 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Deep Learning Embeddings for Speech Emotion Recognition by Predicting Interpretable Acoustic Features
Sep 14, 2024Pre-trained deep learning embeddings have consistently shown superior performance over handcrafted acoustic features in speech emotion recognition (SER). However, unlike acoustic features with clear physical meaning, these embeddings lack clear interpretability. Explaining these embeddings is crucial for building trust in healthcare and security applications and advancing the scientific understanding of the acoustic information that is encoded in them. This paper proposes a modified probing approach to explain deep learning embeddings in the SER space. We predict interpretable acoustic features (e.g., f0, loudness) from (i) the complete set of embeddings and (ii) a subset of the embedding dimensions identified as most important for predicting each emotion. If the subset of the most important dimensions better predicts a given emotion than all dimensions and also predicts specific acoustic features more accurately, we infer those acoustic features are important for the embedding model for the given task. We conducted experiments using the WavLM embeddings and eGeMAPS acoustic features as audio representations, applying our method to the RAVDESS and SAVEE emotional speech datasets. Based on this evaluation, we demonstrate that Energy, Frequency, Spectral, and Temporal categories of acoustic features provide diminishing information to SER in that order, demonstrating the utility of the probing classifier method to relate embeddings to interpretable acoustic features.
Knowing what you know in brain segmentation using deep neural networks
Dec 18, 2018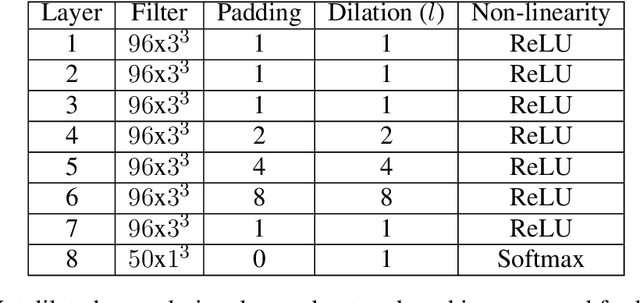
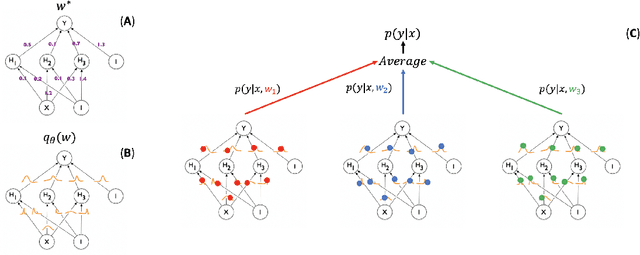
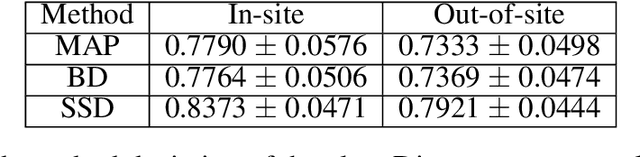
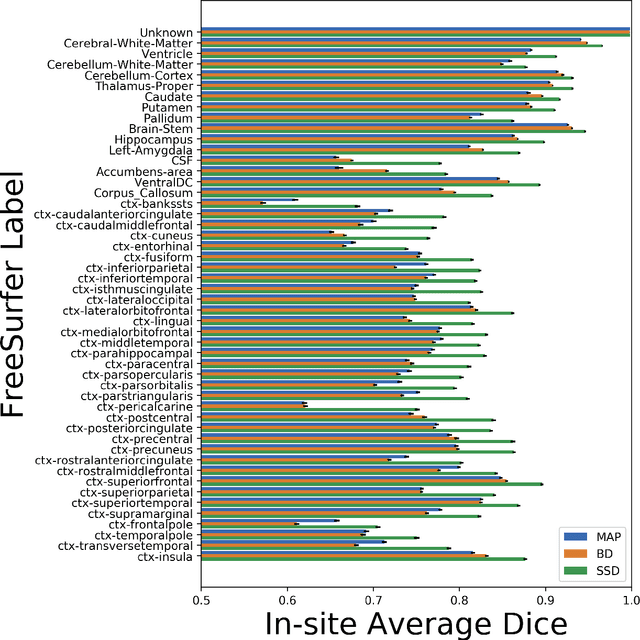
In this paper, we describe a deep neural network trained to predict FreeSurfer segmentations of structural MRI volumes, in seconds rather than hours. The network was trained and evaluated on an extremely large dataset (n = 11,148), obtained by combining data from more than a hundred sites. We also show that the prediction uncertainty of the network at each voxel is a good indicator of whether the network has made an error. The resulting uncertainty volume can be used in conjunction with the predicted segmentation to improve downstream uses, such as calculation of measures derived from segmentation regions of interest or the building of prediction models. Finally, we demonstrate that the average prediction uncertainty across voxels in the brain is an excellent indicator of manual quality control ratings, outperforming the best available automated solutions.
Distributed Weight Consolidation: A Brain Segmentation Case Study
Oct 12, 2018
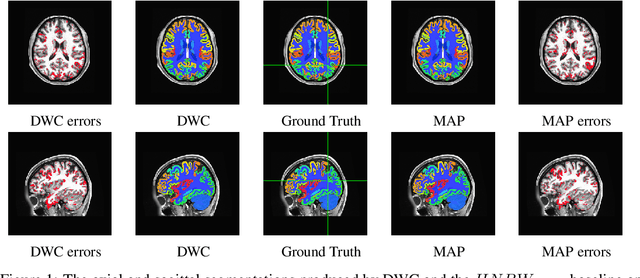
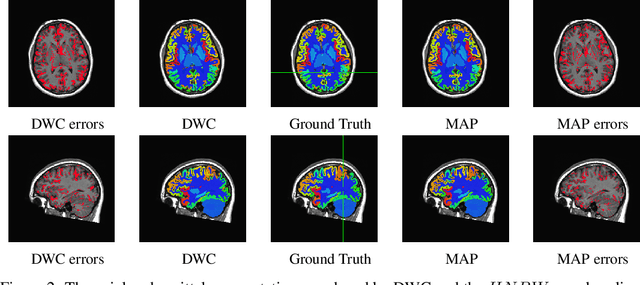
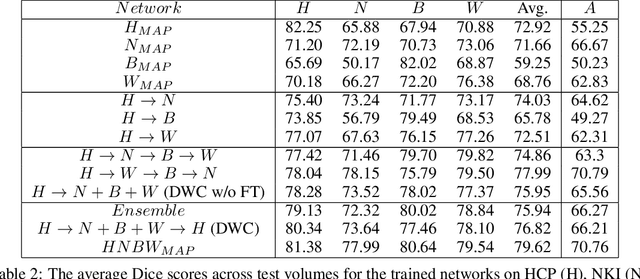
Collecting the large datasets needed to train deep neural networks can be very difficult, particularly for the many applications for which sharing and pooling data is complicated by practical, ethical, or legal concerns. However, it may be the case that derivative datasets or predictive models developed within individual sites can be shared and combined with fewer restrictions. Training on distributed data and combining the resulting networks is often viewed as continual learning, but these methods require networks to be trained sequentially. In this paper, we introduce distributed weight consolidation (DWC), a continual learning method to consolidate the weights of separate neural networks, each trained on an independent dataset. We evaluated DWC with a brain segmentation case study, where we consolidated dilated convolutional neural networks trained on independent structural magnetic resonance imaging (sMRI) datasets from different sites. We found that DWC led to increased performance on test sets from the different sites, while maintaining generalization performance for a very large and completely independent multi-site dataset, compared to an ensemble baseline.