 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrnstein-Uhlenbeck Adaptation as a Mechanism for Learning in Brains and Machines
Oct 17, 2024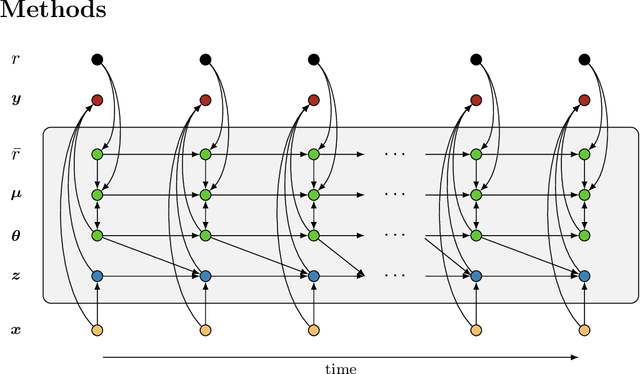
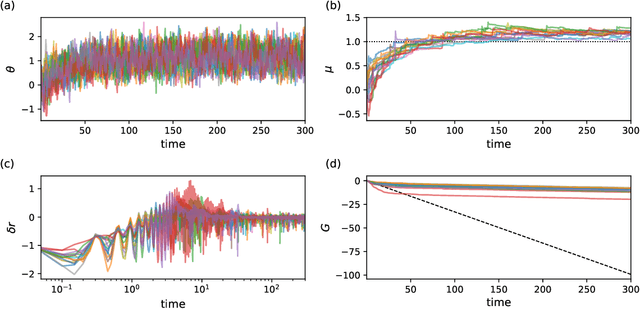
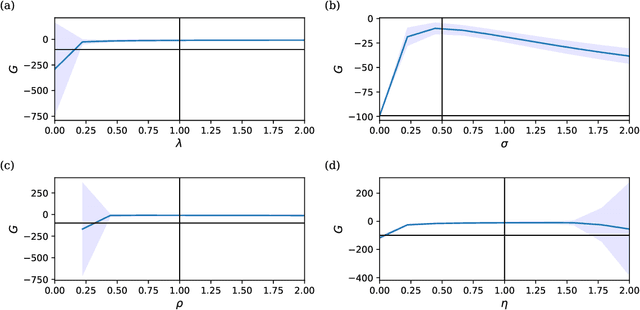
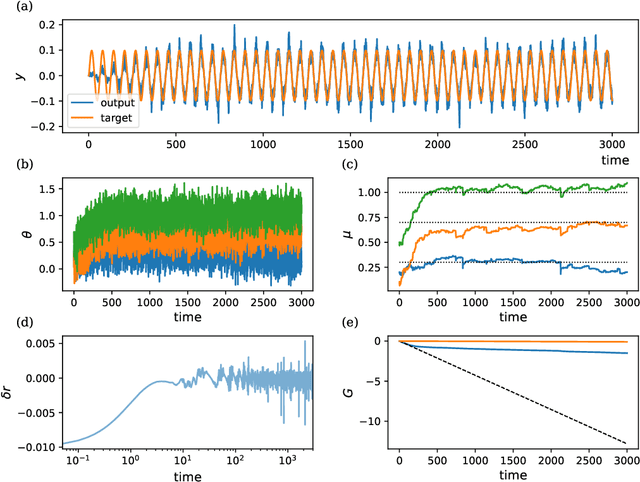
Learning is a fundamental property of intelligent systems, observed across biological organisms and engineered systems. While modern intelligent systems typically rely on gradient descent for learning, the need for exact gradients and complex information flow makes its implementation in biological and neuromorphic systems challenging. This has motivated the exploration of alternative learning mechanisms that can operate locally and do not rely on exact gradients. In this work, we introduce a novel approach that leverages noise in the parameters of the system and global reinforcement signals. Using an Ornstein-Uhlenbeck process with adaptive dynamics, our method balances exploration and exploitation during learning, driven by deviations from error predictions, akin to reward prediction error. Operating in continuous time, Orstein-Uhlenbeck adaptation (OUA) is proposed as a general mechanism for learning dynamic, time-evolving environments. We validate our approach across diverse tasks, including supervised learning and reinforcement learning in feedforward and recurrent systems. Additionally, we demonstrate that it can perform meta-learning, adjusting hyper-parameters autonomously. Our results indicate that OUA provides a viable alternative to traditional gradient-based methods, with potential applications in neuromorphic computing. It also hints at a possible mechanism for noise-driven learning in the brain, where stochastic neurotransmitter release may guide synaptic adjustments.
Perturbation-based Learning for Recurrent Neural Networks
May 14, 2024



Recurrent neural networks (RNNs) hold immense potential for computations due to their Turing completeness and sequential processing capabilities, yet existing methods for their training encounter efficiency challenges. Backpropagation through time (BPTT), the prevailing method, extends the backpropagation (BP) algorithm by unrolling the RNN over time. However, this approach suffers from significant drawbacks, including the need to interleave forward and backward phases and store exact gradient information. Furthermore, BPTT has been shown to struggle with propagating gradient information for long sequences, leading to vanishing gradients. An alternative strategy to using gradient-based methods like BPTT involves stochastically approximating gradients through perturbation-based methods. This learning approach is exceptionally simple, necessitating only forward passes in the network and a global reinforcement signal as feedback. Despite its simplicity, the random nature of its updates typically leads to inefficient optimization, limiting its effectiveness in training neural networks. In this study, we present a new approach to perturbation-based learning in RNNs whose performance is competitive with BPTT, while maintaining the inherent advantages over gradient-based learning. To this end, we extend the recently introduced activity-based node perturbation (ANP) method to operate in the time domain, leading to more efficient learning and generalization. Subsequently, we conduct a range of experiments to validate our approach. Our results show similar performance, convergence time and scalability when compared to BPTT, strongly outperforming standard node perturbation and weight perturbation methods. These findings suggest that perturbation-based learning methods offer a versatile alternative to gradient-based methods for training RNNs.
Broad-UNet: Multi-scale feature learning for nowcasting tasks
Feb 12, 2021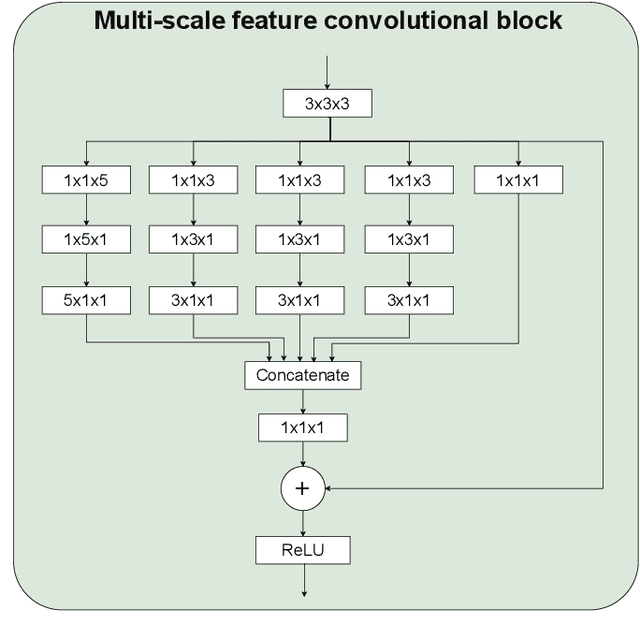

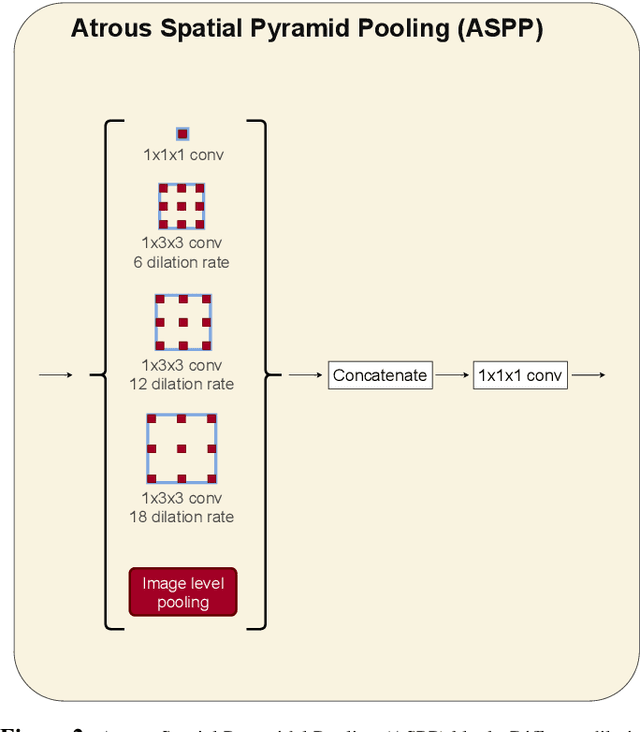
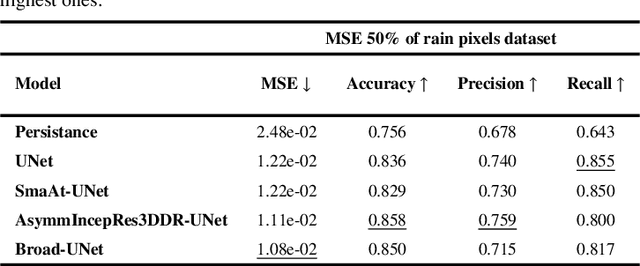
Weather nowcasting consists of predicting meteorological components in the short term at high spatial resolutions. Due to its influence in many human activities, accurate nowcasting has recently gained plenty of attention. In this paper, we treat the nowcasting problem as an image-to-image translation problem using satellite imagery. We introduce Broad-UNet, a novel architecture based on the core UNet model, to efficiently address this problem. In particular, the proposed Broad-UNet is equipped with asymmetric parallel convolutions as well as Atrous Spatial Pyramid Pooling (ASPP) module. In this way, The the Broad-UNet model learns more complex patterns by combining multi-scale features while using fewer parameters than the core UNet model. The proposed model is applied on two different nowcasting tasks, i.e. precipitation maps and cloud cover nowcasting. The obtained numerical results show that the introduced Broad-UNet model performs more accurate predictions compared to the other examined architectures.
Deep brain state classification of MEG data
Jul 04, 2020

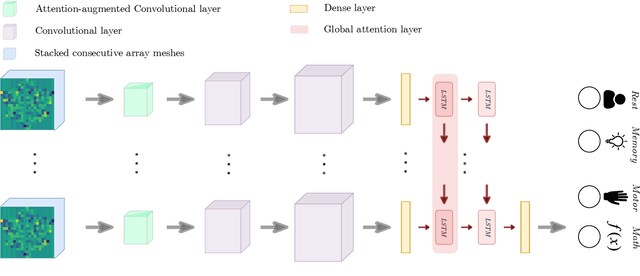
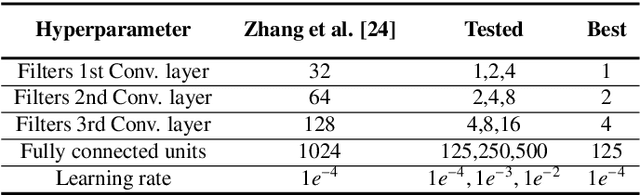
Neuroimaging techniques have shown to be useful when studying the brain's activity. This paper uses Magnetoencephalography (MEG) data, provided by the Human Connectome Project (HCP), in combination with various deep artificial neural network models to perform brain decoding. More specifically, here we investigate to which extent can we infer the task performed by a subject based on its MEG data. Three models based on compact convolution, combined convolutional and long short-term architecture as well as a model based on multi-view learning that aims at fusing the outputs of the two stream networks are proposed and examined. These models exploit the spatio-temporal MEG data for learning new representations that are used to decode the relevant tasks across subjects. In order to realize the most relevant features of the input signals, two attention mechanisms, i.e. self and global attention, are incorporated in all the models. The experimental results of cross subject multi-class classification on the studied MEG dataset show that the inclusion of attention improves the generalization of the models across subjects.