 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Driven Reinforcement Learning for Head-Orientation in Naturalistic Environments
Paper and Code
Sep 16, 2024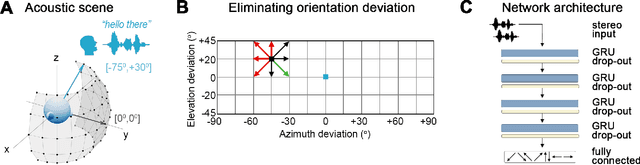
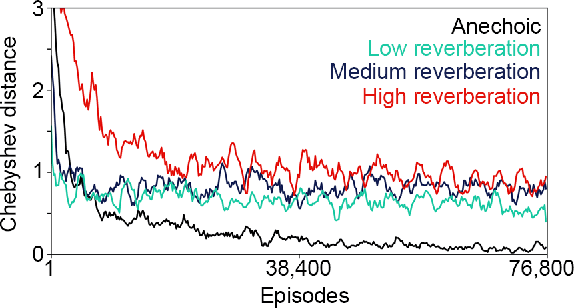
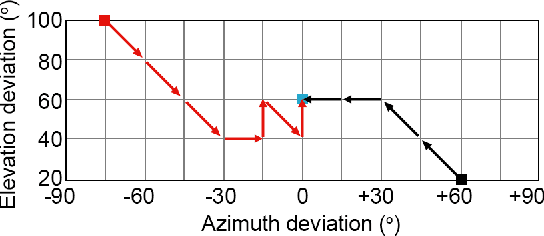
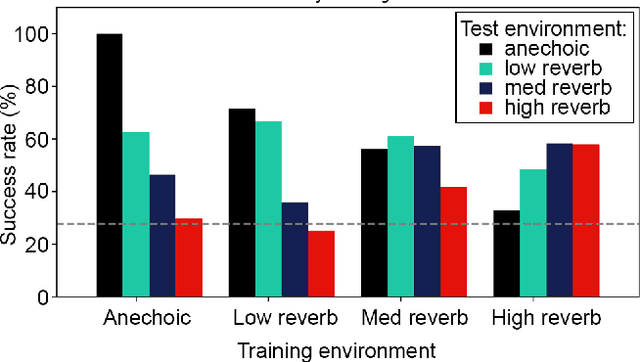
Although deep reinforcement learning (DRL) approaches in audio signal processing have seen substantial progress in recent years, audio-driven DRL for tasks such as navigation, gaze control and head-orientation control in the context of human-robot interaction have received little attention. Here, we propose an audio-driven DRL framework in which we utilise deep Q-learning to develop an autonomous agent that orients towards a talker in the acoustic environment based on stereo speech recordings. Our results show that the agent learned to perform the task at a near perfect level when trained on speech segments in anechoic environments (that is, without reverberation). The presence of reverberation in naturalistic acoustic environments affected the agent's performance, although the agent still substantially outperformed a baseline, randomly acting agent. Finally, we quantified the degree of generalization of the proposed DRL approach across naturalistic acoustic environments. Our experiments revealed that policies learned by agents trained on medium or high reverb environments generalized to low reverb environments, but policies learned by agents trained on anechoic or low reverb environments did not generalize to medium or high reverb environments. Taken together, this study demonstrates the potential of audio-driven DRL for tasks such as head-orientation control and highlights the need for training strategies that enable robust generalization across environments for real-world audio-driven DRL applications.