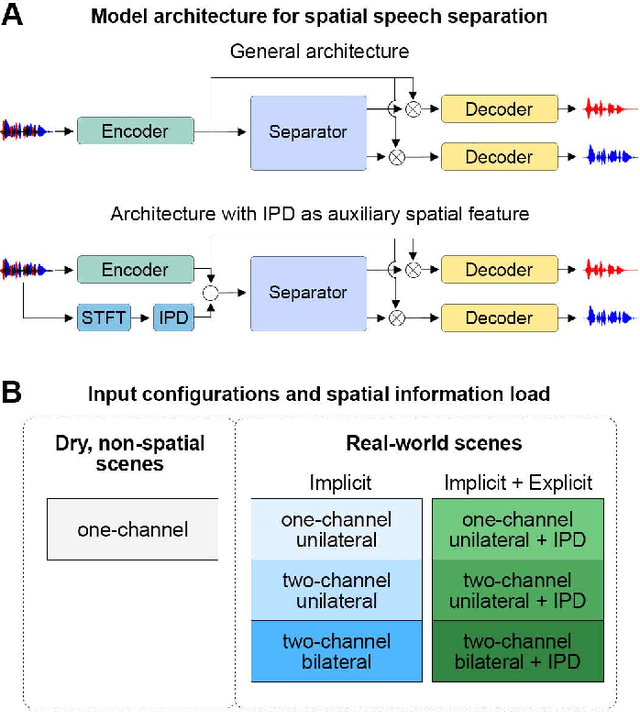
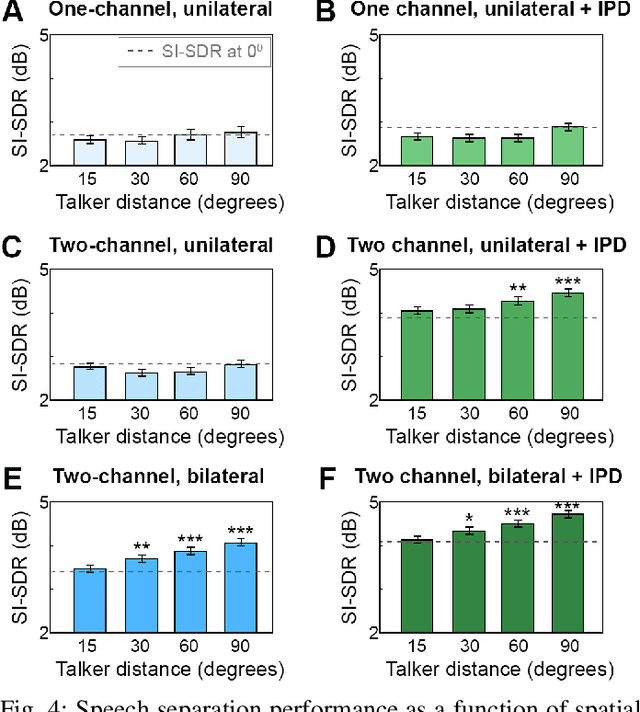
Speech separation approaches for single-channel, dry speech mixtures have significantly improved. However, real-world spatial and reverberant acoustic environments remain challenging, limiting the effectiveness of these approaches for assistive hearing devices like cochlear implants (CIs). To address this, we quantify the impact of real-world acoustic scenes on speech separation and explore how spatial cues can enhance separation quality efficiently. We analyze performance based on implicit spatial cues (inherent in the acoustic input and learned by the model) and explicit spatial cues (manually calculated spatial features added as auxiliary inputs). Our findings show that spatial cues (both implicit and explicit) improve separation for mixtures with spatially separated and nearby talkers. Furthermore, spatial cues enhance separation when spectral cues are ambiguous, such as when voices are similar. Explicit spatial cues are particularly beneficial when implicit spatial cues are weak. For instance, single CI microphone recordings provide weaker implicit spatial cues than bilateral CIs, but even single CIs benefit from explicit cues. These results emphasize the importance of training models on real-world data to improve generalizability in everyday listening scenarios. Additionally, our statistical analyses offer insights into how data properties influence model performance, supporting the development of efficient speech separation approaches for CIs and other assistive devices in real-world settings.
Noise-based Local Learning using Stochastic Magnetic Tunnel Junctions
Dec 17, 2024



Brain-inspired learning in physical hardware has enormous potential to learn fast at minimal energy expenditure. One of the characteristics of biological learning systems is their ability to learn in the presence of various noise sources. Inspired by this observation, we introduce a novel noise-based learning approach for physical systems implementing multi-layer neural networks. Simulation results show that our approach allows for effective learning whose performance approaches that of the conventional effective yet energy-costly backpropagation algorithm. Using a spintronics hardware implementation, we demonstrate experimentally that learning can be achieved in a small network composed of physical stochastic magnetic tunnel junctions. These results provide a path towards efficient learning in general physical systems which embraces rather than mitigates the noise inherent in physical devices.
Fractional Order Distributed Optimization
Dec 03, 2024

Distributed optimization is fundamental to modern machine learning applications like federated learning, but existing methods often struggle with ill-conditioned problems and face stability-versus-speed tradeoffs. We introduce fractional order distributed optimization (FrODO); a theoretically-grounded framework that incorporates fractional-order memory terms to enhance convergence properties in challenging optimization landscapes. Our approach achieves provable linear convergence for any strongly connected network. Through empirical validation, our results suggest that FrODO achieves up to 4 times faster convergence versus baselines on ill-conditioned problems and 2-3 times speedup in federated neural network training, while maintaining stability and theoretical guarantees.