 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task human analysis in still images: 2D/3D pose, depth map, and multi-part segmentation
May 08, 2019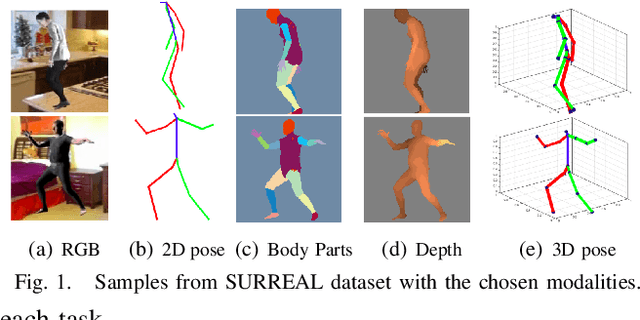
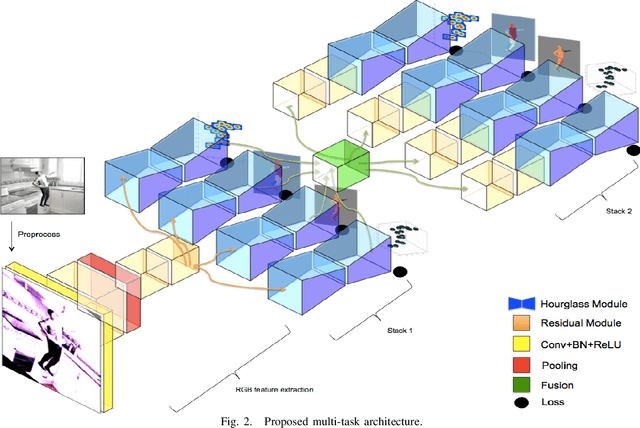


While many individual tasks in the domain of human analysis have recently received an accuracy boost from deep learning approaches, multi-task learning has mostly been ignored due to a lack of data. New synthetic datasets are being released, filling this gap with synthetic generated data. In this work, we analyze four related human analysis tasks in still images in a multi-task scenario by leveraging such datasets. Specifically, we study the correlation of 2D/3D pose estimation, body part segmentation and full-body depth estimation. These tasks are learned via the well-known Stacked Hourglass module such that each of the task-specific streams shares information with the others. The main goal is to analyze how training together these four related tasks can benefit each individual task for a better generalization. Results on the newly released SURREAL dataset show that all four tasks benefit from the multi-task approach, but with different combinations of tasks: while combining all four tasks improves 2D pose estimation the most, 2D pose improves neither 3D pose nor full-body depth estimation. On the other hand 2D parts segmentation can benefit from 2D pose but not from 3D pose. In all cases, as expected, the maximum improvement is achieved on those human body parts that show more variability in terms of spatial distribution, appearance and shape, e.g. wrists and ankles.
Folded Recurrent Neural Networks for Future Video Prediction
Mar 16, 2018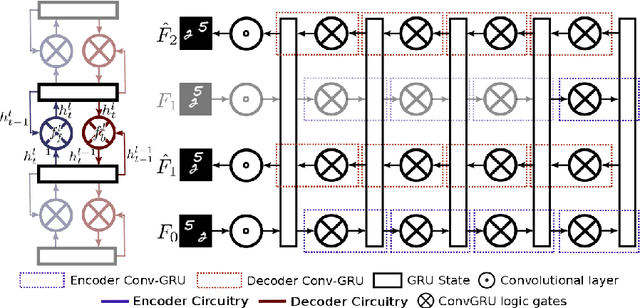

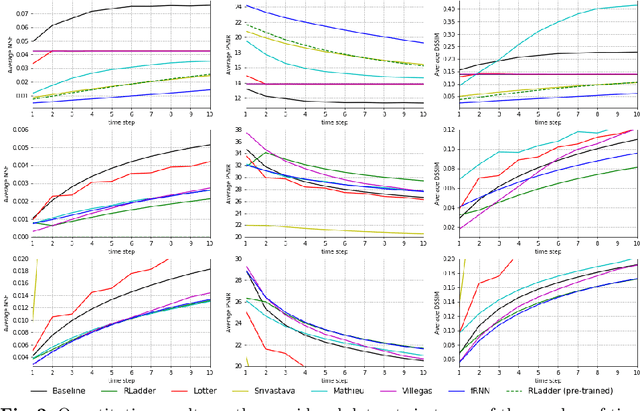

Future video prediction is an ill-posed Computer Vision problem that recently received much attention. Its main challenges are the high variability in video content, the propagation of errors through time, and the non-specificity of the future frames: given a sequence of past frames there is a continuous distribution of possible futures. This work introduces bijective Gated Recurrent Units, a double mapping between the input and output of a GRU layer. This allows for recurrent auto-encoders with state sharing between encoder and decoder, stratifying the sequence representation and helping to prevent capacity problems. We show how with this topology only the encoder or decoder needs to be applied for input encoding and prediction, respectively. This reduces the computational cost and avoids re-encoding the predictions when generating a sequence of frames, mitigating the propagation of errors. Furthermore, it is possible to remove layers from an already trained model, giving an insight to the role performed by each layer and making the model more explainable. We evaluate our approach on three video datasets, outperforming state of the art prediction results on MMNIST and UCF101, and obtaining competitive results on KTH with 2 and 3 times less memory usage and computational cost than the best scored approach.
Survey on RGB, 3D, Thermal, and Multimodal Approaches for Facial Expression Recognition: History, Trends, and Affect-related Applications
Jun 10, 2016
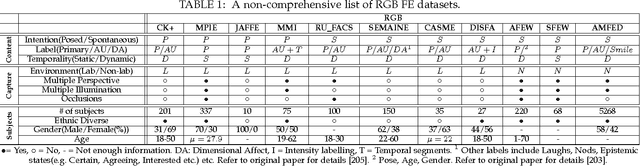

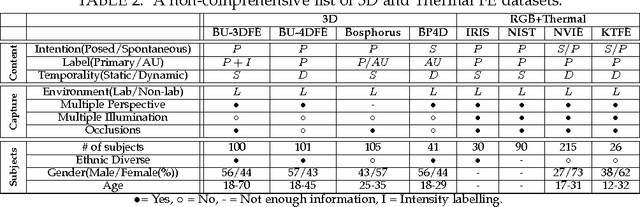
Facial expressions are an important way through which humans interact socially. Building a system capable of automatically recognizing facial expressions from images and video has been an intense field of study in recent years. Interpreting such expressions remains challenging and much research is needed about the way they relate to human affect. This paper presents a general overview of automatic RGB, 3D, thermal and multimodal facial expression analysis. We define a new taxonomy for the field, encompassing all steps from face detection to facial expression recognition, and describe and classify the state of the art methods accordingly. We also present the important datasets and the bench-marking of most influential methods. We conclude with a general discussion about trends, important questions and future lines of research.