 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymmetrization of Loss Functions for Robust Training of Neural Networks in the Presence of Noisy Labels
May 19, 2026Labeling a training set is often expensive and susceptible to errors, making the design of robust loss functions for label noise an important problem. The symmetry condition provides theoretical guarantees for robustness to such noise. In this work, we study a symmetrization method arising from the unique decomposition of any multi-class loss function into a symmetric component and a class-insensitive term. In particular, symmetrizing the cross-entropy loss leads to a linear multi-class extension of the unhinged loss. Unlike in the binary case, the multi-class version must have specific coefficients in order to satisfy the symmetry condition. Under suitable assumptions, we show that this multi-class unhinged loss is the unique convex multi-class symmetric loss. We also show that it has a fundamental local role: the linear approximation of any symmetric loss around score vectors with equal components is equivalent to the multi-class unhinged loss. We then introduce SGCE and alpha-MAE, two loss functions that interpolate between the multi-class unhinged loss and the Mean Absolute Error while allowing control of the beta-smoothness of the loss. Experiments on standard noisy-label benchmarks show competitive performance compared with existing robust loss functions.
Leveraging Image Generators to Address Training Data Scarcity: The Gen4Regen Dataset for Forest Regeneration Mapping
May 07, 2026Sustainable forest management relies on precise species composition mapping, yet traditional ground surveys are labour-intensive and geographically constrained. While Uncrewed Aerial Vehicles (UAVs) offer scalable data collection, the transition to deep learning-based interpretation is bottlenecked by the severe scarcity of expert-annotated imagery, particularly in complex, visually heterogeneous regeneration zones. This paper addresses the dual challenges of data scarcity and extreme class imbalance in the semantic segmentation of fine-grained forest regeneration species by providing a scalable framework that reduces reliance on manual photo-interpretation for high-resolution, millimetre-level aerial imagery. Importantly, we leverage the large-scale vision-language Nano Banana Pro model to simultaneously generate high-fidelity images and their corresponding pixel-aligned semantic masks from prompts. We introduce WilDReF-Q-V2, an expansion of a natural forest dataset with 13 977 new unlabelled and 50 labelled real images, as well as the Gen4Regen dataset, featuring 2101 pairs of synthetic images and semantic masks. Our methodology integrates real-world data with AI-generated images, highlighting that AI-generated data is highly complementary to real-world data, with unified training yielding an F1 score improvement of over 15 %pt compared to purely supervised baselines. Furthermore, we demonstrate that even small quantities of prompt-generated data significantly improve performance for underrepresented species, some of which saw per-species F1 score gains of up to 30 %pt. We conclude that vision-language models can serve as agile data generators, effectively bootstrapping perception tasks for niche AI domains where expert labels are scarce or unavailable. Our datasets, source code, and models will be available at https://norlab-ulaval.github.io/gen4regen.
SilvaScenes: Tree Segmentation and Species Classification from Under-Canopy Images in Natural Forests
Oct 10, 2025



Interest in robotics for forest management is growing, but perception in complex, natural environments remains a significant hurdle. Conditions such as heavy occlusion, variable lighting, and dense vegetation pose challenges to automated systems, which are essential for precision forestry, biodiversity monitoring, and the automation of forestry equipment. These tasks rely on advanced perceptual capabilities, such as detection and fine-grained species classification of individual trees. Yet, existing datasets are inadequate to develop such perception systems, as they often focus on urban settings or a limited number of species. To address this, we present SilvaScenes, a new dataset for instance segmentation of tree species from under-canopy images. Collected across five bioclimatic domains in Quebec, Canada, SilvaScenes features 1476 trees from 24 species with annotations from forestry experts. We demonstrate the relevance and challenging nature of our dataset by benchmarking modern deep learning approaches for instance segmentation. Our results show that, while tree segmentation is easy, with a top mean average precision (mAP) of 67.65%, species classification remains a significant challenge with an mAP of only 35.69%. Our dataset and source code will be available at https://github.com/norlab-ulaval/SilvaScenes.
UAV-Assisted Self-Supervised Terrain Awareness for Off-Road Navigation
Sep 26, 2024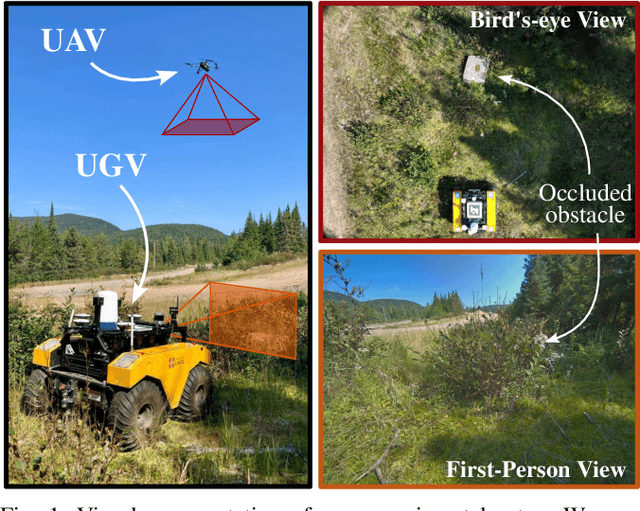
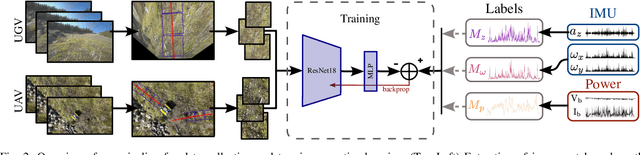
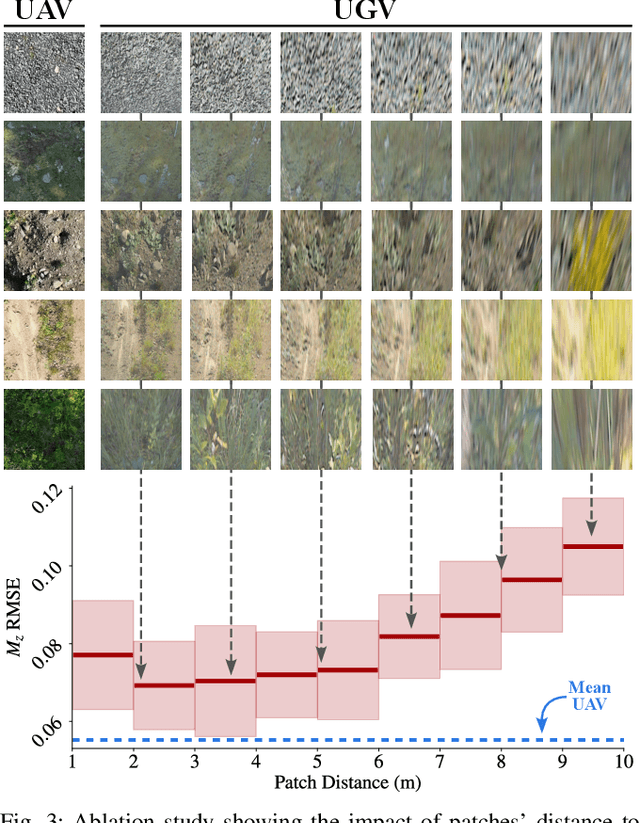
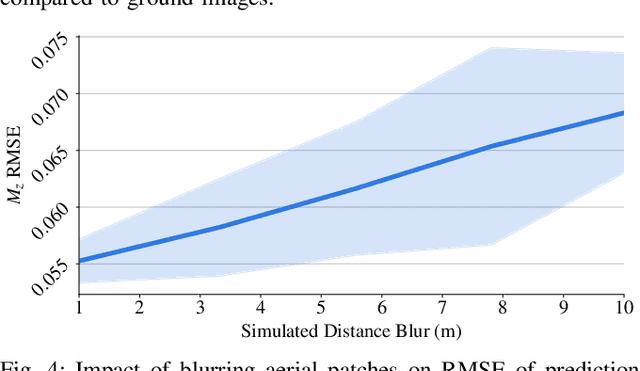
Terrain awareness is an essential milestone to enable truly autonomous off-road navigation. Accurately predicting terrain characteristics allows optimizing a vehicle's path against potential hazards. Recent methods use deep neural networks to predict traversability-related terrain properties in a self-supervised manner, relying on proprioception as a training signal. However, onboard cameras are inherently limited by their point-of-view relative to the ground, suffering from occlusions and vanishing pixel density with distance. This paper introduces a novel approach for self-supervised terrain characterization using an aerial perspective from a hovering drone. We capture terrain-aligned images while sampling the environment with a ground vehicle, effectively training a simple predictor for vibrations, bumpiness, and energy consumption. Our dataset includes 2.8 km of off-road data collected in forest environment, comprising 13 484 ground-based images and 12 935 aerial images. Our findings show that drone imagery improves terrain property prediction by 21.37 % on the whole dataset and 37.35 % in high vegetation, compared to ground robot images. We conduct ablation studies to identify the main causes of these performance improvements. We also demonstrate the real-world applicability of our approach by scouting an unseen area with a drone, planning and executing an optimized path on the ground.
BoQ: A Place is Worth a Bag of Learnable Queries
May 12, 2024In visual place recognition, accurately identifying and matching images of locations under varying environmental conditions and viewpoints remains a significant challenge. In this paper, we introduce a new technique, called Bag-of-Queries (BoQ), which learns a set of global queries designed to capture universal place-specific attributes. Unlike existing methods that employ self-attention and generate the queries directly from the input features, BoQ employs distinct learnable global queries, which probe the input features via cross-attention, ensuring consistent information aggregation. In addition, our technique provides an interpretable attention mechanism and integrates with both CNN and Vision Transformer backbones. The performance of BoQ is demonstrated through extensive experiments on 14 large-scale benchmarks. It consistently outperforms current state-of-the-art techniques including NetVLAD, MixVPR and EigenPlaces. Moreover, as a global retrieval technique (one-stage), BoQ surpasses two-stage retrieval methods, such as Patch-NetVLAD, TransVPR and R2Former, all while being orders of magnitude faster and more efficient. The code and model weights are publicly available at https://github.com/amaralibey/Bag-of-Queries.
Field Report on a Wearable and Versatile Solution for Field Acquisition and Exploration
Apr 30, 2024
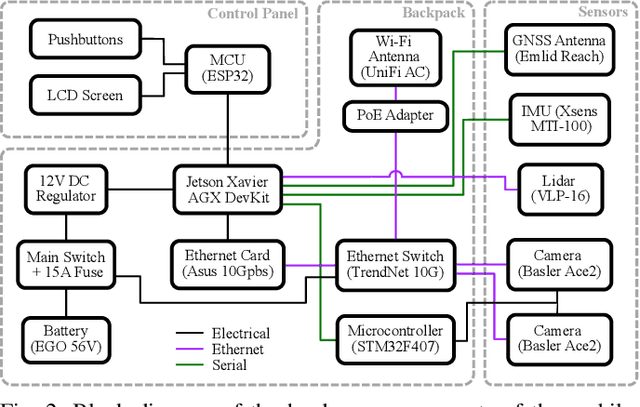


This report presents a wearable plug-and-play platform for data acquisition in the field. The platform, extending a waterproof Pelican Case into a 20 kg backpack offers 5.5 hours of power autonomy, while recording data with two cameras, a lidar, an Inertial Measurement Unit (IMU), and a Global Navigation Satellite System (GNSS) receiver. The system only requires a single operator and is readily controlled with a built-in screen and buttons. Due to its small footprint, it offers greater flexibility than large vehicles typically deployed in off-trail environments. We describe the platform's design, detailing the mechanical parts, electrical components, and software stack. We explain the system's limitations, drawing from its extensive deployment spanning over 20 kilometers of trajectories across various seasons, environments, and weather conditions. We derive valuable lessons learned from these deployments and present several possible applications for the system. The possible use cases consider not only academic research but also insights from consultations with our industrial partners. The mechanical design including all CAD files, as well as the software stack, are publicly available at https://github.com/norlab-ulaval/backpack_workspace.
Proprioception Is All You Need: Terrain Classification for Boreal Forests
Mar 25, 2024



Recent works in field robotics highlighted the importance of resiliency against different types of terrains. Boreal forests, in particular, are home to many mobility-impeding terrains that should be considered for off-road autonomous navigation. Also, being one of the largest land biomes on Earth, boreal forests are an area where autonomous vehicles are expected to become increasingly common. In this paper, we address this issue by introducing BorealTC, a publicly available dataset for proprioceptive-based terrain classification (TC). Recorded with a Husky A200, our dataset contains 116 min of Inertial Measurement Unit (IMU), motor current, and wheel odometry data, focusing on typical boreal forest terrains, notably snow, ice, and silty loam. Combining our dataset with another dataset from the state-of-the-art, we evaluate both a Convolutional Neural Network (CNN) and the novel state space model (SSM)-based Mamba architecture on a TC task. Interestingly, we show that while CNN outperforms Mamba on each separate dataset, Mamba achieves greater accuracy when trained on a combination of both. In addition, we demonstrate that Mamba's learning capacity is greater than a CNN for increasing amounts of data. We show that the combination of two TC datasets yields a latent space that can be interpreted with the properties of the terrains. We also discuss the implications of merging datasets on classification. Our source code and dataset are publicly available online: https://github.com/norlab-ulaval/BorealTC.
Saturation-Aware Angular Velocity Estimation: Extending the Robustness of SLAM to Aggressive Motions
Oct 11, 2023



We propose a novel angular velocity estimation method to increase the robustness of Simultaneous Localization And Mapping (SLAM) algorithms against gyroscope saturations induced by aggressive motions. Field robotics expose robots to various hazards, including steep terrains, landslides, and staircases, where substantial accelerations and angular velocities can occur if the robot loses stability and tumbles. These extreme motions can saturate sensor measurements, especially gyroscopes, which are the first sensors to become inoperative. While the structural integrity of the robot is at risk, the resilience of the SLAM framework is oftentimes given little consideration. Consequently, even if the robot is physically capable of continuing the mission, its operation will be compromised due to a corrupted representation of the world. Regarding this problem, we propose a way to estimate the angular velocity using accelerometers during extreme rotations caused by tumbling. We show that our method reduces the median localization error by 71.5 % in translation and 65.5 % in rotation and reduces the number of SLAM failures by 73.3 % on the collected data. We also propose the Tumbling-Induced Gyroscope Saturation (TIGS) dataset, which consists of outdoor experiments recording the motion of a lidar subject to angular velocities four times higher than other available datasets. The dataset is available online at https://github.com/norlab-ulaval/Norlab_wiki/wiki/TIGS-Dataset.
Exposing the Unseen: Exposure Time Emulation for Offline Benchmarking of Vision Algorithms
Sep 22, 2023Visual Odometry (VO) is one of the fundamental tasks in computer vision for robotics. However, its performance is deeply affected by High Dynamic Range (HDR) scenes, omnipresent outdoor. While new Automatic-Exposure (AE) approaches to mitigate this have appeared, their comparison in a reproducible manner is problematic. This stems from the fact that the behavior of AE depends on the environment, and it affects the image acquisition process. Consequently, AE has traditionally only been benchmarked in an online manner, making the experiments non-reproducible. To solve this, we propose a new methodology based on an emulator that can generate images at any exposure time. It leverages BorealHDR, a unique multi-exposure stereo dataset collected over 8.4 km, on 50 trajectories with challenging illumination conditions. Moreover, it contains pose ground truth for each image and a global 3D map, based on lidar data. We show that using these images acquired at different exposure times, we can emulate realistic images keeping a Root-Mean-Square Error (RMSE) below 1.78 % compared to ground truth images. To demonstrate the practicality of our approach for offline benchmarking, we compared three state-of-the-art AE algorithms on key elements of Visual Simultaneous Localization And Mapping (VSLAM) pipeline, against four baselines. Consequently, reproducible evaluation of AE is now possible, speeding up the development of future approaches. Our code and dataset are available online at this link: https://github.com/norlab-ulaval/BorealHDR
RTS-GT: Robotic Total Stations Ground Truthing dataset
Sep 21, 2023



Numerous datasets and benchmarks exist to assess and compare Simultaneous Localization and Mapping (SLAM) algorithms. Nevertheless, their precision must follow the rate at which SLAM algorithms improved in recent years. Moreover, current datasets fall short of comprehensive data-collection protocol for reproducibility and the evaluation of the precision or accuracy of the recorded trajectories. With this objective in mind, we proposed the Robotic Total Stations Ground Truthing dataset (RTS-GT) dataset to support localization research with the generation of six-Degrees Of Freedom (DOF) ground truth trajectories. This novel dataset includes six-DOF ground truth trajectories generated using a system of three Robotic Total Stations (RTSs) tracking moving robotic platforms. Furthermore, we compare the performance of the RTS-based system to a Global Navigation Satellite System (GNSS)-based setup. The dataset comprises around sixty experiments conducted in various conditions over a period of 17 months, and encompasses over 49 kilometers of trajectories, making it the most extensive dataset of RTS-based measurements to date. Additionally, we provide the precision of all poses for each experiment, a feature not found in the current state-of-the-art datasets. Our results demonstrate that RTSs provide measurements that are 22 times more stable than GNSS in various environmental settings, making them a valuable resource for SLAM benchmark development.