 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Competitions and Benchmarks: Dataset Development
Apr 15, 2024



Machine learning is now used in many applications thanks to its ability to predict, generate, or discover patterns from large quantities of data. However, the process of collecting and transforming data for practical use is intricate. Even in today's digital era, where substantial data is generated daily, it is uncommon for it to be readily usable; most often, it necessitates meticulous manual data preparation. The haste in developing new models can frequently result in various shortcomings, potentially posing risks when deployed in real-world scenarios (eg social discrimination, critical failures), leading to the failure or substantial escalation of costs in AI-based projects. This chapter provides a comprehensive overview of established methodological tools, enriched by our practical experience, in the development of datasets for machine learning. Initially, we develop the tasks involved in dataset development and offer insights into their effective management (including requirements, design, implementation, evaluation, distribution, and maintenance). Then, we provide more details about the implementation process which includes data collection, transformation, and quality evaluation. Finally, we address practical considerations regarding dataset distribution and maintenance.
Person Perception Biases Exposed: Revisiting the First Impressions Dataset
Nov 30, 2020


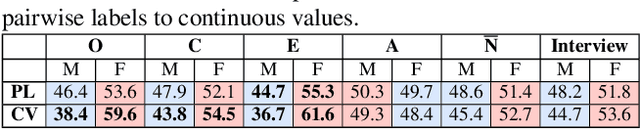
This work revisits the ChaLearn First Impressions database, annotated for personality perception using pairwise comparisons via crowdsourcing. We analyse for the first time the original pairwise annotations, and reveal existing person perception biases associated to perceived attributes like gender, ethnicity, age and face attractiveness. We show how person perception bias can influence data labelling of a subjective task, which has received little attention from the computer vision and machine learning communities by now. We further show that the mechanism used to convert pairwise annotations to continuous values may magnify the biases if no special treatment is considered. The findings of this study are relevant for the computer vision community that is still creating new datasets on subjective tasks, and using them for practical applications, ignoring these perceptual biases.
Multi-task human analysis in still images: 2D/3D pose, depth map, and multi-part segmentation
May 08, 2019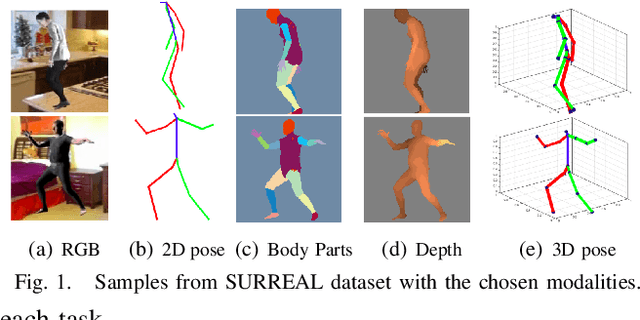
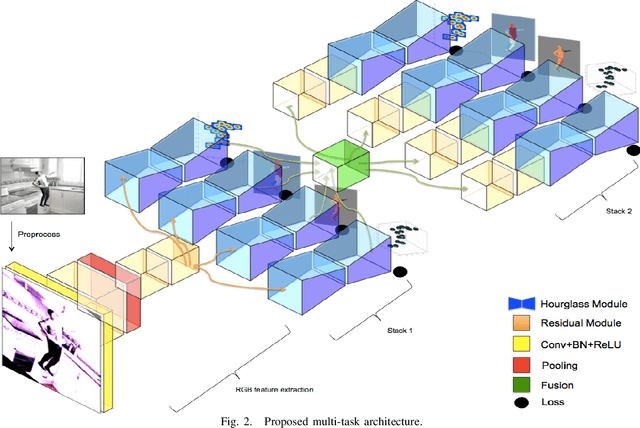


While many individual tasks in the domain of human analysis have recently received an accuracy boost from deep learning approaches, multi-task learning has mostly been ignored due to a lack of data. New synthetic datasets are being released, filling this gap with synthetic generated data. In this work, we analyze four related human analysis tasks in still images in a multi-task scenario by leveraging such datasets. Specifically, we study the correlation of 2D/3D pose estimation, body part segmentation and full-body depth estimation. These tasks are learned via the well-known Stacked Hourglass module such that each of the task-specific streams shares information with the others. The main goal is to analyze how training together these four related tasks can benefit each individual task for a better generalization. Results on the newly released SURREAL dataset show that all four tasks benefit from the multi-task approach, but with different combinations of tasks: while combining all four tasks improves 2D pose estimation the most, 2D pose improves neither 3D pose nor full-body depth estimation. On the other hand 2D parts segmentation can benefit from 2D pose but not from 3D pose. In all cases, as expected, the maximum improvement is achieved on those human body parts that show more variability in terms of spatial distribution, appearance and shape, e.g. wrists and ankles.
On the effect of age perception biases for real age regression
Feb 20, 2019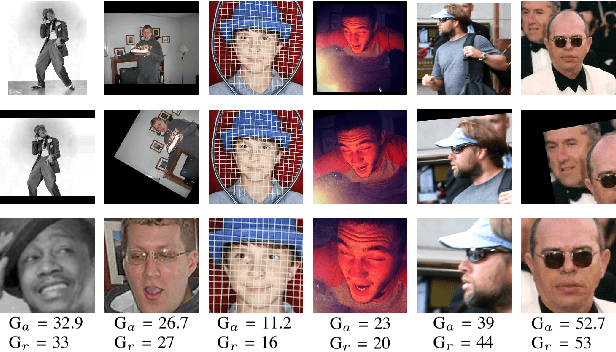
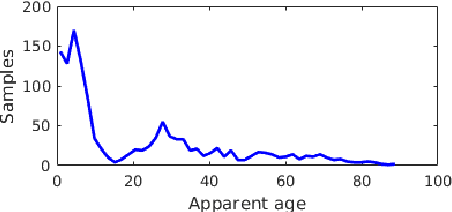
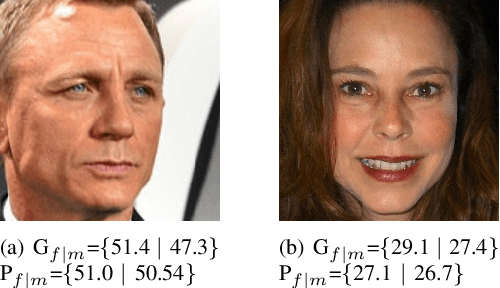

Automatic age estimation from facial images represents an important task in computer vision. This paper analyses the effect of gender, age, ethnic, makeup and expression attributes of faces as sources of bias to improve deep apparent age prediction. Following recent works where it is shown that apparent age labels benefit real age estimation, rather than direct real to real age regression, our main contribution is the integration, in an end-to-end architecture, of face attributes for apparent age prediction with an additional loss for real age regression. Experimental results on the APPA-REAL dataset indicate the proposed network successfully take advantage of the adopted attributes to improve both apparent and real age estimation. Our model outperformed a state-of-the-art architecture proposed to separately address apparent and real age regression. Finally, we present preliminary results and discussion of a proof of concept application using the proposed model to regress the apparent age of an individual based on the gender of an external observer.
First Impressions: A Survey on Computer Vision-Based Apparent Personality Trait Analysis
Apr 21, 2018
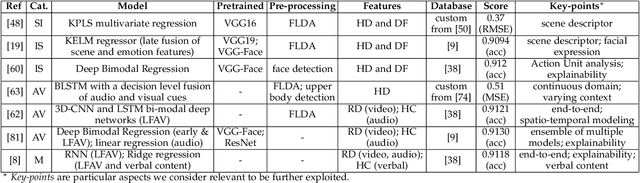
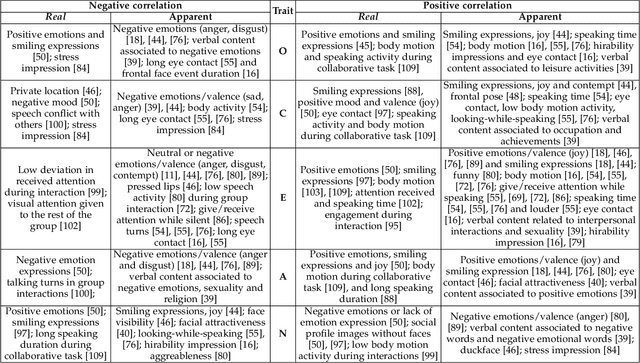
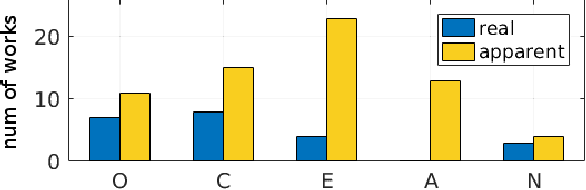
Personality analysis has been widely studied in psychology, neuropsychology, signal processing fields, among others. From the computing point of view, by far speech and text have been the most analyzed cues of information for analyzing personality. However, recently there has been an increasing interest form the computer vision community in analyzing personality starting from visual information. Recent computer vision approaches are able to accurately analyze human faces, body postures and behaviors, and use these information to infer apparent personality traits. Because of the overwhelming research interest in this topic, and of the potential impact that this sort of methods could have in society, we present in this paper an up-to-date review of existing computer vision-based visual and multimodal approaches for apparent personality trait recognition. We describe seminal and cutting edge works on the subject, discussing and comparing their distinctive features. More importantly, future venues of research in the field are identified and discussed. Furthermore, aspects on the subjectivity in data labeling/evaluation, as well as current datasets and challenges organized to push the research on the field are reviewed. Hence, the survey provides an up-to-date review of research progress in a wide range of aspects of this research theme.
Exploiting feature representations through similarity learning, post-ranking and ranking aggregation for person re-identification
Apr 12, 2018



Person re-identification has received special attention by the human analysis community in the last few years. To address the challenges in this field, many researchers have proposed different strategies, which basically exploit either cross-view invariant features or cross-view robust metrics. In this work, we propose to exploit a post-ranking approach and combine different feature representations through ranking aggregation. Spatial information, which potentially benefits the person matching, is represented using a 2D body model, from which color and texture information are extracted and combined. We also consider background/foreground information, automatically extracted via Deep Decompositional Network, and the usage of Convolutional Neural Network (CNN) features. To describe the matching between images we use the polynomial feature map, also taking into account local and global information. The Discriminant Context Information Analysis based post-ranking approach is used to improve initial ranking lists. Finally, the Stuart ranking aggregation method is employed to combine complementary ranking lists obtained from different feature representations. Experimental results demonstrated that we improve the state-of-the-art on VIPeR and PRID450s datasets, achieving 67.21% and 75.64% on top-1 rank recognition rate, respectively, as well as obtaining competitive results on CUHK01 dataset.
End-to-end semantic face segmentation with conditional random fields as convolutional, recurrent and adversarial networks
Mar 09, 2017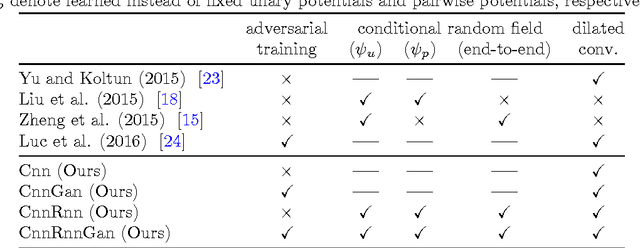
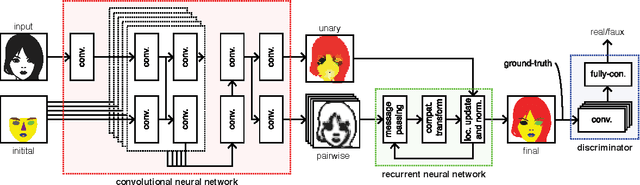
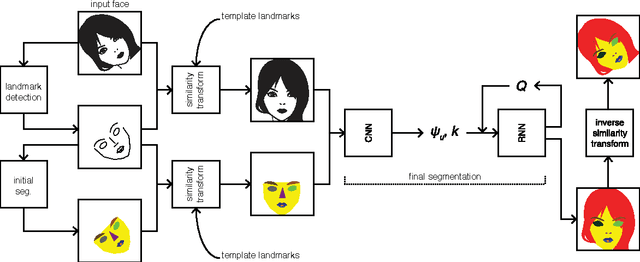
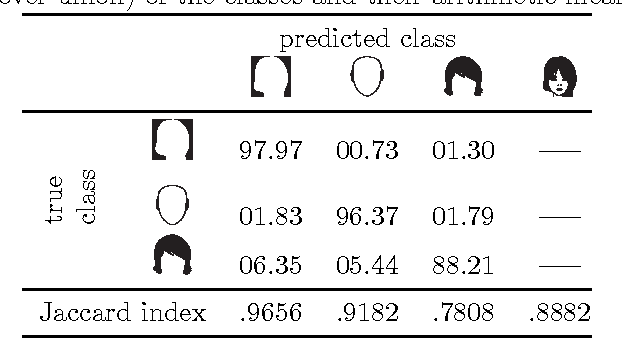
Recent years have seen a sharp increase in the number of related yet distinct advances in semantic segmentation. Here, we tackle this problem by leveraging the respective strengths of these advances. That is, we formulate a conditional random field over a four-connected graph as end-to-end trainable convolutional and recurrent networks, and estimate them via an adversarial process. Importantly, our model learns not only unary potentials but also pairwise potentials, while aggregating multi-scale contexts and controlling higher-order inconsistencies. We evaluate our model on two standard benchmark datasets for semantic face segmentation, achieving state-of-the-art results on both of them.
ChaLearn Looking at People: A Review of Events and Resources
Feb 15, 2017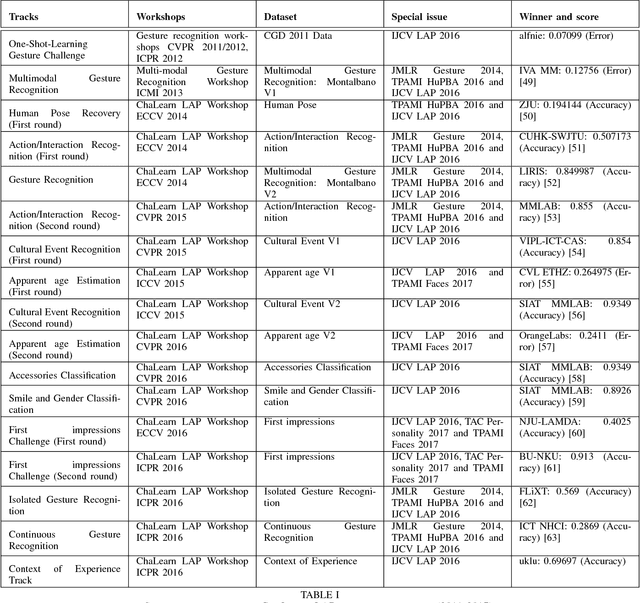
This paper reviews the historic of ChaLearn Looking at People (LAP) events. We started in 2011 (with the release of the first Kinect device) to run challenges related to human action/activity and gesture recognition. Since then we have regularly organized events in a series of competitions covering all aspects of visual analysis of humans. So far we have organized more than 10 international challenges and events in this field. This paper reviews associated events, and introduces the ChaLearn LAP platform where public resources (including code, data and preprints of papers) related to the organized events are available. We also provide a discussion on perspectives of ChaLearn LAP activities.
Non-Verbal Communication Analysis in Victim-Offender Mediations
Jan 19, 2015
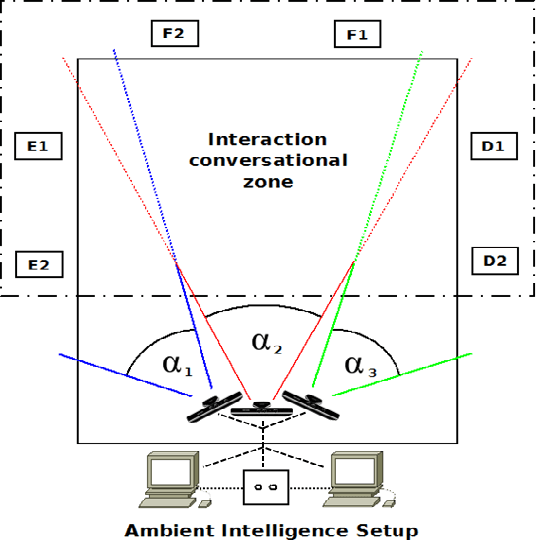
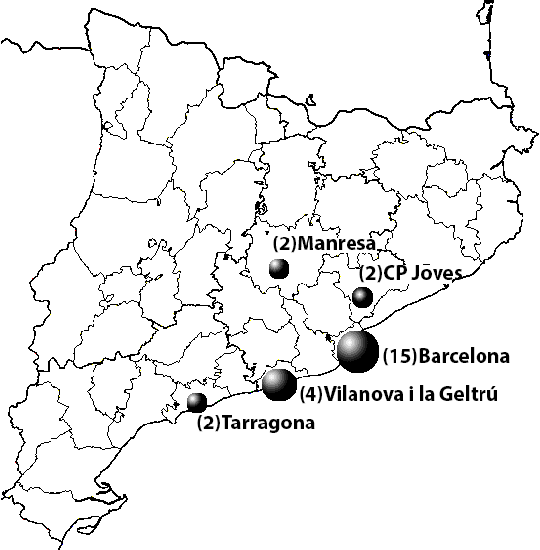
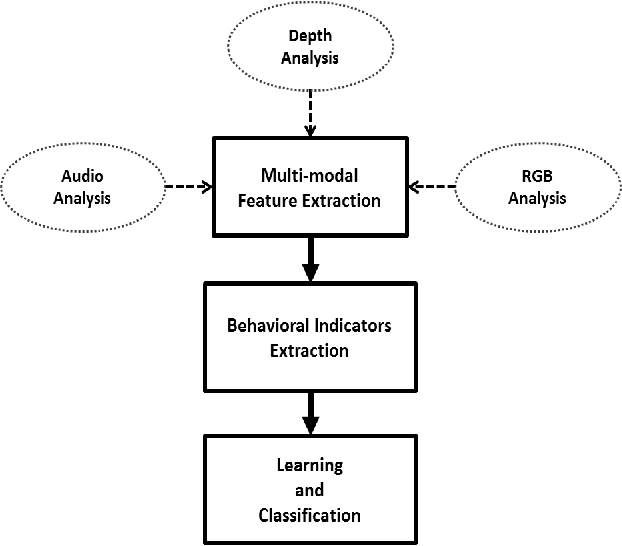
In this paper we present a non-invasive ambient intelligence framework for the semi-automatic analysis of non-verbal communication applied to the restorative justice field. In particular, we propose the use of computer vision and social signal processing technologies in real scenarios of Victim-Offender Mediations, applying feature extraction techniques to multi-modal audio-RGB-depth data. We compute a set of behavioral indicators that define communicative cues from the fields of psychology and observational methodology. We test our methodology on data captured in real world Victim-Offender Mediation sessions in Catalonia in collaboration with the regional government. We define the ground truth based on expert opinions when annotating the observed social responses. Using different state-of-the-art binary classification approaches, our system achieves recognition accuracies of 86% when predicting satisfaction, and 79% when predicting both agreement and receptivity. Applying a regression strategy, we obtain a mean deviation for the predictions between 0.5 and 0.7 in the range [1-5] for the computed social signals.