 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Y-KD: A Hybrid Approach to Continual Instance Segmentation
Mar 13, 2023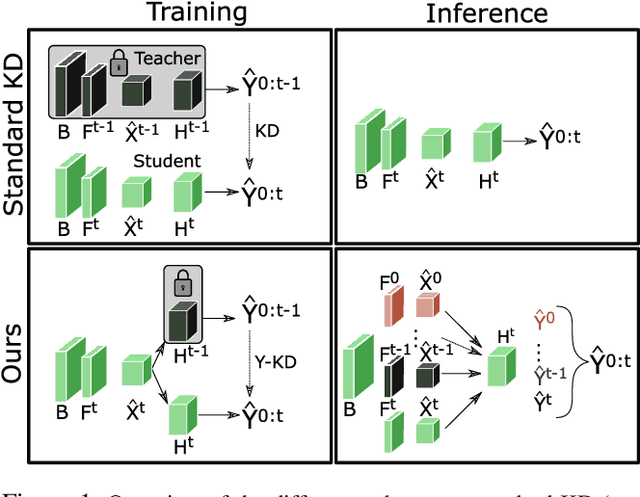
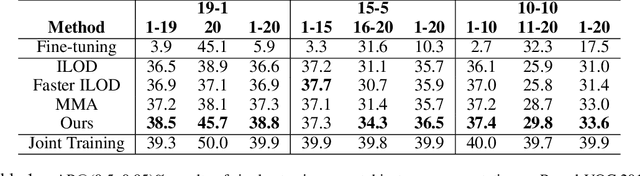
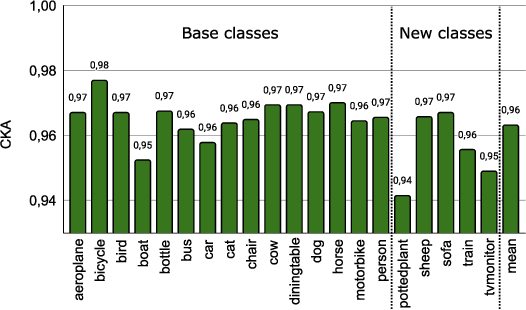
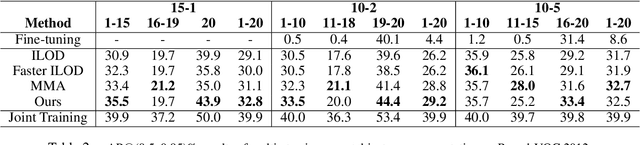
Despite the success of deep learning methods on instance segmentation, these models still suffer from catastrophic forgetting in continual learning scenarios. In this paper, our contributions for continual instance segmentation are threefold. First, we propose the Y-knowledge distillation (Y-KD), a knowledge distillation strategy that shares a common feature extractor between the teacher and student networks. As the teacher is also updated with new data in Y-KD, the increased plasticity results in new modules that are specialized on new classes. Second, our Y-KD approach is supported by a dynamic architecture method that grows new modules for each task and uses all of them for inference with a unique instance segmentation head, which significantly reduces forgetting. Third, we complete our approach by leveraging checkpoint averaging as a simple method to manually balance the trade-off between the performance on the various sets of classes, thus increasing the control over the model's behavior without any additional cost. These contributions are united in our model that we name the Dynamic Y-KD network. We perform extensive experiments on several single-step and multi-steps scenarios on Pascal-VOC, and we show that our approach outperforms previous methods both on past and new classes. For instance, compared to recent work, our method obtains +2.1% mAP on old classes in 15-1, +7.6% mAP on new classes in 19-1 and reaches 91.5% of the mAP obtained by joint-training on all classes in 15-5.