 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention by Synchronization in Coupled Oscillator Networks
Jun 10, 2026We address transformer attention on energy-constrained physical substrates. Softmax attention requires exponentiation and global reduction, operations with high energy cost on von Neumann hardware and no natural physical analog. We show that Kuramoto synchronization dynamics (which arise in electrical, mechanical, superconducting, and charge-density-wave oscillator arrays, among other physical systems) implement a well-defined attention operation without either. The resulting mechanism, fixed-query oscillator attention, replaces softmax's arithmetic with the equilibration of a gradient flow on the sphere: queries are learned anchors fixed on the sphere, and free oscillators evolve under Kuramoto-Lohe dynamics until they settle at positions encoding attention weights via cosine similarity. Because the computation is equilibration, it requires no exponentiation; the only global operation is an affine normalization at readout. The fixed point is provably unique and globally attractive from almost every initial condition, a guarantee that holds across every physical realization. Empirically, at the minimal hardware configuration (oscillator dimension $d_{\mathrm{osc}}$ = 2), oscillator attention outperforms softmax on keyword spotting (+1.00 pp) and on subject-verb agreement (+5.27 pp on hard sentences, with zero training failures versus one in five for softmax). On causal language modeling, where softmax retains an advantage, oscillator attention closes the gap as $d_{\mathrm{osc}}$ grows: from +11.09 PPL at $d_{\mathrm{osc}}$ = 2 to +2.98 PPL at $d_{\mathrm{osc}}$ = 32 on WikiText-2, and from +2.39 PPL at $d_{\mathrm{osc}}$ = 2 to +0.57 PPL at $d_{\mathrm{osc}}$ = 32 on TinyStories. The main objective of this work is not to replace softmax in software but to provide a mathematically grounded blueprint for accurate attention on physical substrates.
Oscillator-Based Associative Memory with Exponential Capacity: Theory, Algorithms, and Hardware Implementation
Apr 01, 2026Associative memory systems enable content-addressable storage and retrieval of patterns, a capability central to biological neural computation and artificial intelligence. Classical implementations such as Hopfield networks face fundamental limitations in memory capacity, scaling at most linearly with network size. We present an associative memory architecture based on Kuramoto oscillator networks with honeycomb topology in which memories are encoded as stable phase-locked configurations. The honeycomb network consists of multiple cycles that share nodes in a chain-like arrangement, creating a one-dimensional lattice of chained+loops. We prove that this architecture achieves exponential memory capacity: a network of $N$ oscillators can store $(2\lceil n_c/4 \rceil - 1)^m$ distinct patterns, where $m$ honeycomb cycles each contain $n_c$ oscillators. Moreover, we fully characterize all stable configurations and prove that each memory's basin of attraction maintains a guaranteed minimum size independent of network scale. Simulations using charge-density-wave (CDW) oscillators validate predicted phase-locking behavior, demonstrating practical realizability in neuromorphic hardware.
Provably Safe Generative Sampling with Constricting Barrier Functions
Feb 24, 2026Flow-based generative models, such as diffusion models and flow matching models, have achieved remarkable success in learning complex data distributions. However, a critical gap remains for their deployment in safety-critical domains: the lack of formal guarantees that generated samples will satisfy hard constraints. We address this by proposing a safety filtering framework that acts as an online shield for any pre-trained generative model. Our key insight is to cooperate with the generative process rather than override it. We define a constricting safety tube that is relaxed at the initial noise distribution and progressively tightens to the target safe set at the final data distribution, mirroring the coarse-to-fine structure of the generative process itself. By characterizing this tube via Control Barrier Functions (CBFs), we synthesize a feedback control input through a convex Quadratic Program (QP) at each sampling step. As the tube is loosest when noise is high and intervention is cheapest in terms of control energy, most constraint enforcement occurs when it least disrupts the model's learned structure. We prove that this mechanism guarantees safe sampling while minimizing the distributional shift from the original model at each sampling step, as quantified by the KL divergence. Our framework applies to any pre-trained flow-based generative scheme requiring no retraining or architectural modifications. We validate the approach across constrained image generation, physically-consistent trajectory sampling, and safe robotic manipulation policies, achieving 100% constraint satisfaction while preserving semantic fidelity.
Selection Mechanisms for Sequence Modeling using Linear State Space Models
May 23, 2025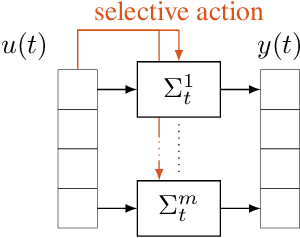



Recent advancements in language modeling tasks have been driven by architectures such as Transformers and, more recently, by Selective State Space Models (SSMs). In this paper, we introduce an alternative selection mechanism inspired by control theory methodologies. Specifically, we propose a novel residual generator for selection, drawing an analogy to fault detection strategies in Linear Time-Invariant (LTI) systems. Unlike Mamba, which utilizes Linear Time-Varying (LTV) systems, our approach combines multiple LTI systems, preserving their beneficial properties during training while achieving comparable selectivity. To evaluate the effectiveness of the proposed architecture, we test its performance on synthetic tasks. While these tasks are not inherently critical, they serve as benchmarks to test the selectivity properties of different cores architecture. This work highlights the potential of integrating theoretical insights with experimental advancements, offering a complementary perspective to deep learning innovations at the intersection of control theory and machine learning.
Score Matching Diffusion Based Feedback Control and Planning of Nonlinear Systems
Apr 14, 2025We propose a novel control-theoretic framework that leverages principles from generative modeling -- specifically, Denoising Diffusion Probabilistic Models (DDPMs) -- to stabilize control-affine systems with nonholonomic constraints. Unlike traditional stochastic approaches, which rely on noise-driven dynamics in both forward and reverse processes, our method crucially eliminates the need for noise in the reverse phase, making it particularly relevant for control applications. We introduce two formulations: one where noise perturbs all state dimensions during the forward phase while the control system enforces time reversal deterministically, and another where noise is restricted to the control channels, embedding system constraints directly into the forward process. For controllable nonlinear drift-free systems, we prove that deterministic feedback laws can exactly reverse the forward process, ensuring that the system's probability density evolves correctly without requiring artificial diffusion in the reverse phase. Furthermore, for linear time-invariant systems, we establish a time-reversal result under the second formulation. By eliminating noise in the backward process, our approach provides a more practical alternative to machine learning-based denoising methods, which are unsuitable for control applications due to the presence of stochasticity. We validate our results through numerical simulations on benchmark systems, including a unicycle model in a domain with obstacles, a driftless five-dimensional system, and a four-dimensional linear system, demonstrating the potential for applying diffusion-inspired techniques in linear, nonlinear, and settings with state space constraints.
Dynamics-aware Diffusion Models for Planning and Control
Apr 02, 2025This paper addresses the problem of generating dynamically admissible trajectories for control tasks using diffusion models, particularly in scenarios where the environment is complex and system dynamics are crucial for practical application. We propose a novel framework that integrates system dynamics directly into the diffusion model's denoising process through a sequential prediction and projection mechanism. This mechanism, aligned with the diffusion model's noising schedule, ensures generated trajectories are both consistent with expert demonstrations and adhere to underlying physical constraints. Notably, our approach can generate maximum likelihood trajectories and accurately recover trajectories generated by linear feedback controllers, even when explicit dynamics knowledge is unavailable. We validate the effectiveness of our method through experiments on standard control tasks and a complex non-convex optimal control problem involving waypoint tracking and collision avoidance, demonstrating its potential for efficient trajectory generation in practical applications.
Predicting AI Agent Behavior through Approximation of the Perron-Frobenius Operator
Jun 04, 2024



Predicting the behavior of AI-driven agents is particularly challenging without a preexisting model. In our paper, we address this by treating AI agents as nonlinear dynamical systems and adopting a probabilistic perspective to predict their statistical behavior using the Perron-Frobenius (PF) operator. We formulate the approximation of the PF operator as an entropy minimization problem, which can be solved by leveraging the Markovian property of the operator and decomposing its spectrum. Our data-driven methodology simultaneously approximates the PF operator to perform prediction of the evolution of the agents and also predicts the terminal probability density of AI agents, such as robotic systems and generative models. We demonstrate the effectiveness of our prediction model through extensive experiments on practical systems driven by AI algorithms.
Denoising Diffusion-Based Control of Nonlinear Systems
Feb 03, 2024We propose a novel approach based on Denoising Diffusion Probabilistic Models (DDPMs) to control nonlinear dynamical systems. DDPMs are the state-of-art of generative models that have achieved success in a wide variety of sampling tasks. In our framework, we pose the feedback control problem as a generative task of drawing samples from a target set under control system constraints. The forward process of DDPMs constructs trajectories originating from a target set by adding noise. We learn to control a dynamical system in reverse such that the terminal state belongs to the target set. For control-affine systems without drift, we prove that the control system can exactly track the trajectory of the forward process in reverse, whenever the the Lie bracket based condition for controllability holds. We numerically study our approach on various nonlinear systems and verify our theoretical results. We also conduct numerical experiments for cases beyond our theoretical results on a physics-engine.
Noise in the reverse process improves the approximation capabilities of diffusion models
Dec 14, 2023In Score based Generative Modeling (SGMs), the state-of-the-art in generative modeling, stochastic reverse processes are known to perform better than their deterministic counterparts. This paper delves into the heart of this phenomenon, comparing neural ordinary differential equations (ODEs) and neural stochastic differential equations (SDEs) as reverse processes. We use a control theoretic perspective by posing the approximation of the reverse process as a trajectory tracking problem. We analyze the ability of neural SDEs to approximate trajectories of the Fokker-Planck equation, revealing the advantages of stochasticity. First, neural SDEs exhibit a powerful regularizing effect, enabling $L^2$ norm trajectory approximation surpassing the Wasserstein metric approximation achieved by neural ODEs under similar conditions, even when the reference vector field or score function is not Lipschitz. Applying this result, we establish the class of distributions that can be sampled using score matching in SGMs, relaxing the Lipschitz requirement on the gradient of the data distribution in existing literature. Second, we show that this approximation property is preserved when network width is limited to the input dimension of the network. In this limited width case, the weights act as control inputs, framing our analysis as a controllability problem for neural SDEs in probability density space. This sheds light on how noise helps to steer the system towards the desired solution and illuminates the empirical success of stochasticity in generative modeling.
Fusing Multiple Algorithms for Heterogeneous Online Learning
Dec 09, 2023


This study addresses the challenge of online learning in contexts where agents accumulate disparate data, face resource constraints, and use different local algorithms. This paper introduces the Switched Online Learning Algorithm (SOLA), designed to solve the heterogeneous online learning problem by amalgamating updates from diverse agents through a dynamic switching mechanism contingent upon their respective performance and available resources. We theoretically analyze the design of the selecting mechanism to ensure that the regret of SOLA is bounded. Our findings show that the number of changes in selection needs to be bounded by a parameter dependent on the performance of the different local algorithms. Additionally, two test cases are presented to emphasize the effectiveness of SOLA, first on an online linear regression problem and then on an online classification problem with the MNIST dataset.