 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Prediction of Neural Dynamics via Autoregressive Flow Matching
Apr 13, 2026Forecasting neural activity in response to naturalistic stimuli remains a key challenge for understanding brain dynamics and enabling downstream neurotechnological applications. Here, we introduce a generative forecasting framework for modeling neural dynamics based on autoregressive flow matching (AFM). Building on recent advances in transport-based generative modeling, our approach probabilistically predicts neural responses at scale from multimodal sensory input. Specifically, we learn the conditional distribution of future neural activity given past neural dynamics and concurrent sensory input, explicitly modeling neural activity as a temporally evolving process in which future states depend on recent neural history. We evaluate our framework on the Algonauts project 2025 challenge functional magnetic resonance imaging dataset using subject-specific models. AFM significantly outperforms both a non-autoregressive flow-matching baseline and the official challenge general linear model baseline in predicting short-term parcel-wise blood oxygenation level-dependent (BOLD) activity, demonstrating improved generalization and widespread cortical prediction performance. Ablation analyses show that access to past BOLD dynamics is a dominant driver of performance, while autoregressive factorization yields consistent, modest gains under short-horizon, context-rich conditions. Together, these findings position autoregressive flow-based generative modeling as an effective approach for short-term probabilistic forecasting of neural dynamics with promising applications in closed-loop neurotechnology.
Audio-Driven Reinforcement Learning for Head-Orientation in Naturalistic Environments
Sep 16, 2024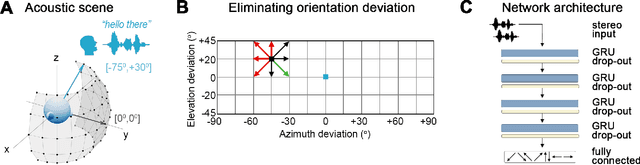
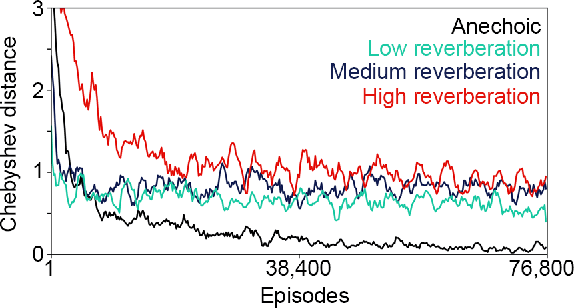
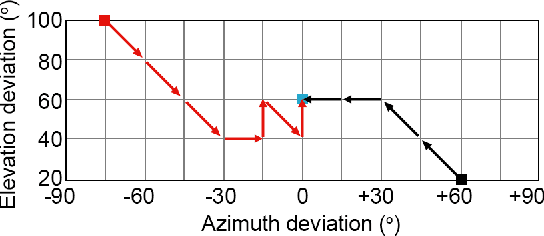
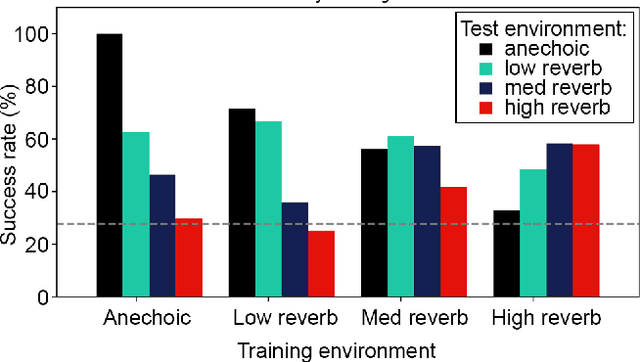
Although deep reinforcement learning (DRL) approaches in audio signal processing have seen substantial progress in recent years, audio-driven DRL for tasks such as navigation, gaze control and head-orientation control in the context of human-robot interaction have received little attention. Here, we propose an audio-driven DRL framework in which we utilise deep Q-learning to develop an autonomous agent that orients towards a talker in the acoustic environment based on stereo speech recordings. Our results show that the agent learned to perform the task at a near perfect level when trained on speech segments in anechoic environments (that is, without reverberation). The presence of reverberation in naturalistic acoustic environments affected the agent's performance, although the agent still substantially outperformed a baseline, randomly acting agent. Finally, we quantified the degree of generalization of the proposed DRL approach across naturalistic acoustic environments. Our experiments revealed that policies learned by agents trained on medium or high reverb environments generalized to low reverb environments, but policies learned by agents trained on anechoic or low reverb environments did not generalize to medium or high reverb environments. Taken together, this study demonstrates the potential of audio-driven DRL for tasks such as head-orientation control and highlights the need for training strategies that enable robust generalization across environments for real-world audio-driven DRL applications.
Stochastic Contextual Bandits with Long Horizon Rewards
Feb 03, 2023The growing interest in complex decision-making and language modeling problems highlights the importance of sample-efficient learning over very long horizons. This work takes a step in this direction by investigating contextual linear bandits where the current reward depends on at most $s$ prior actions and contexts (not necessarily consecutive), up to a time horizon of $h$. In order to avoid polynomial dependence on $h$, we propose new algorithms that leverage sparsity to discover the dependence pattern and arm parameters jointly. We consider both the data-poor ($T<h$) and data-rich ($T\ge h$) regimes, and derive respective regret upper bounds $\tilde O(d\sqrt{sT} +\min\{ q, T\})$ and $\tilde O(\sqrt{sdT})$, with sparsity $s$, feature dimension $d$, total time horizon $T$, and $q$ that is adaptive to the reward dependence pattern. Complementing upper bounds, we also show that learning over a single trajectory brings inherent challenges: While the dependence pattern and arm parameters form a rank-1 matrix, circulant matrices are not isometric over rank-1 manifolds and sample complexity indeed benefits from the sparse reward dependence structure. Our results necessitate a new analysis to address long-range temporal dependencies across data and avoid polynomial dependence on the reward horizon $h$. Specifically, we utilize connections to the restricted isometry property of circulant matrices formed by dependent sub-Gaussian vectors and establish new guarantees that are also of independent interest.
MVKT-ECG: Efficient Single-lead ECG Classification on Multi-Label Arrhythmia by Multi-View Knowledge Transferring
Jan 28, 2023The widespread emergence of smart devices for ECG has sparked demand for intelligent single-lead ECG-based diagnostic systems. However, it is challenging to develop a single-lead-based ECG interpretation model for multiple diseases diagnosis due to the lack of some key disease information. In this work, we propose inter-lead Multi-View Knowledge Transferring of ECG (MVKT-ECG) to boost single-lead ECG's ability for multi-label disease diagnosis. This training strategy can transfer superior disease knowledge from multiple different views of ECG (e.g. 12-lead ECG) to single-lead-based ECG interpretation model to mine details in single-lead ECG signals that are easily overlooked by neural networks. MVKT-ECG allows this lead variety as a supervision signal within a teacher-student paradigm, where the teacher observes multi-lead ECG educates a student who observes only single-lead ECG. Since the mutual disease information between the single-lead ECG and muli-lead ECG plays a key role in knowledge transferring, we present a new disease-aware Contrastive Lead-information Transferring(CLT) to improve the mutual disease information between the single-lead ECG and muli-lead ECG. Moreover, We modify traditional Knowledge Distillation to multi-label disease Knowledge Distillation (MKD) to make it applicable for multi-label disease diagnosis. The comprehensive experiments verify that MVKT-ECG has an excellent performance in improving the diagnostic effect of single-lead ECG.
Representation Learning for Context-Dependent Decision-Making
May 12, 2022
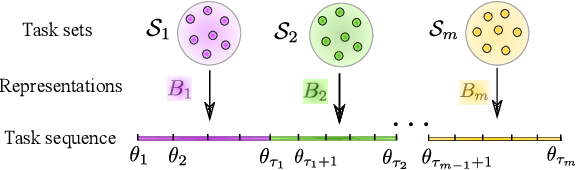
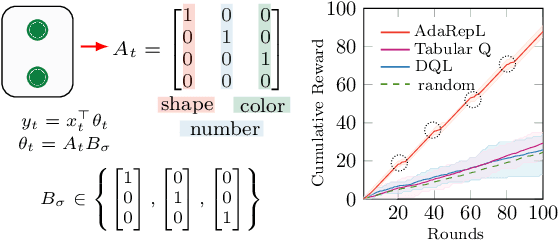
Humans are capable of adjusting to changing environments flexibly and quickly. Empirical evidence has revealed that representation learning plays a crucial role in endowing humans with such a capability. Inspired by this observation, we study representation learning in the sequential decision-making scenario with contextual changes. We propose an online algorithm that is able to learn and transfer context-dependent representations and show that it significantly outperforms the existing ones that do not learn representations adaptively. As a case study, we apply our algorithm to the Wisconsin Card Sorting Task, a well-established test for the mental flexibility of humans in sequential decision-making. By comparing our algorithm with the standard Q-learning and Deep-Q learning algorithms, we demonstrate the benefits of adaptive representation learning.
Non-Stationary Representation Learning in Sequential Linear Bandits
Jan 13, 2022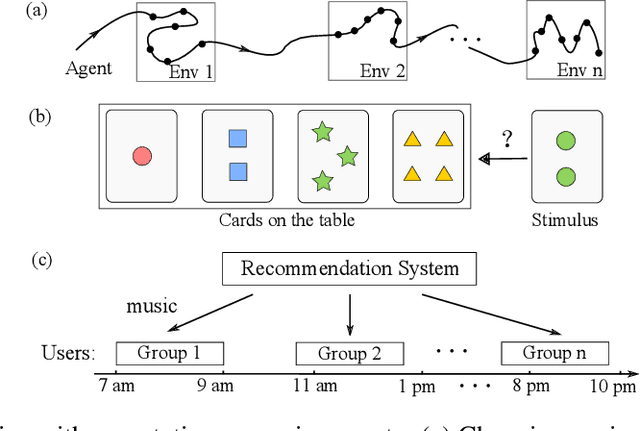
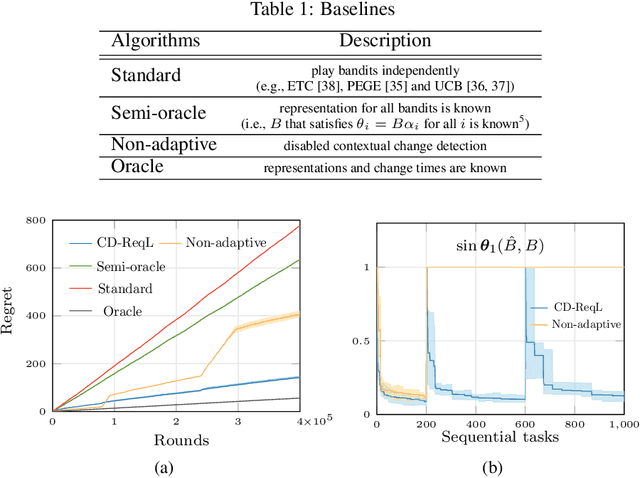
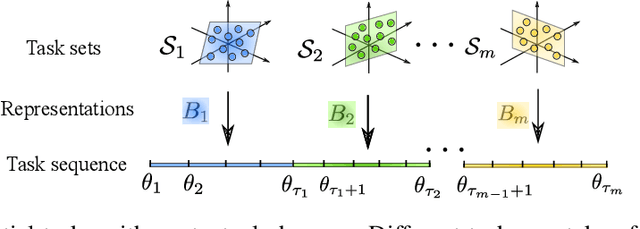
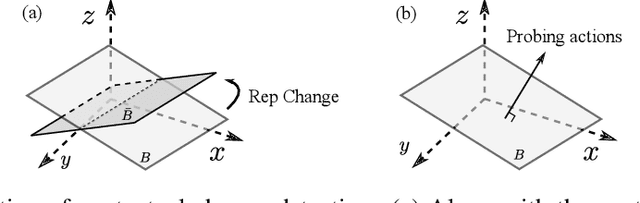
In this paper, we study representation learning for multi-task decision-making in non-stationary environments. We consider the framework of sequential linear bandits, where the agent performs a series of tasks drawn from distinct sets associated with different environments. The embeddings of tasks in each set share a low-dimensional feature extractor called representation, and representations are different across sets. We propose an online algorithm that facilitates efficient decision-making by learning and transferring non-stationary representations in an adaptive fashion. We prove that our algorithm significantly outperforms the existing ones that treat tasks independently. We also conduct experiments using both synthetic and real data to validate our theoretical insights and demonstrate the efficacy of our algorithm.