 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoQ: A Place is Worth a Bag of Learnable Queries
May 12, 2024In visual place recognition, accurately identifying and matching images of locations under varying environmental conditions and viewpoints remains a significant challenge. In this paper, we introduce a new technique, called Bag-of-Queries (BoQ), which learns a set of global queries designed to capture universal place-specific attributes. Unlike existing methods that employ self-attention and generate the queries directly from the input features, BoQ employs distinct learnable global queries, which probe the input features via cross-attention, ensuring consistent information aggregation. In addition, our technique provides an interpretable attention mechanism and integrates with both CNN and Vision Transformer backbones. The performance of BoQ is demonstrated through extensive experiments on 14 large-scale benchmarks. It consistently outperforms current state-of-the-art techniques including NetVLAD, MixVPR and EigenPlaces. Moreover, as a global retrieval technique (one-stage), BoQ surpasses two-stage retrieval methods, such as Patch-NetVLAD, TransVPR and R2Former, all while being orders of magnitude faster and more efficient. The code and model weights are publicly available at https://github.com/amaralibey/Bag-of-Queries.
Dynamic Y-KD: A Hybrid Approach to Continual Instance Segmentation
Mar 13, 2023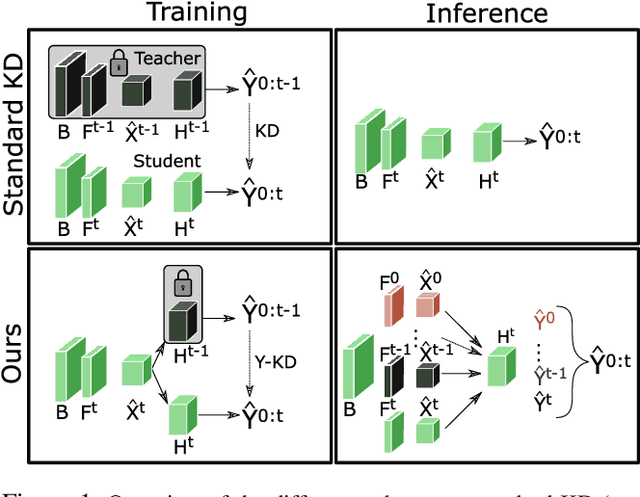
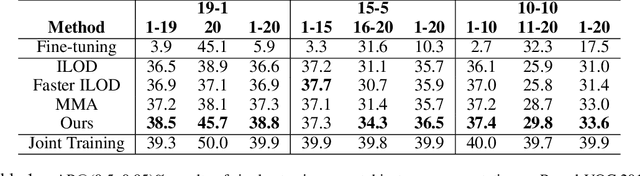
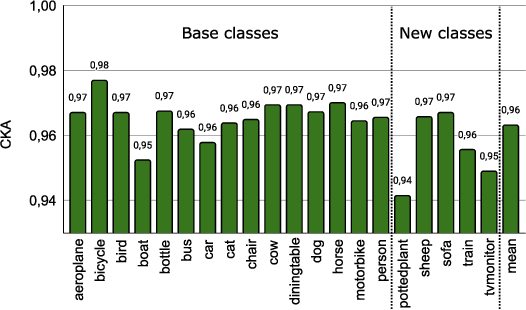
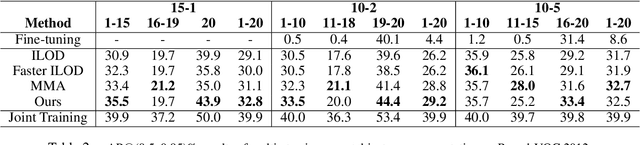
Despite the success of deep learning methods on instance segmentation, these models still suffer from catastrophic forgetting in continual learning scenarios. In this paper, our contributions for continual instance segmentation are threefold. First, we propose the Y-knowledge distillation (Y-KD), a knowledge distillation strategy that shares a common feature extractor between the teacher and student networks. As the teacher is also updated with new data in Y-KD, the increased plasticity results in new modules that are specialized on new classes. Second, our Y-KD approach is supported by a dynamic architecture method that grows new modules for each task and uses all of them for inference with a unique instance segmentation head, which significantly reduces forgetting. Third, we complete our approach by leveraging checkpoint averaging as a simple method to manually balance the trade-off between the performance on the various sets of classes, thus increasing the control over the model's behavior without any additional cost. These contributions are united in our model that we name the Dynamic Y-KD network. We perform extensive experiments on several single-step and multi-steps scenarios on Pascal-VOC, and we show that our approach outperforms previous methods both on past and new classes. For instance, compared to recent work, our method obtains +2.1% mAP on old classes in 15-1, +7.6% mAP on new classes in 19-1 and reaches 91.5% of the mAP obtained by joint-training on all classes in 15-5.
MixVPR: Feature Mixing for Visual Place Recognition
Mar 03, 2023Visual Place Recognition (VPR) is a crucial part of mobile robotics and autonomous driving as well as other computer vision tasks. It refers to the process of identifying a place depicted in a query image using only computer vision. At large scale, repetitive structures, weather and illumination changes pose a real challenge, as appearances can drastically change over time. Along with tackling these challenges, an efficient VPR technique must also be practical in real-world scenarios where latency matters. To address this, we introduce MixVPR, a new holistic feature aggregation technique that takes feature maps from pre-trained backbones as a set of global features. Then, it incorporates a global relationship between elements in each feature map in a cascade of feature mixing, eliminating the need for local or pyramidal aggregation as done in NetVLAD or TransVPR. We demonstrate the effectiveness of our technique through extensive experiments on multiple large-scale benchmarks. Our method outperforms all existing techniques by a large margin while having less than half the number of parameters compared to CosPlace and NetVLAD. We achieve a new all-time high recall@1 score of 94.6% on Pitts250k-test, 88.0% on MapillarySLS, and more importantly, 58.4% on Nordland. Finally, our method outperforms two-stage retrieval techniques such as Patch-NetVLAD, TransVPR and SuperGLUE all while being orders of magnitude faster. Our code and trained models are available at https://github.com/amaralibey/MixVPR.
Global Proxy-based Hard Mining for Visual Place Recognition
Feb 28, 2023Learning deep representations for visual place recognition is commonly performed using pairwise or triple loss functions that highly depend on the hardness of the examples sampled at each training iteration. Existing techniques address this by using computationally and memory expensive offline hard mining, which consists of identifying, at each iteration, the hardest samples from the training set. In this paper we introduce a new technique that performs global hard mini-batch sampling based on proxies. To do so, we add a new end-to-end trainable branch to the network, which generates efficient place descriptors (one proxy for each place). These proxy representations are thus used to construct a global index that encompasses the similarities between all places in the dataset, allowing for highly informative mini-batch sampling at each training iteration. Our method can be used in combination with all existing pairwise and triplet loss functions with negligible additional memory and computation cost. We run extensive ablation studies and show that our technique brings new state-of-the-art performance on multiple large-scale benchmarks such as Pittsburgh, Mapillary-SLS and SPED. In particular, our method provides more than 100% relative improvement on the challenging Nordland dataset. Our code is available at https://github.com/amaralibey/GPM
GSV-Cities: Toward Appropriate Supervised Visual Place Recognition
Oct 19, 2022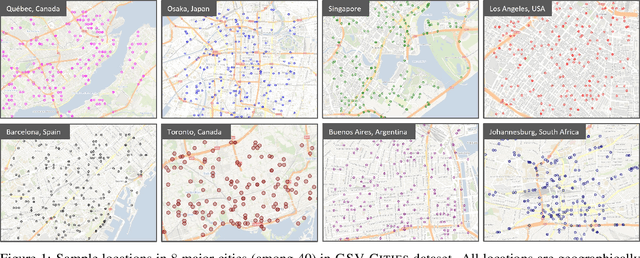
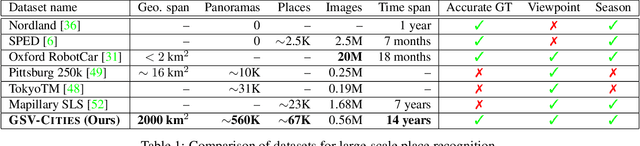

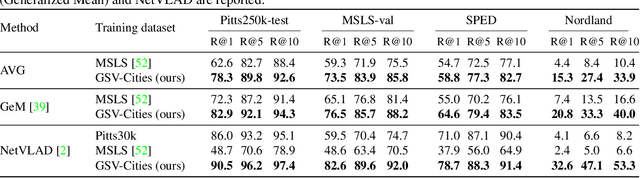
This paper aims to investigate representation learning for large scale visual place recognition, which consists of determining the location depicted in a query image by referring to a database of reference images. This is a challenging task due to the large-scale environmental changes that can occur over time (i.e., weather, illumination, season, traffic, occlusion). Progress is currently challenged by the lack of large databases with accurate ground truth. To address this challenge, we introduce GSV-Cities, a new image dataset providing the widest geographic coverage to date with highly accurate ground truth, covering more than 40 cities across all continents over a 14-year period. We subsequently explore the full potential of recent advances in deep metric learning to train networks specifically for place recognition, and evaluate how different loss functions influence performance. In addition, we show that performance of existing methods substantially improves when trained on GSV-Cities. Finally, we introduce a new fully convolutional aggregation layer that outperforms existing techniques, including GeM, NetVLAD and CosPlace, and establish a new state-of-the-art on large-scale benchmarks, such as Pittsburgh, Mapillary-SLS, SPED and Nordland. The dataset and code are available for research purposes at https://github.com/amaralibey/gsv-cities.
Multi-task Learning by Leveraging the Semantic Information
Mar 03, 2021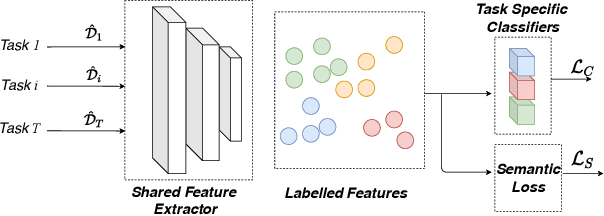


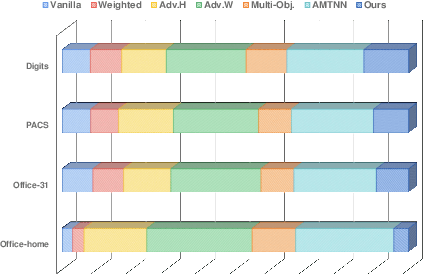
One crucial objective of multi-task learning is to align distributions across tasks so that the information between them can be transferred and shared. However, existing approaches only focused on matching the marginal feature distribution while ignoring the semantic information, which may hinder the learning performance. To address this issue, we propose to leverage the label information in multi-task learning by exploring the semantic conditional relations among tasks. We first theoretically analyze the generalization bound of multi-task learning based on the notion of Jensen-Shannon divergence, which provides new insights into the value of label information in multi-task learning. Our analysis also leads to a concrete algorithm that jointly matches the semantic distribution and controls label distribution divergence. To confirm the effectiveness of the proposed method, we first compare the algorithm with several baselines on some benchmarks and then test the algorithms under label space shift conditions. Empirical results demonstrate that the proposed method could outperform most baselines and achieve state-of-the-art performance, particularly showing the benefits under the label shift conditions.
Domain Generalization with Optimal Transport and Metric Learning
Jul 21, 2020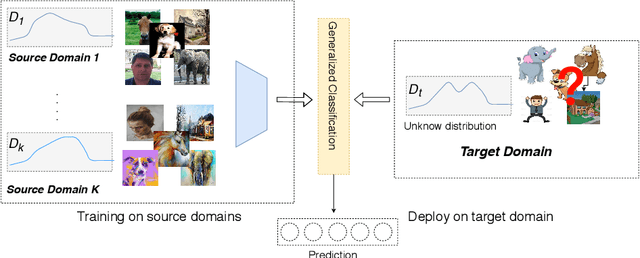

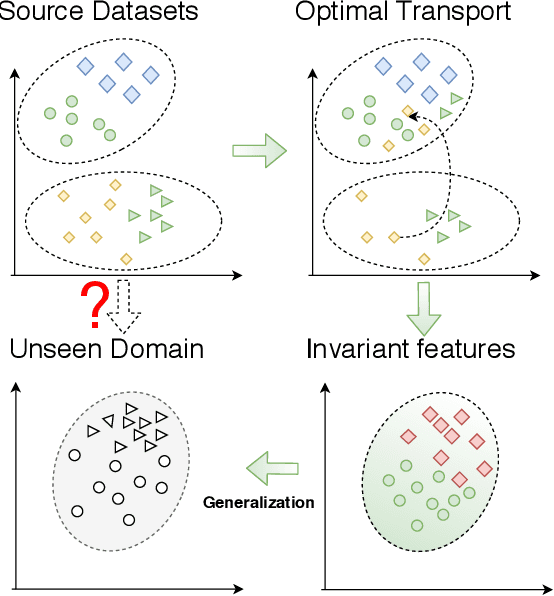

Generalizing knowledge to unseen domains, where data and labels are unavailable, is crucial for machine learning models. We tackle the domain generalization problem to learn from multiple source domains and generalize to a target domain with unknown statistics. The crucial idea is to extract the underlying invariant features across all the domains. Previous domain generalization approaches mainly focused on learning invariant features and stacking the learned features from each source domain to generalize to a new target domain while ignoring the label information, which will lead to indistinguishable features with an ambiguous classification boundary. For this, one possible solution is to constrain the label-similarity when extracting the invariant features and to take advantage of the label similarities for class-specific cohesion and separation of features across domains. Therefore we adopt optimal transport with Wasserstein distance, which could constrain the class label similarity, for adversarial training and also further deploy a metric learning objective to leverage the label information for achieving distinguishable classification boundary. Empirical results show that our proposed method could outperform most of the baselines. Furthermore, ablation studies also demonstrate the effectiveness of each component of our method.
Discriminative Active Learning for Domain Adaptation
May 24, 2020
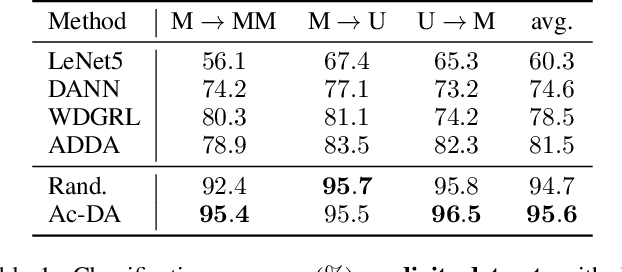

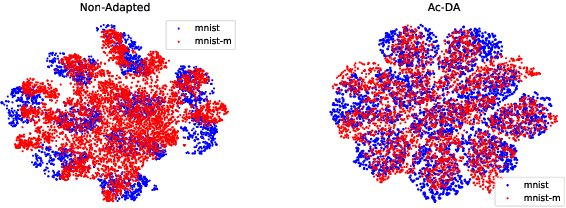
Domain Adaptation aiming to learn a transferable feature between different but related domains has been well investigated and has shown excellent empirical performances. Previous works mainly focused on matching the marginal feature distributions using the adversarial training methods while assuming the conditional relations between the source and target domain remained unchanged, $i.e.$, ignoring the conditional shift problem. However, recent works have shown that such a conditional shift problem exists and can hinder the adaptation process. To address this issue, we have to leverage labelled data from the target domain, but collecting labelled data can be quite expensive and time-consuming. To this end, we introduce a discriminative active learning approach for domain adaptation to reduce the efforts of data annotation. Specifically, we propose three-stage active adversarial training of neural networks: invariant feature space learning (first stage), uncertainty and diversity criteria and their trade-off for query strategy (second stage) and re-training with queried target labels (third stage). Empirical comparisons with existing domain adaptation methods using four benchmark datasets demonstrate the effectiveness of the proposed approach.
Few-shot Learning with Contextual Cueing for Object Recognition in Complex Scenes
Dec 17, 2019

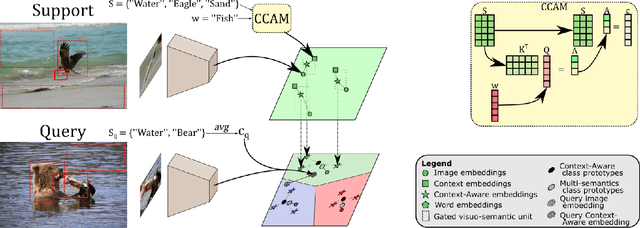
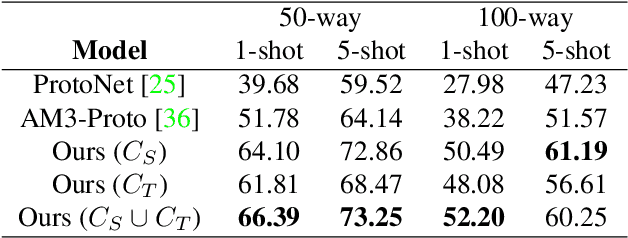
Few-shot Learning aims to recognize new concepts from a small number of training examples. Recent work mainly tackle this problem by improving visual features, feature transfer and meta-training algorithms. In this work, we propose to explore a complementary direction by using scene context semantics to learn and recognize new concepts more easily. Whereas a few visual examples cannot cover all intra-class variations, contextual cueing offers a complementary signal to classify instances with unseen features or ambiguous objects. More specifically, we propose a Class-conditioned Context Attention Module (CCAM) that learns to weight the most important context elements while learning a particular concept. We additionally propose a flexible gating mechanism to ground visual class representations in context semantics. We conduct extensive experiments on Visual Genome dataset, and we show that compared to a visual-only baseline, our model improves top-1 accuracy by 20.47% and 9.13% in 5-way 1-shot and 5-way 5-shot, respectively; and by 20.42% and 12.45% in 20-way 1-shot and 20-way 5-shot, respectively.
GQ-STN: Optimizing One-Shot Grasp Detection based on Robustness Classifier
Mar 06, 2019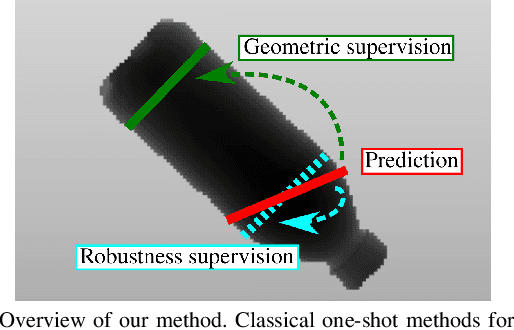



Grasping is a fundamental robotic task needed for the deployment of household robots or furthering warehouse automation. However, few approaches are able to perform grasp detection in real time (frame rate). To this effect, we present Grasp Quality Spatial Transformer Network (GQ-STN), a one-shot grasp detection network. Being based on the Spatial Transformer Network (STN), it produces not only a grasp configuration, but also directly outputs a depth image centered at this configuration. By connecting our architecture to an externally-trained grasp robustness evaluation network, we can train efficiently to satisfy a robustness metric via the backpropagation of the gradient emanating from the evaluation network. This removes the difficulty of training detection networks on sparsely annotated databases, a common issue in grasping. We further propose to use this robustness classifier to compare approaches, being more reliable than the traditional rectangle metric. Our GQ-STN is able to detect robust grasps on the depth images of the Dex-Net 2.0 dataset with 92.4 % accuracy in a single pass of the network. We finally demonstrate in a physical benchmark that our method can propose robust grasps more often than previous sampling-based methods, while being more than 60 times faster.