 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoQ: A Place is Worth a Bag of Learnable Queries
May 12, 2024In visual place recognition, accurately identifying and matching images of locations under varying environmental conditions and viewpoints remains a significant challenge. In this paper, we introduce a new technique, called Bag-of-Queries (BoQ), which learns a set of global queries designed to capture universal place-specific attributes. Unlike existing methods that employ self-attention and generate the queries directly from the input features, BoQ employs distinct learnable global queries, which probe the input features via cross-attention, ensuring consistent information aggregation. In addition, our technique provides an interpretable attention mechanism and integrates with both CNN and Vision Transformer backbones. The performance of BoQ is demonstrated through extensive experiments on 14 large-scale benchmarks. It consistently outperforms current state-of-the-art techniques including NetVLAD, MixVPR and EigenPlaces. Moreover, as a global retrieval technique (one-stage), BoQ surpasses two-stage retrieval methods, such as Patch-NetVLAD, TransVPR and R2Former, all while being orders of magnitude faster and more efficient. The code and model weights are publicly available at https://github.com/amaralibey/Bag-of-Queries.
MixVPR: Feature Mixing for Visual Place Recognition
Mar 03, 2023Visual Place Recognition (VPR) is a crucial part of mobile robotics and autonomous driving as well as other computer vision tasks. It refers to the process of identifying a place depicted in a query image using only computer vision. At large scale, repetitive structures, weather and illumination changes pose a real challenge, as appearances can drastically change over time. Along with tackling these challenges, an efficient VPR technique must also be practical in real-world scenarios where latency matters. To address this, we introduce MixVPR, a new holistic feature aggregation technique that takes feature maps from pre-trained backbones as a set of global features. Then, it incorporates a global relationship between elements in each feature map in a cascade of feature mixing, eliminating the need for local or pyramidal aggregation as done in NetVLAD or TransVPR. We demonstrate the effectiveness of our technique through extensive experiments on multiple large-scale benchmarks. Our method outperforms all existing techniques by a large margin while having less than half the number of parameters compared to CosPlace and NetVLAD. We achieve a new all-time high recall@1 score of 94.6% on Pitts250k-test, 88.0% on MapillarySLS, and more importantly, 58.4% on Nordland. Finally, our method outperforms two-stage retrieval techniques such as Patch-NetVLAD, TransVPR and SuperGLUE all while being orders of magnitude faster. Our code and trained models are available at https://github.com/amaralibey/MixVPR.
Global Proxy-based Hard Mining for Visual Place Recognition
Feb 28, 2023Learning deep representations for visual place recognition is commonly performed using pairwise or triple loss functions that highly depend on the hardness of the examples sampled at each training iteration. Existing techniques address this by using computationally and memory expensive offline hard mining, which consists of identifying, at each iteration, the hardest samples from the training set. In this paper we introduce a new technique that performs global hard mini-batch sampling based on proxies. To do so, we add a new end-to-end trainable branch to the network, which generates efficient place descriptors (one proxy for each place). These proxy representations are thus used to construct a global index that encompasses the similarities between all places in the dataset, allowing for highly informative mini-batch sampling at each training iteration. Our method can be used in combination with all existing pairwise and triplet loss functions with negligible additional memory and computation cost. We run extensive ablation studies and show that our technique brings new state-of-the-art performance on multiple large-scale benchmarks such as Pittsburgh, Mapillary-SLS and SPED. In particular, our method provides more than 100% relative improvement on the challenging Nordland dataset. Our code is available at https://github.com/amaralibey/GPM
GSV-Cities: Toward Appropriate Supervised Visual Place Recognition
Oct 19, 2022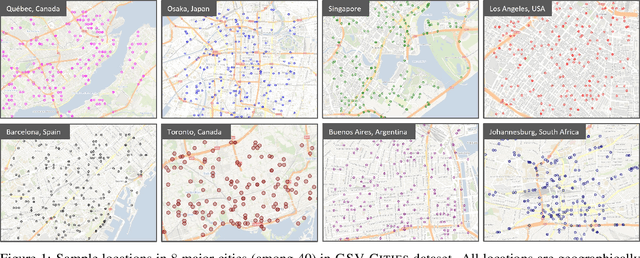
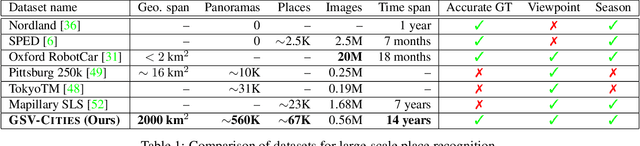

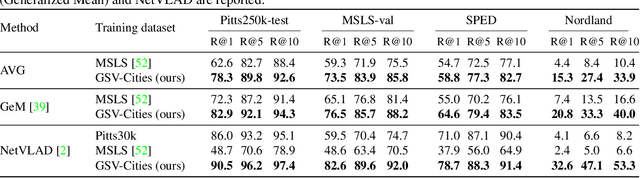
This paper aims to investigate representation learning for large scale visual place recognition, which consists of determining the location depicted in a query image by referring to a database of reference images. This is a challenging task due to the large-scale environmental changes that can occur over time (i.e., weather, illumination, season, traffic, occlusion). Progress is currently challenged by the lack of large databases with accurate ground truth. To address this challenge, we introduce GSV-Cities, a new image dataset providing the widest geographic coverage to date with highly accurate ground truth, covering more than 40 cities across all continents over a 14-year period. We subsequently explore the full potential of recent advances in deep metric learning to train networks specifically for place recognition, and evaluate how different loss functions influence performance. In addition, we show that performance of existing methods substantially improves when trained on GSV-Cities. Finally, we introduce a new fully convolutional aggregation layer that outperforms existing techniques, including GeM, NetVLAD and CosPlace, and establish a new state-of-the-art on large-scale benchmarks, such as Pittsburgh, Mapillary-SLS, SPED and Nordland. The dataset and code are available for research purposes at https://github.com/amaralibey/gsv-cities.