 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Bayesian Deep Learning: The Application of Statistical Aggregation Methods to Bayesian Models
Apr 04, 2024Federated learning (FL) is an approach to training machine learning models that takes advantage of multiple distributed datasets while maintaining data privacy and reducing communication costs associated with sharing local datasets. Aggregation strategies have been developed to pool or fuse the weights and biases of distributed deterministic models; however, modern deterministic deep learning (DL) models are often poorly calibrated and lack the ability to communicate a measure of epistemic uncertainty in prediction, which is desirable for remote sensing platforms and safety-critical applications. Conversely, Bayesian DL models are often well calibrated and capable of quantifying and communicating a measure of epistemic uncertainty along with a competitive prediction accuracy. Unfortunately, because the weights and biases in Bayesian DL models are defined by a probability distribution, simple application of the aggregation methods associated with FL schemes for deterministic models is either impossible or results in sub-optimal performance. In this work, we use independent and identically distributed (IID) and non-IID partitions of the CIFAR-10 dataset and a fully variational ResNet-20 architecture to analyze six different aggregation strategies for Bayesian DL models. Additionally, we analyze the traditional federated averaging approach applied to an approximate Bayesian Monte Carlo dropout model as a lightweight alternative to more complex variational inference methods in FL. We show that aggregation strategy is a key hyperparameter in the design of a Bayesian FL system with downstream effects on accuracy, calibration, uncertainty quantification, training stability, and client compute requirements.
Concrete Safety for ML Problems: System Safety for ML Development and Assessment
Feb 06, 2023
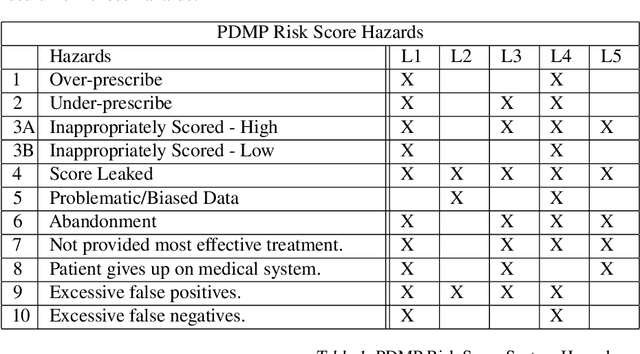
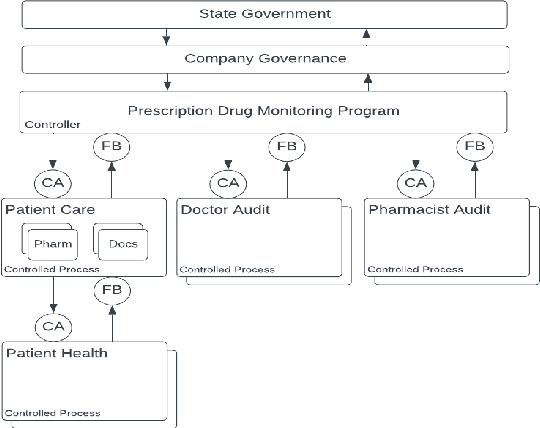
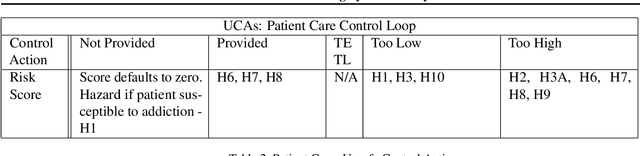
Many stakeholders struggle to make reliances on ML-driven systems due to the risk of harm these systems may cause. Concerns of trustworthiness, unintended social harms, and unacceptable social and ethical violations undermine the promise of ML advancements. Moreover, such risks in complex ML-driven systems present a special challenge as they are often difficult to foresee, arising over periods of time, across populations, and at scale. These risks often arise not from poor ML development decisions or low performance directly but rather emerge through the interactions amongst ML development choices, the context of model use, environmental factors, and the effects of a model on its target. Systems safety engineering is an established discipline with a proven track record of identifying and managing risks even in high-complexity sociotechnical systems. In this work, we apply a state-of-the-art systems safety approach to concrete applications of ML with notable social and ethical risks to demonstrate a systematic means for meeting the assurance requirements needed to argue for safe and trustworthy ML in sociotechnical systems.
VICE: Variational Interpretable Concept Embeddings
May 13, 2022

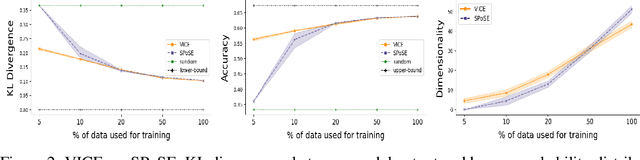
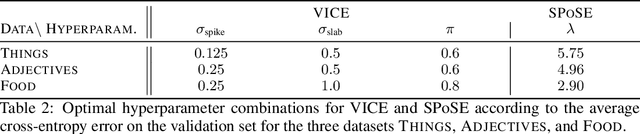
A central goal in the cognitive sciences is the development of computational models of mental representations of object concepts. This paper introduces Variational Interpretable Concept Embeddings (VICE), an approximate Bayesian method for learning interpretable object concept embeddings from human behavior in an odd-one-out triplet task. We use variational inference to obtain a sparse, non-negative solution with uncertainty estimates about each embedding value. We exploit these estimates to select the dimensions that explain the data automatically. We introduce a PAC learning bound for VICE that can be used to estimate generalization performance or determine a sufficient sample size for different experimental designs. VICE rivals or outperforms its predecessor, SPoSE, at predicting human behavior in the odd-one-out triplet task. Furthermore, VICE object representations are substantially more reproducible and consistent across random initializations.
A Deep Neural Network Tool for Automatic Segmentation of Human Body Parts in Natural Scenes
Sep 08, 2020
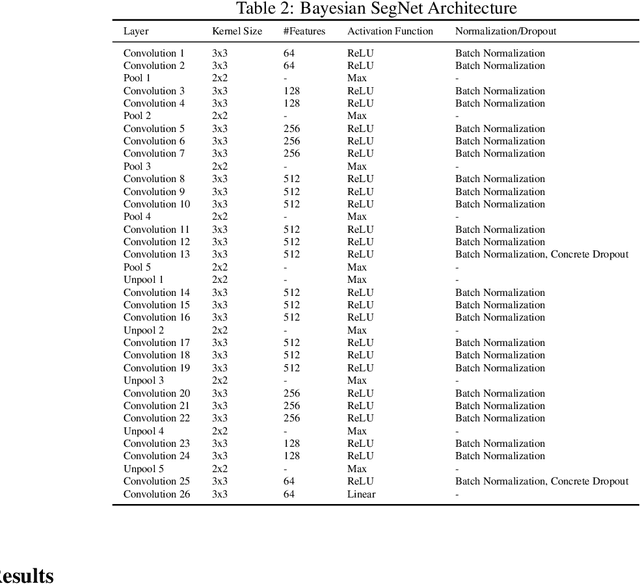

This short article describes a deep neural network trained to perform automatic segmentation of human body parts in natural scenes. More specifically, we trained a Bayesian SegNet with concrete dropout on the Pascal-Parts dataset to predict whether each pixel in a given frame was part of a person's hair, head, ear, eyebrows, legs, arms, mouth, neck, nose, or torso.
Evaluating Adversarial Robustness for Deep Neural Network Interpretability using fMRI Decoding
Apr 23, 2020

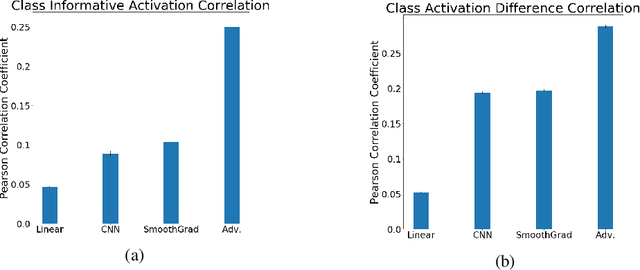
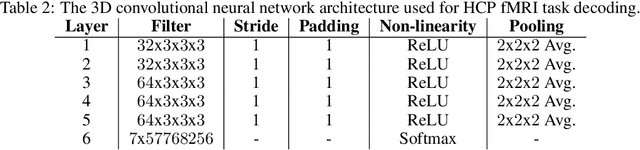
While deep neural networks (DNNs) are being increasingly used to make predictions from high-dimensional, complex data, they are widely seen as uninterpretable "black boxes", since it can be difficult to discover what input information is used to make predictions. This ability is particularly important for applications in cognitive neuroscience and neuroinformatics. A saliency map is a common approach for producing interpretable visualizations of the relative importance of input features for a prediction. However, many methods for creating these maps fail due to focusing too much on the input or being extremely sensitive to small input noise. It is also challenging to quantitatively evaluate how well saliency maps correspond to the truly relevant input information. In this paper, we develop two quantitative evaluation procedures for saliency methods, using the fact that the Human Connectome Project (HCP) dataset contains functional magnetic resonance imaging(fMRI) data from multiple tasks per subject to create ground truth saliency maps.We then introduce an adversarial training method that makes DNNs robust to small input noise, and use these evaluations to demonstrate that it greatly improves interpretability.
Knowing what you know in brain segmentation using deep neural networks
Dec 18, 2018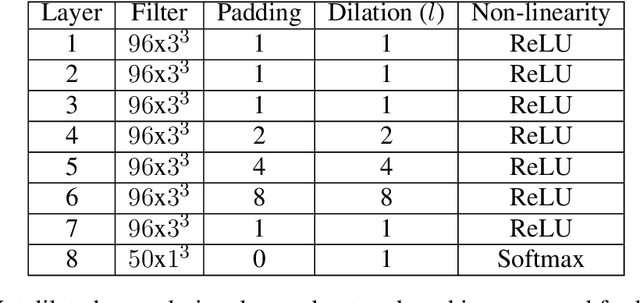
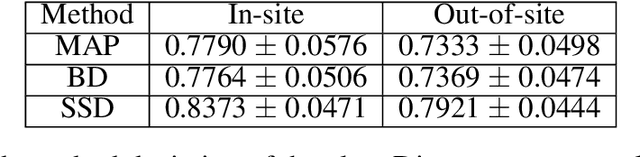
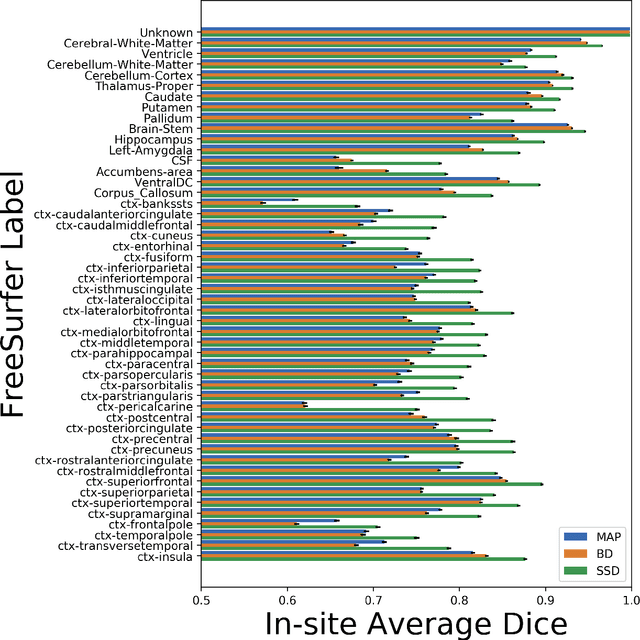
In this paper, we describe a deep neural network trained to predict FreeSurfer segmentations of structural MRI volumes, in seconds rather than hours. The network was trained and evaluated on an extremely large dataset (n = 11,148), obtained by combining data from more than a hundred sites. We also show that the prediction uncertainty of the network at each voxel is a good indicator of whether the network has made an error. The resulting uncertainty volume can be used in conjunction with the predicted segmentation to improve downstream uses, such as calculation of measures derived from segmentation regions of interest or the building of prediction models. Finally, we demonstrate that the average prediction uncertainty across voxels in the brain is an excellent indicator of manual quality control ratings, outperforming the best available automated solutions.
Distributed Weight Consolidation: A Brain Segmentation Case Study
Oct 12, 2018
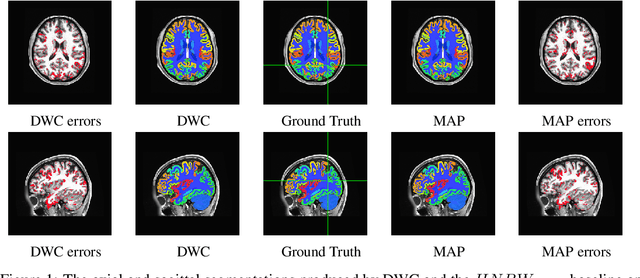
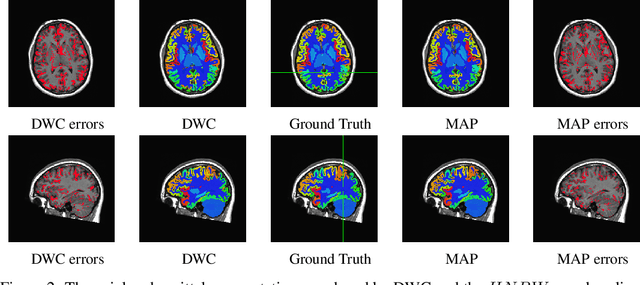
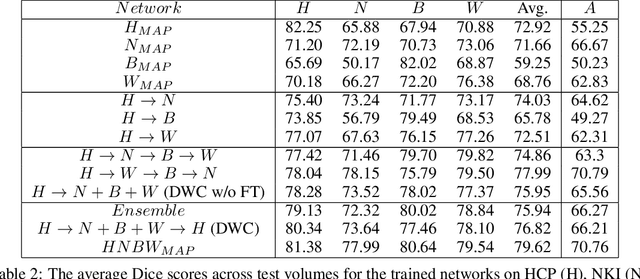
Collecting the large datasets needed to train deep neural networks can be very difficult, particularly for the many applications for which sharing and pooling data is complicated by practical, ethical, or legal concerns. However, it may be the case that derivative datasets or predictive models developed within individual sites can be shared and combined with fewer restrictions. Training on distributed data and combining the resulting networks is often viewed as continual learning, but these methods require networks to be trained sequentially. In this paper, we introduce distributed weight consolidation (DWC), a continual learning method to consolidate the weights of separate neural networks, each trained on an independent dataset. We evaluated DWC with a brain segmentation case study, where we consolidated dilated convolutional neural networks trained on independent structural magnetic resonance imaging (sMRI) datasets from different sites. We found that DWC led to increased performance on test sets from the different sites, while maintaining generalization performance for a very large and completely independent multi-site dataset, compared to an ensemble baseline.
Robustly representing uncertainty in deep neural networks through sampling
Jan 20, 2018



As deep neural networks (DNNs) are applied to increasingly challenging problems, they will need to be able to represent their own uncertainty. Modeling uncertainty is one of the key features of Bayesian methods. Using Bernoulli dropout with sampling at prediction time has recently been proposed as an efficient and well performing variational inference method for DNNs. However, sampling from other multiplicative noise based variational distributions has not been investigated in depth. We evaluated Bayesian DNNs trained with Bernoulli or Gaussian multiplicative masking of either the units (dropout) or the weights (dropconnect). We tested the calibration of the probabilistic predictions of Bayesian convolutional neural networks (CNNs) on MNIST and CIFAR-10. Sampling at prediction time increased the calibration of the DNNs' probabalistic predictions. Sampling weights, whether Gaussian or Bernoulli, led to more robust representation of uncertainty compared to sampling of units. However, using either Gaussian or Bernoulli dropout led to increased test set classification accuracy. Based on these findings we used both Bernoulli dropout and Gaussian dropconnect concurrently, which we show approximates the use of a spike-and-slab variational distribution without increasing the number of learned parameters. We found that spike-and-slab sampling had higher test set performance than Gaussian dropconnect and more robustly represented its uncertainty compared to Bernoulli dropout.
Representational Distance Learning for Deep Neural Networks
Nov 07, 2016



Deep neural networks (DNNs) provide useful models of visual representational transformations. We present a method that enables a DNN (student) to learn from the internal representational spaces of a reference model (teacher), which could be another DNN or, in the future, a biological brain. Representational spaces of the student and the teacher are characterized by representational distance matrices (RDMs). We propose representational distance learning (RDL), a stochastic gradient descent method that drives the RDMs of the student to approximate the RDMs of the teacher. We demonstrate that RDL is competitive with other transfer learning techniques for two publicly available benchmark computer vision datasets (MNIST and CIFAR-100), while allowing for architectural differences between student and teacher. By pulling the student's RDMs towards those of the teacher, RDL significantly improved visual classification performance when compared to baseline networks that did not use transfer learning. In the future, RDL may enable combined supervised training of deep neural networks using task constraints (e.g. images and category labels) and constraints from brain-activity measurements, so as to build models that replicate the internal representational spaces of biological brains.