 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadiology Report Conditional 3D CT Generation with Multi Encoder Latent diffusion Model
Sep 18, 2025


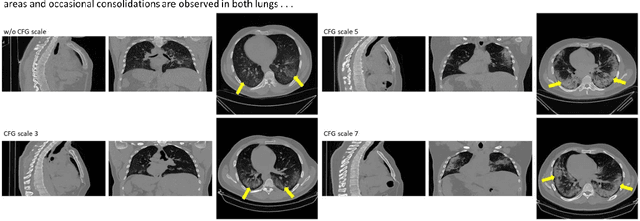
Text to image latent diffusion models have recently advanced medical image synthesis, but applications to 3D CT generation remain limited. Existing approaches rely on simplified prompts, neglecting the rich semantic detail in full radiology reports, which reduces text image alignment and clinical fidelity. We propose Report2CT, a radiology report conditional latent diffusion framework for synthesizing 3D chest CT volumes directly from free text radiology reports, incorporating both findings and impression sections using multiple text encoder. Report2CT integrates three pretrained medical text encoders (BiomedVLP CXR BERT, MedEmbed, and ClinicalBERT) to capture nuanced clinical context. Radiology reports and voxel spacing information condition a 3D latent diffusion model trained on 20000 CT volumes from the CT RATE dataset. Model performance was evaluated using Frechet Inception Distance (FID) for real synthetic distributional similarity and CLIP based metrics for semantic alignment, with additional qualitative and quantitative comparisons against GenerateCT model. Report2CT generated anatomically consistent CT volumes with excellent visual quality and text image alignment. Multi encoder conditioning improved CLIP scores, indicating stronger preservation of fine grained clinical details in the free text radiology reports. Classifier free guidance further enhanced alignment with only a minor trade off in FID. We ranked first in the VLM3D Challenge at MICCAI 2025 on Text Conditional CT Generation and achieved state of the art performance across all evaluation metrics. By leveraging complete radiology reports and multi encoder text conditioning, Report2CT advances 3D CT synthesis, producing clinically faithful and high quality synthetic data.
Explainable Anatomy-Guided AI for Prostate MRI: Foundation Models and In Silico Clinical Trials for Virtual Biopsy-based Risk Assessment
May 23, 2025We present a fully automated, anatomically guided deep learning pipeline for prostate cancer (PCa) risk stratification using routine MRI. The pipeline integrates three key components: an nnU-Net module for segmenting the prostate gland and its zones on axial T2-weighted MRI; a classification module based on the UMedPT Swin Transformer foundation model, fine-tuned on 3D patches with optional anatomical priors and clinical data; and a VAE-GAN framework for generating counterfactual heatmaps that localize decision-driving image regions. The system was developed using 1,500 PI-CAI cases for segmentation and 617 biparametric MRIs with metadata from the CHAIMELEON challenge for classification (split into 70% training, 10% validation, and 20% testing). Segmentation achieved mean Dice scores of 0.95 (gland), 0.94 (peripheral zone), and 0.92 (transition zone). Incorporating gland priors improved AUC from 0.69 to 0.72, with a three-scale ensemble achieving top performance (AUC = 0.79, composite score = 0.76), outperforming the 2024 CHAIMELEON challenge winners. Counterfactual heatmaps reliably highlighted lesions within segmented regions, enhancing model interpretability. In a prospective multi-center in-silico trial with 20 clinicians, AI assistance increased diagnostic accuracy from 0.72 to 0.77 and Cohen's kappa from 0.43 to 0.53, while reducing review time per case by 40%. These results demonstrate that anatomy-aware foundation models with counterfactual explainability can enable accurate, interpretable, and efficient PCa risk assessment, supporting their potential use as virtual biopsies in clinical practice.
Counterfactuals and Uncertainty-Based Explainable Paradigm for the Automated Detection and Segmentation of Renal Cysts in Computed Tomography Images: A Multi-Center Study
Aug 07, 2024Routine computed tomography (CT) scans often detect a wide range of renal cysts, some of which may be malignant. Early and precise localization of these cysts can significantly aid quantitative image analysis. Current segmentation methods, however, do not offer sufficient interpretability at the feature and pixel levels, emphasizing the necessity for an explainable framework that can detect and rectify model inaccuracies. We developed an interpretable segmentation framework and validated it on a multi-centric dataset. A Variational Autoencoder Generative Adversarial Network (VAE-GAN) was employed to learn the latent representation of 3D input patches and reconstruct input images. Modifications in the latent representation using the gradient of the segmentation model generated counterfactual explanations for varying dice similarity coefficients (DSC). Radiomics features extracted from these counterfactual images, using a ground truth cyst mask, were analyzed to determine their correlation with segmentation performance. The DSCs for the original and VAE-GAN reconstructed images for counterfactual image generation showed no significant differences. Counterfactual explanations highlighted how variations in cyst image features influence segmentation outcomes and showed model discrepancies. Radiomics features correlating positively and negatively with dice scores were identified. The uncertainty of the predicted segmentation masks was estimated using posterior sampling of the weight space. The combination of counterfactual explanations and uncertainty maps provided a deeper understanding of the image features within the segmented renal cysts that lead to high uncertainty. The proposed segmentation framework not only achieved high segmentation accuracy but also increased interpretability regarding how image features impact segmentation performance.
MSCDA: Multi-level Semantic-guided Contrast Improves Unsupervised Domain Adaptation for Breast MRI Segmentation in Small Datasets
Jan 04, 2023
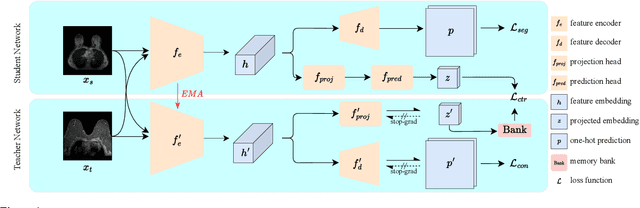
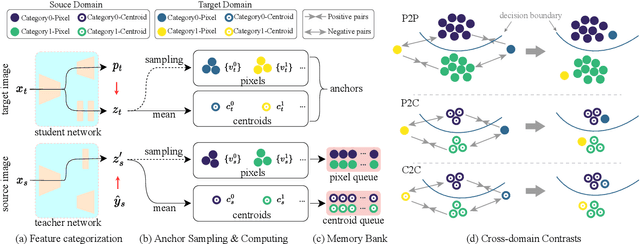
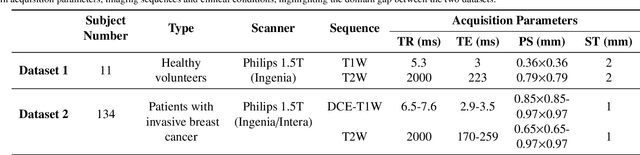
Deep learning (DL) applied to breast tissue segmentation in magnetic resonance imaging (MRI) has received increased attention in the last decade, however, the domain shift which arises from different vendors, acquisition protocols, and biological heterogeneity, remains an important but challenging obstacle on the path towards clinical implementation. Recently, unsupervised domain adaptation (UDA) methods have attempted to mitigate this problem by incorporating self-training with contrastive learning. To better exploit the underlying semantic information of the image at different levels, we propose a Multi-level Semantic-guided Contrastive Domain Adaptation (MSCDA) framework to align the feature representation between domains. In particular, we extend the contrastive loss by incorporating pixel-to-pixel, pixel-to-centroid, and centroid-to-centroid contrasts to integrate semantic information of images. We utilize a category-wise cross-domain sampling strategy to sample anchors from target images and build a hybrid memory bank to store samples from source images. Two breast MRI datasets were retrospectively collected: The source dataset contains non-contrast MRI examinations from 11 healthy volunteers and the target dataset contains contrast-enhanced MRI examinations of 134 invasive breast cancer patients. We set up experiments from source T2W image to target dynamic contrast-enhanced (DCE)-T1W image (T2W-to-T1W) and from source T1W image to target T2W image (T1W-to-T2W). The proposed method achieved Dice similarity coefficient (DSC) of 89.2\% and 84.0\% in T2W-to-T1W and T1W-to-T2W, respectively, outperforming state-of-the-art methods. Notably, good performance is still achieved with a smaller source dataset, proving that our framework is label-efficient.
BAST: Binaural Audio Spectrogram Transformer for Binaural Sound Localization
Jul 08, 2022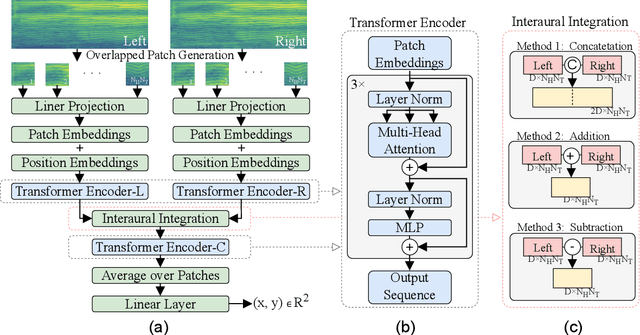
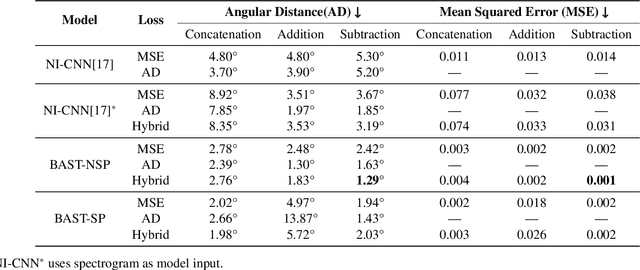
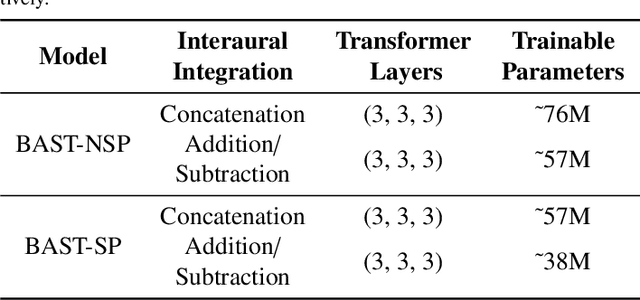
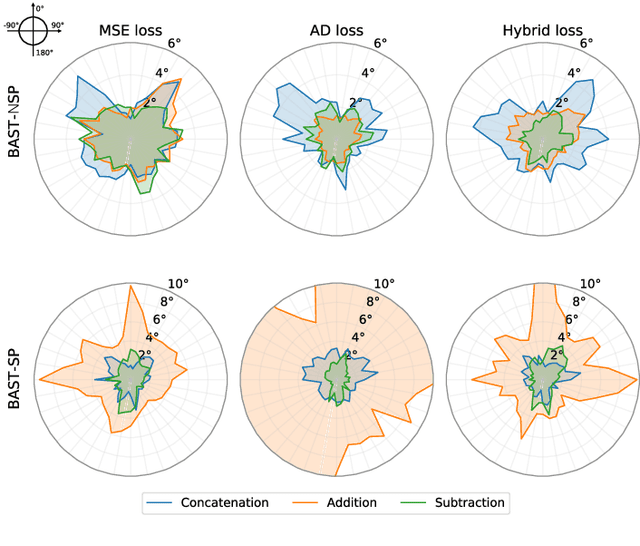
Accurate sound localization in a reverberation environment is essential for human auditory perception. Recently, Convolutional Neural Networks (CNNs) have been utilized to model the binaural human auditory pathway. However, CNN shows barriers in capturing the global acoustic features. To address this issue, we propose a novel end-to-end Binaural Audio Spectrogram Transformer (BAST) model to predict the sound azimuth in both anechoic and reverberation environments. Two modes of implementation, i.e. BAST-SP and BAST-NSP corresponding to BAST model with shared and non-shared parameters respectively, are explored. Our model with subtraction interaural integration and hybrid loss achieves an angular distance of 1.29 degrees and a Mean Square Error of 1e-3 at all azimuths, significantly surpassing CNN based model. The exploratory analysis of the BAST's performance on the left-right hemifields and anechoic and reverberation environments shows its generalization ability as well as the feasibility of binaural Transformers in sound localization. Furthermore, the analysis of the attention maps is provided to give additional insights on the interpretation of the localization process in a natural reverberant environment.