 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUAV-Assisted Self-Supervised Terrain Awareness for Off-Road Navigation
Sep 26, 2024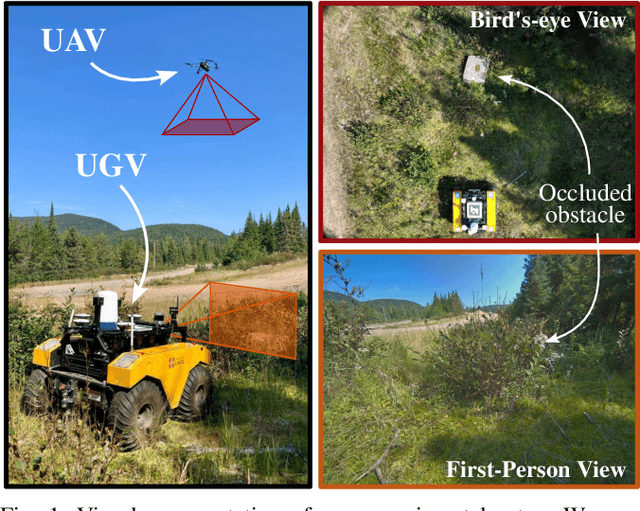
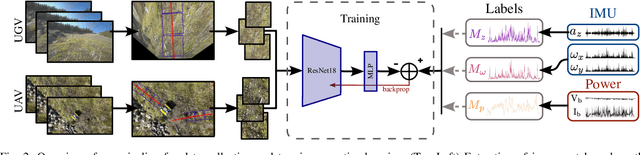
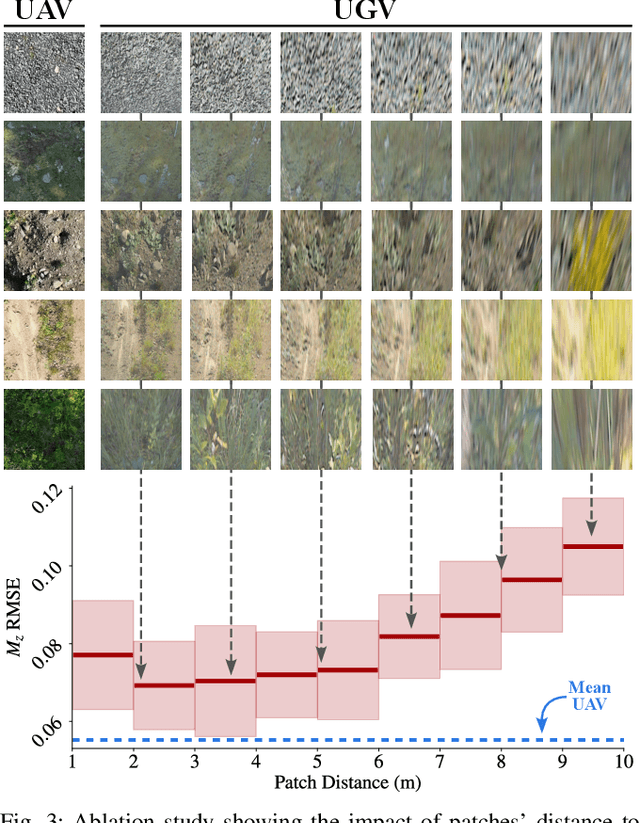
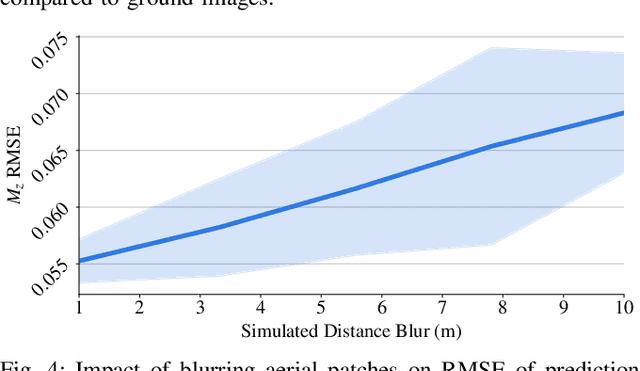
Terrain awareness is an essential milestone to enable truly autonomous off-road navigation. Accurately predicting terrain characteristics allows optimizing a vehicle's path against potential hazards. Recent methods use deep neural networks to predict traversability-related terrain properties in a self-supervised manner, relying on proprioception as a training signal. However, onboard cameras are inherently limited by their point-of-view relative to the ground, suffering from occlusions and vanishing pixel density with distance. This paper introduces a novel approach for self-supervised terrain characterization using an aerial perspective from a hovering drone. We capture terrain-aligned images while sampling the environment with a ground vehicle, effectively training a simple predictor for vibrations, bumpiness, and energy consumption. Our dataset includes 2.8 km of off-road data collected in forest environment, comprising 13 484 ground-based images and 12 935 aerial images. Our findings show that drone imagery improves terrain property prediction by 21.37 % on the whole dataset and 37.35 % in high vegetation, compared to ground robot images. We conduct ablation studies to identify the main causes of these performance improvements. We also demonstrate the real-world applicability of our approach by scouting an unseen area with a drone, planning and executing an optimized path on the ground.
Replication Study and Benchmarking of Real-Time Object Detection Models
May 11, 2024This work examines the reproducibility and benchmarking of state-of-the-art real-time object detection models. As object detection models are often used in real-world contexts, such as robotics, where inference time is paramount, simply measuring models' accuracy is not enough to compare them. We thus compare a large variety of object detection models' accuracy and inference speed on multiple graphics cards. In addition to this large benchmarking attempt, we also reproduce the following models from scratch using PyTorch on the MS COCO 2017 dataset: DETR, RTMDet, ViTDet and YOLOv7. More importantly, we propose a unified training and evaluation pipeline, based on MMDetection's features, to better compare models. Our implementation of DETR and ViTDet could not achieve accuracy or speed performances comparable to what is declared in the original papers. On the other hand, reproduced RTMDet and YOLOv7 could match such performances. Studied papers are also found to be generally lacking for reproducibility purposes. As for MMDetection pretrained models, speed performances are severely reduced with limited computing resources (larger, more accurate models even more so). Moreover, results exhibit a strong trade-off between accuracy and speed, prevailed by anchor-free models - notably RTMDet or YOLOx models. The code used is this paper and all the experiments is available in the repository at https://github.com/Don767/segdet_mlcr2024.