 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClass-Incremental Learning of Plant and Disease Detection: Growing Branches with Knowledge Distillation
Apr 13, 2023



This paper investigates the problem of class-incremental object detection for agricultural applications where a model needs to learn new plant species and diseases incrementally without forgetting the previously learned ones. We adapt two public datasets to include new categories over time, simulating a more realistic and dynamic scenario. We then compare three class-incremental learning methods that leverage different forms of knowledge distillation to mitigate catastrophic forgetting. Our experiments show that all three methods suffer from catastrophic forgetting, but the recent Dynamic Y-KD approach, which additionally uses a dynamic architecture that grows new branches to learn new tasks, outperforms ILOD and Faster-ILOD in most scenarios both on new and old classes. These results highlight the challenges and opportunities of continual object detection for agricultural applications. In particular, the large intra-class and small inter-class variability that is typical of plant images exacerbate the difficulty of learning new categories without interfering with previous knowledge. We publicly release our code to encourage future work.
Few-shot Learning with Contextual Cueing for Object Recognition in Complex Scenes
Dec 17, 2019

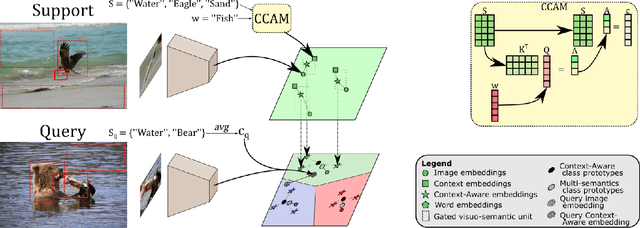
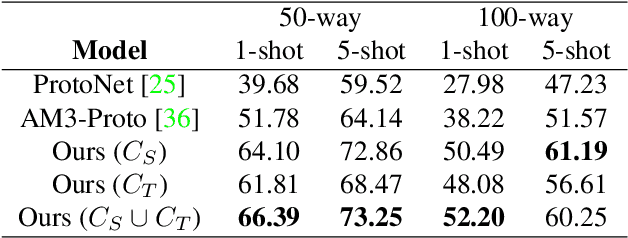
Few-shot Learning aims to recognize new concepts from a small number of training examples. Recent work mainly tackle this problem by improving visual features, feature transfer and meta-training algorithms. In this work, we propose to explore a complementary direction by using scene context semantics to learn and recognize new concepts more easily. Whereas a few visual examples cannot cover all intra-class variations, contextual cueing offers a complementary signal to classify instances with unseen features or ambiguous objects. More specifically, we propose a Class-conditioned Context Attention Module (CCAM) that learns to weight the most important context elements while learning a particular concept. We additionally propose a flexible gating mechanism to ground visual class representations in context semantics. We conduct extensive experiments on Visual Genome dataset, and we show that compared to a visual-only baseline, our model improves top-1 accuracy by 20.47% and 9.13% in 5-way 1-shot and 5-way 5-shot, respectively; and by 20.42% and 12.45% in 20-way 1-shot and 20-way 5-shot, respectively.