 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeasibility of Time-Domain DNN-Based Speech Enhancement on Embedded FPGA for Hearing Aid
Jun 02, 2026Hearing aids impose strict latency and power constraints that current DNN-based speech enhancement systems struggle to meet on embedded hardware. We characterize this gap by deploying both speech separation and denoising using the lightweight SuDoRM-RF++ architecture on the AMD-Xilinx Kria KV260, evaluated at FP32 and 16-bit fixed-point precision for each task. Across these configurations, first-sample latency tracks with on-chip parameter caching rather than arithmetic throughput, identifying data movement as the primary bottleneck. Precision reduction halves the model memory footprint without compromising objective speech quality. The fixed-point denoising accelerator achieves a first-sample latency of 9.7~ms, meeting the 10~ms clinical threshold, while speech separation reaches 16.0~ms. These measurements establish concrete resource requirements for embedded DNN-based speech enhancement and quantify the remaining gap to hearing aid deployment.
Speech Separation for Hearing-Impaired Children in the Classroom
Nov 10, 2025Classroom environments are particularly challenging for children with hearing impairments, where background noise, multiple talkers, and reverberation degrade speech perception. These difficulties are greater for children than adults, yet most deep learning speech separation models for assistive devices are developed using adult voices in simplified, low-reverberation conditions. This overlooks both the higher spectral similarity of children's voices, which weakens separation cues, and the acoustic complexity of real classrooms. We address this gap using MIMO-TasNet, a compact, low-latency, multi-channel architecture suited for real-time deployment in bilateral hearing aids or cochlear implants. We simulated naturalistic classroom scenes with moving child-child and child-adult talker pairs under varying noise and distance conditions. Training strategies tested how well the model adapts to children's speech through spatial cues. Models trained on adult speech, classroom data, and finetuned variants were compared to assess data-efficient adaptation. Results show that adult-trained models perform well in clean scenes, but classroom-specific training greatly improves separation quality. Finetuning with only half the classroom data achieved comparable gains, confirming efficient transfer learning. Training with diffuse babble noise further enhanced robustness, and the model preserved spatial awareness while generalizing to unseen distances. These findings demonstrate that spatially aware architectures combined with targeted adaptation can improve speech accessibility for children in noisy classrooms, supporting future on-device assistive technologies.
Leveraging Spatial Cues from Cochlear Implant Microphones to Efficiently Enhance Speech Separation in Real-World Listening Scenes
Jan 24, 2025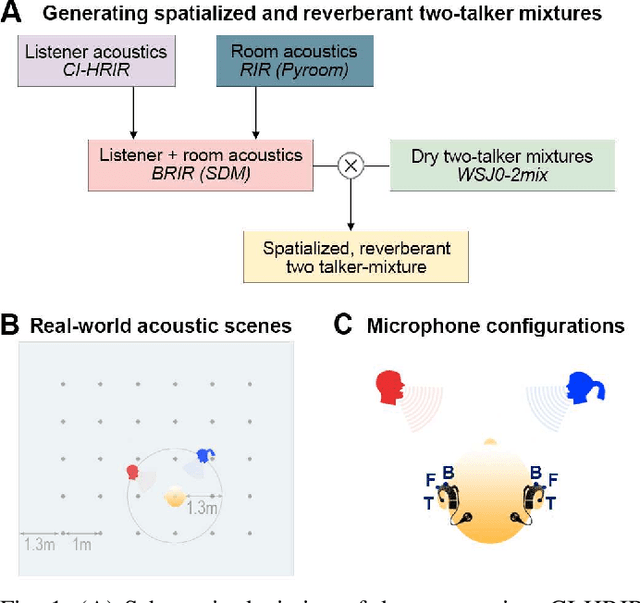
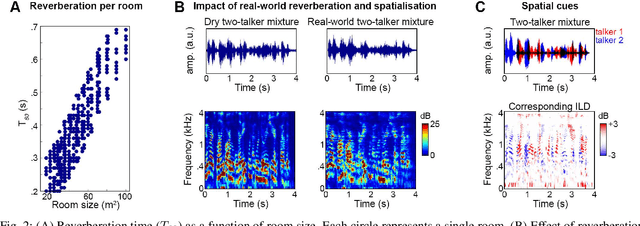
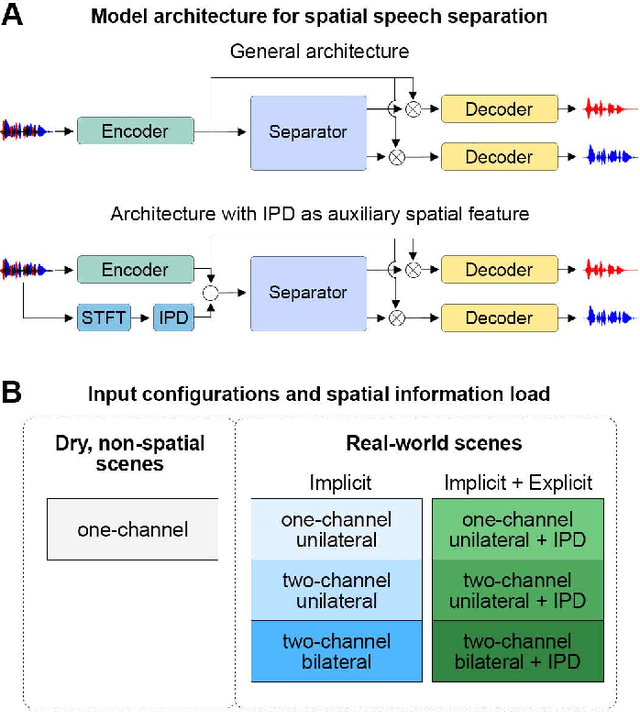
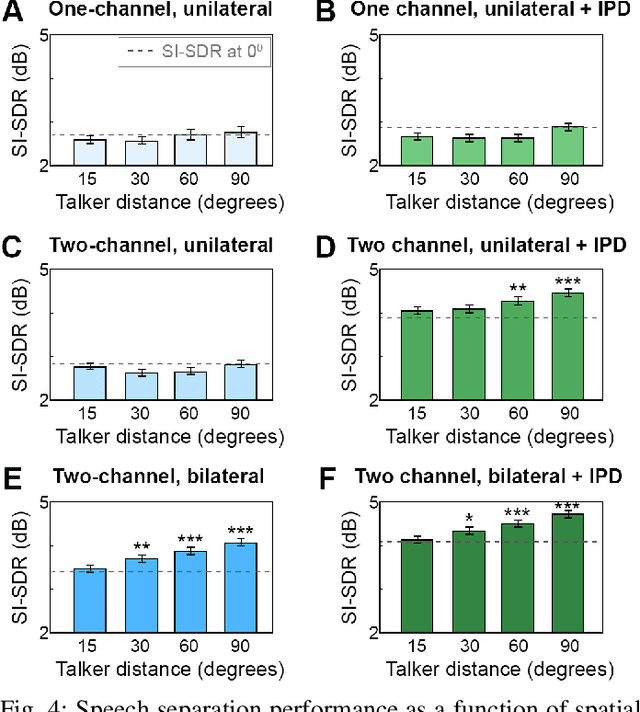
Speech separation approaches for single-channel, dry speech mixtures have significantly improved. However, real-world spatial and reverberant acoustic environments remain challenging, limiting the effectiveness of these approaches for assistive hearing devices like cochlear implants (CIs). To address this, we quantify the impact of real-world acoustic scenes on speech separation and explore how spatial cues can enhance separation quality efficiently. We analyze performance based on implicit spatial cues (inherent in the acoustic input and learned by the model) and explicit spatial cues (manually calculated spatial features added as auxiliary inputs). Our findings show that spatial cues (both implicit and explicit) improve separation for mixtures with spatially separated and nearby talkers. Furthermore, spatial cues enhance separation when spectral cues are ambiguous, such as when voices are similar. Explicit spatial cues are particularly beneficial when implicit spatial cues are weak. For instance, single CI microphone recordings provide weaker implicit spatial cues than bilateral CIs, but even single CIs benefit from explicit cues. These results emphasize the importance of training models on real-world data to improve generalizability in everyday listening scenarios. Additionally, our statistical analyses offer insights into how data properties influence model performance, supporting the development of efficient speech separation approaches for CIs and other assistive devices in real-world settings.
Audio-Driven Reinforcement Learning for Head-Orientation in Naturalistic Environments
Sep 16, 2024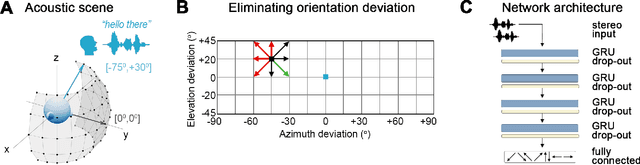
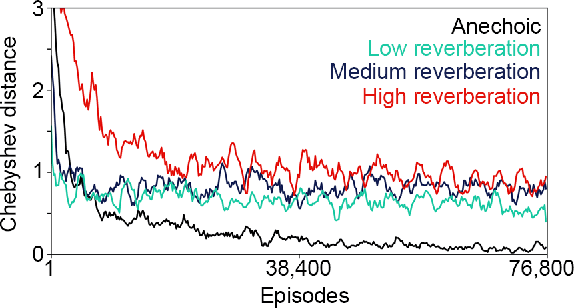
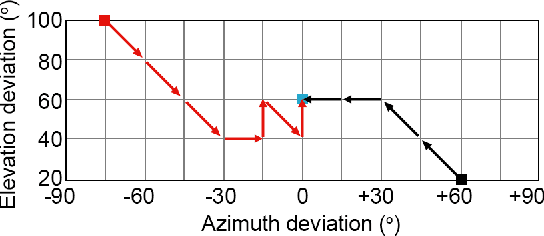
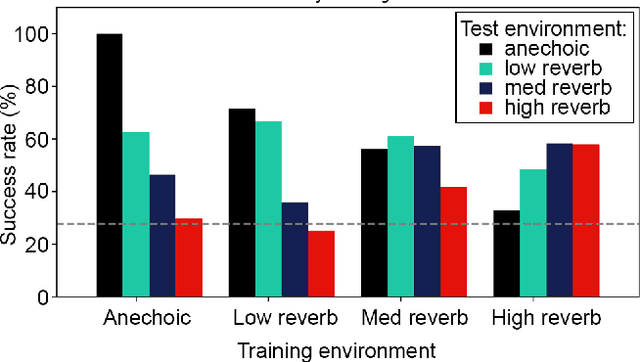
Although deep reinforcement learning (DRL) approaches in audio signal processing have seen substantial progress in recent years, audio-driven DRL for tasks such as navigation, gaze control and head-orientation control in the context of human-robot interaction have received little attention. Here, we propose an audio-driven DRL framework in which we utilise deep Q-learning to develop an autonomous agent that orients towards a talker in the acoustic environment based on stereo speech recordings. Our results show that the agent learned to perform the task at a near perfect level when trained on speech segments in anechoic environments (that is, without reverberation). The presence of reverberation in naturalistic acoustic environments affected the agent's performance, although the agent still substantially outperformed a baseline, randomly acting agent. Finally, we quantified the degree of generalization of the proposed DRL approach across naturalistic acoustic environments. Our experiments revealed that policies learned by agents trained on medium or high reverb environments generalized to low reverb environments, but policies learned by agents trained on anechoic or low reverb environments did not generalize to medium or high reverb environments. Taken together, this study demonstrates the potential of audio-driven DRL for tasks such as head-orientation control and highlights the need for training strategies that enable robust generalization across environments for real-world audio-driven DRL applications.
BAST: Binaural Audio Spectrogram Transformer for Binaural Sound Localization
Jul 08, 2022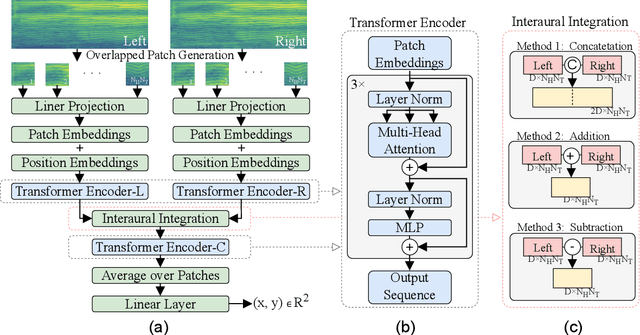
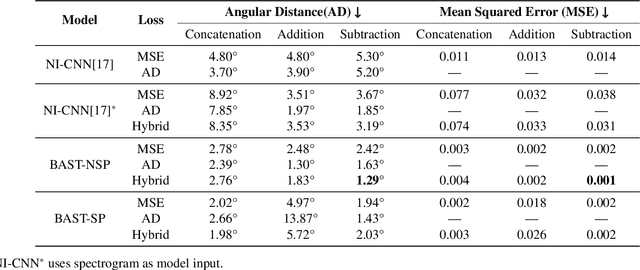
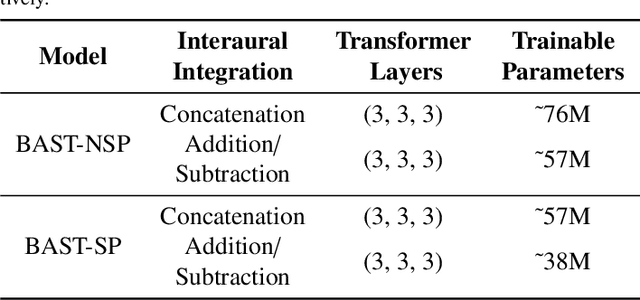
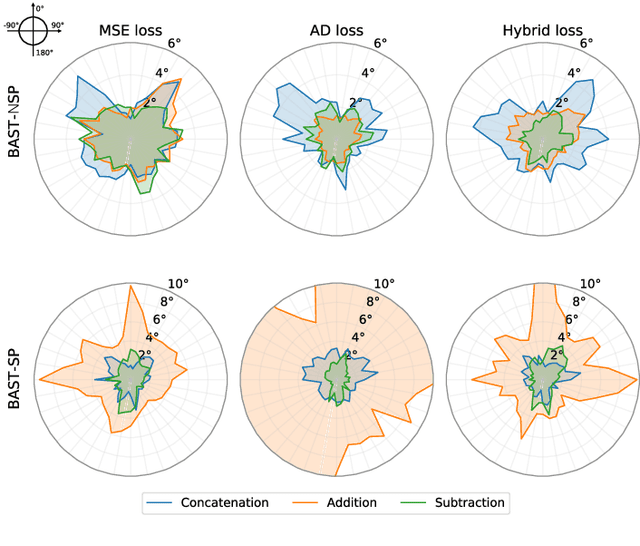
Accurate sound localization in a reverberation environment is essential for human auditory perception. Recently, Convolutional Neural Networks (CNNs) have been utilized to model the binaural human auditory pathway. However, CNN shows barriers in capturing the global acoustic features. To address this issue, we propose a novel end-to-end Binaural Audio Spectrogram Transformer (BAST) model to predict the sound azimuth in both anechoic and reverberation environments. Two modes of implementation, i.e. BAST-SP and BAST-NSP corresponding to BAST model with shared and non-shared parameters respectively, are explored. Our model with subtraction interaural integration and hybrid loss achieves an angular distance of 1.29 degrees and a Mean Square Error of 1e-3 at all azimuths, significantly surpassing CNN based model. The exploratory analysis of the BAST's performance on the left-right hemifields and anechoic and reverberation environments shows its generalization ability as well as the feasibility of binaural Transformers in sound localization. Furthermore, the analysis of the attention maps is provided to give additional insights on the interpretation of the localization process in a natural reverberant environment.