 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable 3D Convolutional Neural Networks by Learning Temporal Transformations
Jun 29, 2020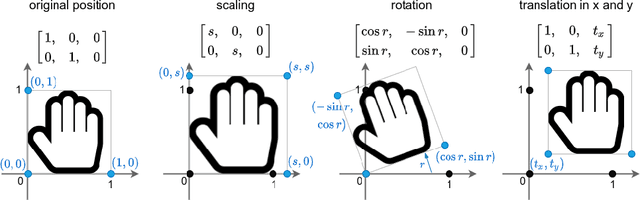


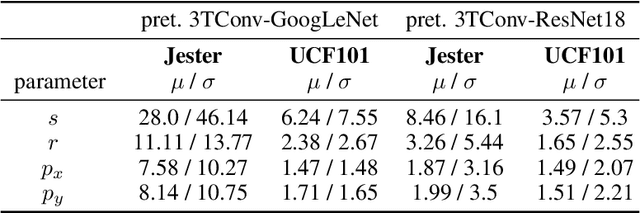
In this paper we introduce the temporally factorized 3D convolution (3TConv) as an interpretable alternative to the regular 3D convolution (3DConv). In a 3TConv the 3D convolutional filter is obtained by learning a 2D filter and a set of temporal transformation parameters, resulting in a sparse filter where the 2D slices are sequentially dependent on each other in the temporal dimension. We demonstrate that 3TConv learns temporal transformations that afford a direct interpretation. The temporal parameters can be used in combination with various existing 2D visualization methods. We also show that insight about what the model learns can be achieved by analyzing the transformation parameter statistics on a layer and model level. Finally, we implicitly demonstrate that, in popular ConvNets, the 2DConv can be replaced with a 3TConv and that the weights can be transferred to yield pretrained 3TConvs. pretrained 3TConvnets leverage more than a decade of work on traditional 2DConvNets by being able to make use of features that have been proven to deliver excellent results on image classification benchmarks.
Background Hardly Matters: Understanding Personality Attribution in Deep Residual Networks
Dec 20, 2019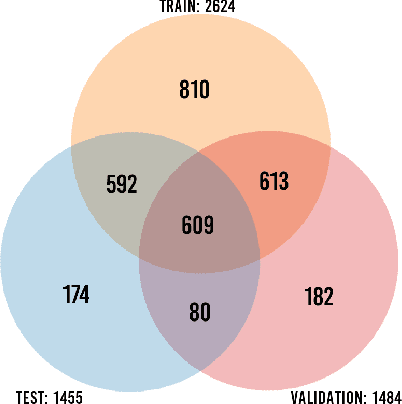
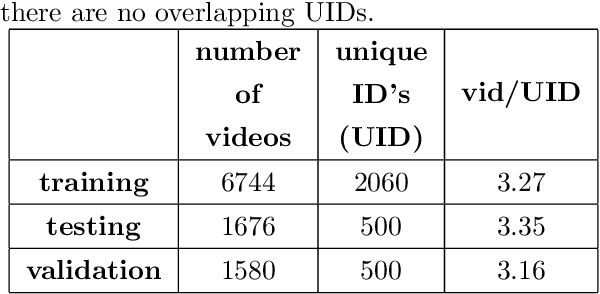

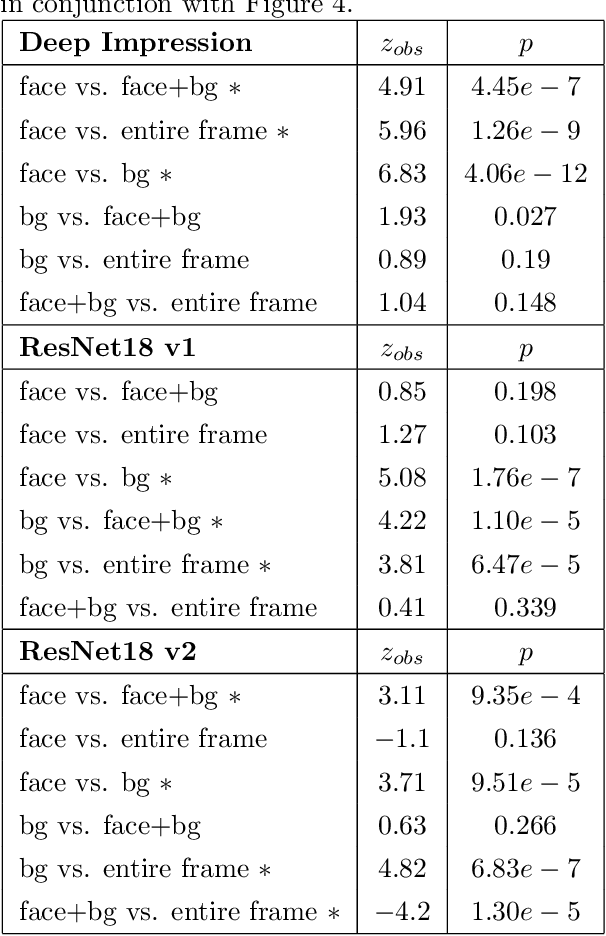
Perceived personality traits attributed to an individual do not have to correspond to their actual personality traits and may be determined in part by the context in which one encounters a person. These apparent traits determine, to a large extent, how other people will behave towards them. Deep neural networks are increasingly being used to perform automated personality attribution (e.g., job interviews). It is important that we understand the driving factors behind the predictions, in humans and in deep neural networks. This paper explicitly studies the effect of the image background on apparent personality prediction while addressing two important confounds present in existing literature; overlapping data splits and including facial information in the background. Surprisingly, we found no evidence that background information improves model predictions for apparent personality traits. In fact, when background is explicitly added to the input, a decrease in performance was measured across all models.
Temporal Factorization of 3D Convolutional Kernels
Dec 09, 2019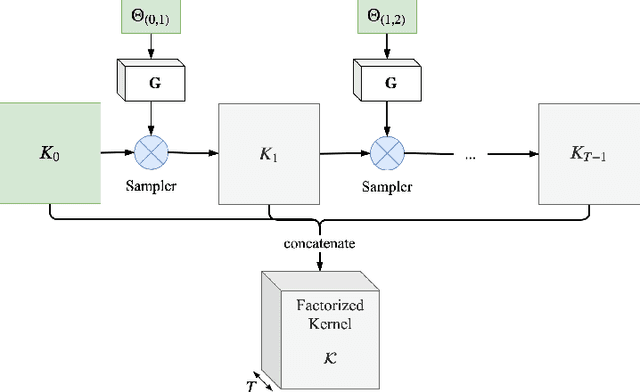


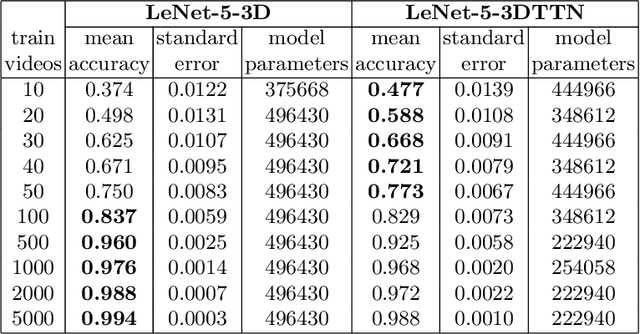
3D convolutional neural networks are difficult to train because they are parameter-expensive and data-hungry. To solve these problems we propose a simple technique for learning 3D convolutional kernels efficiently requiring less training data. We achieve this by factorizing the 3D kernel along the temporal dimension, reducing the number of parameters and making training from data more efficient. Additionally we introduce a novel dataset called Video-MNIST to demonstrate the performance of our method. Our method significantly outperforms the conventional 3D convolution in the low data regime (1 to 5 videos per class). Finally, our model achieves competitive results in the high data regime (>10 videos per class) using up to 45% fewer parameters.