 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Separation for Hearing-Impaired Children in the Classroom
Nov 10, 2025Classroom environments are particularly challenging for children with hearing impairments, where background noise, multiple talkers, and reverberation degrade speech perception. These difficulties are greater for children than adults, yet most deep learning speech separation models for assistive devices are developed using adult voices in simplified, low-reverberation conditions. This overlooks both the higher spectral similarity of children's voices, which weakens separation cues, and the acoustic complexity of real classrooms. We address this gap using MIMO-TasNet, a compact, low-latency, multi-channel architecture suited for real-time deployment in bilateral hearing aids or cochlear implants. We simulated naturalistic classroom scenes with moving child-child and child-adult talker pairs under varying noise and distance conditions. Training strategies tested how well the model adapts to children's speech through spatial cues. Models trained on adult speech, classroom data, and finetuned variants were compared to assess data-efficient adaptation. Results show that adult-trained models perform well in clean scenes, but classroom-specific training greatly improves separation quality. Finetuning with only half the classroom data achieved comparable gains, confirming efficient transfer learning. Training with diffuse babble noise further enhanced robustness, and the model preserved spatial awareness while generalizing to unseen distances. These findings demonstrate that spatially aware architectures combined with targeted adaptation can improve speech accessibility for children in noisy classrooms, supporting future on-device assistive technologies.
Leveraging Spatial Cues from Cochlear Implant Microphones to Efficiently Enhance Speech Separation in Real-World Listening Scenes
Jan 24, 2025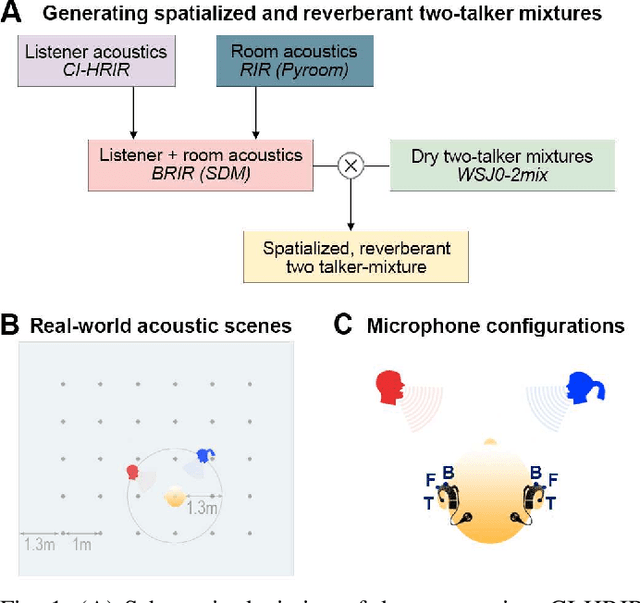
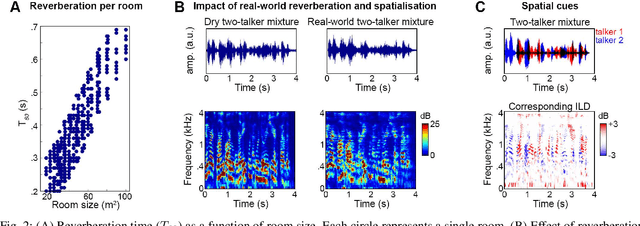
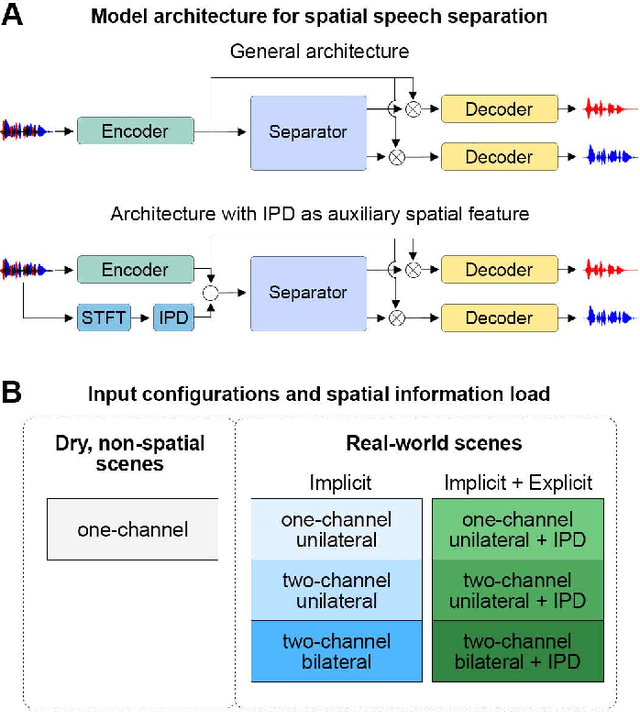
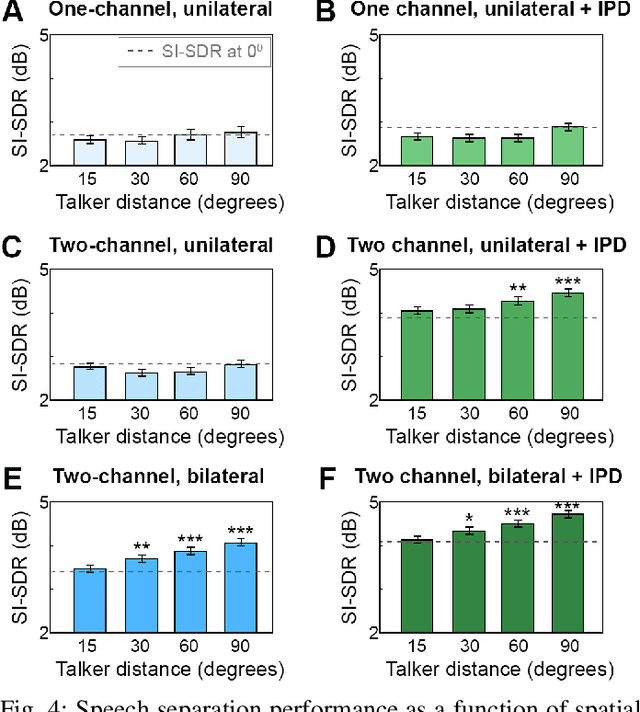
Speech separation approaches for single-channel, dry speech mixtures have significantly improved. However, real-world spatial and reverberant acoustic environments remain challenging, limiting the effectiveness of these approaches for assistive hearing devices like cochlear implants (CIs). To address this, we quantify the impact of real-world acoustic scenes on speech separation and explore how spatial cues can enhance separation quality efficiently. We analyze performance based on implicit spatial cues (inherent in the acoustic input and learned by the model) and explicit spatial cues (manually calculated spatial features added as auxiliary inputs). Our findings show that spatial cues (both implicit and explicit) improve separation for mixtures with spatially separated and nearby talkers. Furthermore, spatial cues enhance separation when spectral cues are ambiguous, such as when voices are similar. Explicit spatial cues are particularly beneficial when implicit spatial cues are weak. For instance, single CI microphone recordings provide weaker implicit spatial cues than bilateral CIs, but even single CIs benefit from explicit cues. These results emphasize the importance of training models on real-world data to improve generalizability in everyday listening scenarios. Additionally, our statistical analyses offer insights into how data properties influence model performance, supporting the development of efficient speech separation approaches for CIs and other assistive devices in real-world settings.
Optimizing Stimulus Energy for Cochlear Implants with a Machine Learning Model of the Auditory Nerve
Nov 14, 2022
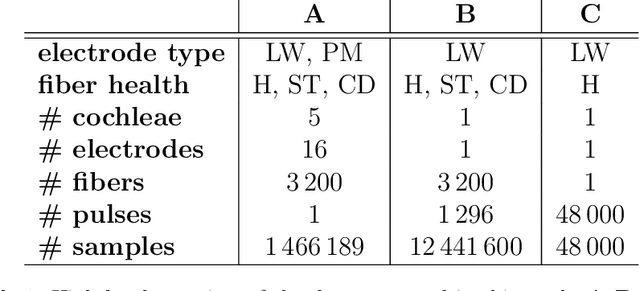
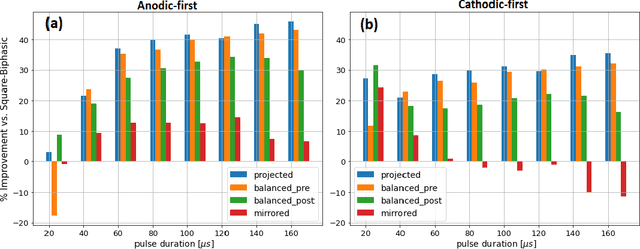
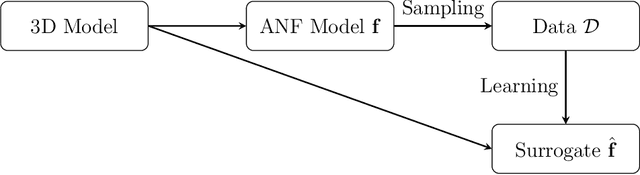
Performing simulations with a realistic biophysical auditory nerve fiber model can be very time consuming, due to the complex nature of the calculations involved. Here, a surrogate (approximate) model of such an auditory nerve fiber model was developed using machine learning methods, to perform simulations more efficiently. Several machine learning models were compared, of which a Convolutional Neural Network showed the best performance. In fact, the Convolutional Neural Network was able to emulate the behavior of the auditory nerve fiber model with extremely high similarity ($R^2 > 0.99$), tested under a wide range of experimental conditions, whilst reducing the simulation time by five orders of magnitude. In addition, we introduce a method for randomly generating charge-balanced waveforms using hyperplane projection. In the second part of this paper, the Convolutional Neural Network surrogate model was used by an Evolutionary Algorithm to optimize the shape of the stimulus waveform in terms energy efficiency. The resulting waveforms resemble a positive Gaussian-like peak, preceded by an elongated negative phase. When comparing the energy of the waveforms generated by the Evolutionary Algorithm with the commonly used square wave, energy decreases of 8% - 45% were observed for different pulse durations. These results were validated with the original auditory nerve fiber model, which demonstrates that our proposed surrogate model can be used as its accurate and efficient replacement.