 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReusable specimen-level inference in computational pathology
Jan 10, 2025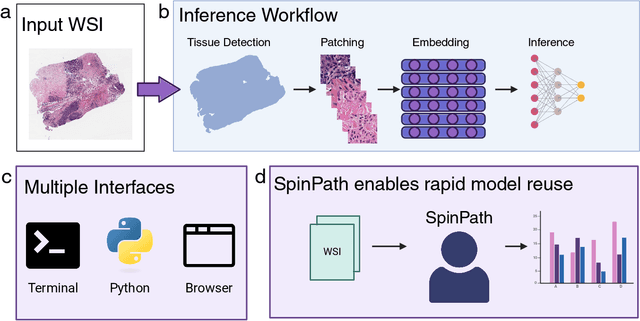
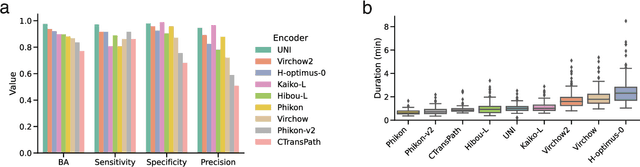
Foundation models for computational pathology have shown great promise for specimen-level tasks and are increasingly accessible to researchers. However, specimen-level models built on these foundation models remain largely unavailable, hindering their broader utility and impact. To address this gap, we developed SpinPath, a toolkit designed to democratize specimen-level deep learning by providing a zoo of pretrained specimen-level models, a Python-based inference engine, and a JavaScript-based inference platform. We demonstrate the utility of SpinPath in metastasis detection tasks across nine foundation models. SpinPath may foster reproducibility, simplify experimentation, and accelerate the adoption of specimen-level deep learning in computational pathology research.
Open and reusable deep learning for pathology with WSInfer and QuPath
Sep 08, 2023The field of digital pathology has seen a proliferation of deep learning models in recent years. Despite substantial progress, it remains rare for other researchers and pathologists to be able to access models published in the literature and apply them to their own images. This is due to difficulties in both sharing and running models. To address these concerns, we introduce WSInfer: a new, open-source software ecosystem designed to make deep learning for pathology more streamlined and accessible. WSInfer comprises three main elements: 1) a Python package and command line tool to efficiently apply patch-based deep learning inference to whole slide images; 2) a QuPath extension that provides an alternative inference engine through user-friendly and interactive software, and 3) a model zoo, which enables pathology models and metadata to be easily shared in a standardized form. Together, these contributions aim to encourage wider reuse, exploration, and interrogation of deep learning models for research purposes, by putting them into the hands of pathologists and eliminating a need for coding experience when accessed through QuPath. The WSInfer source code is hosted on GitHub and documentation is available at https://wsinfer.readthedocs.io.
Evaluating histopathology transfer learning with ChampKit
Jun 14, 2022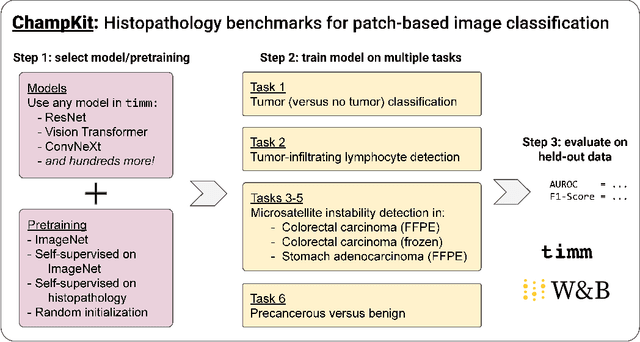
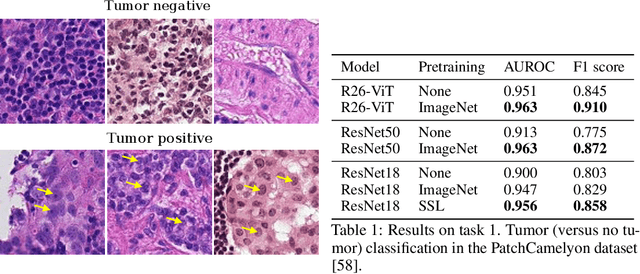
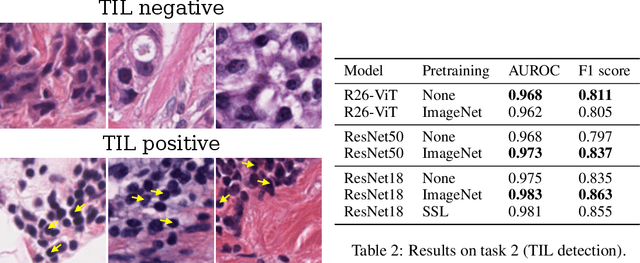
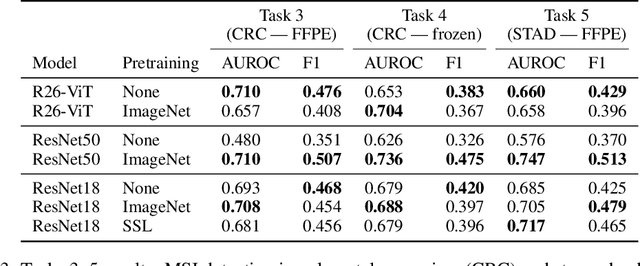
Histopathology remains the gold standard for diagnosis of various cancers. Recent advances in computer vision, specifically deep learning, have facilitated the analysis of histopathology images for various tasks, including immune cell detection and microsatellite instability classification. The state-of-the-art for each task often employs base architectures that have been pretrained for image classification on ImageNet. The standard approach to develop classifiers in histopathology tends to focus narrowly on optimizing models for a single task, not considering the aspects of modeling innovations that improve generalization across tasks. Here we present ChampKit (Comprehensive Histopathology Assessment of Model Predictions toolKit): an extensible, fully reproducible benchmarking toolkit that consists of a broad collection of patch-level image classification tasks across different cancers. ChampKit enables a way to systematically document the performance impact of proposed improvements in models and methodology. ChampKit source code and data are freely accessible at https://github.com/kaczmarj/champkit .
A Novel Framework for Characterization of Tumor-Immune Spatial Relationships in Tumor Microenvironment
May 01, 2022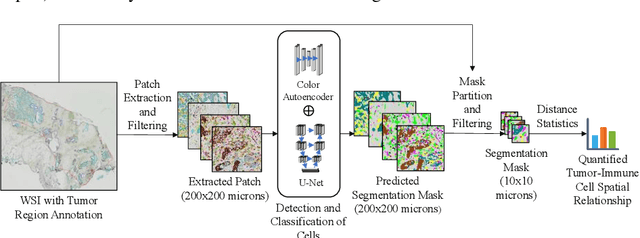

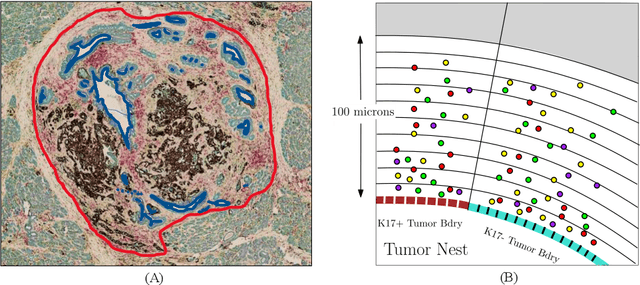
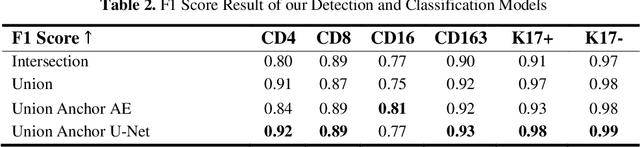
Understanding the impact of tumor biology on the composition of nearby cells often requires characterizing the impact of biologically distinct tumor regions. Biomarkers have been developed to label biologically distinct tumor regions, but challenges arise because of differences in the spatial extent and distribution of differentially labeled regions. In this work, we present a framework for systematically investigating the impact of distinct tumor regions on cells near the tumor borders, accounting their cross spatial distributions. We apply the framework to multiplex immunohistochemistry (mIHC) studies of pancreatic cancer and show its efficacy in demonstrating how biologically different tumor regions impact the immune response in the tumor microenvironment. Furthermore, we show that the proposed framework can be extended to largescale whole slide image analysis.
Knowing what you know in brain segmentation using deep neural networks
Dec 18, 2018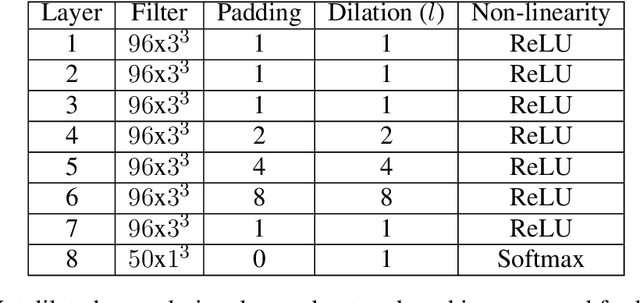
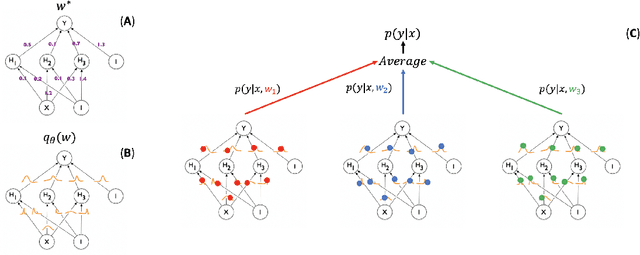
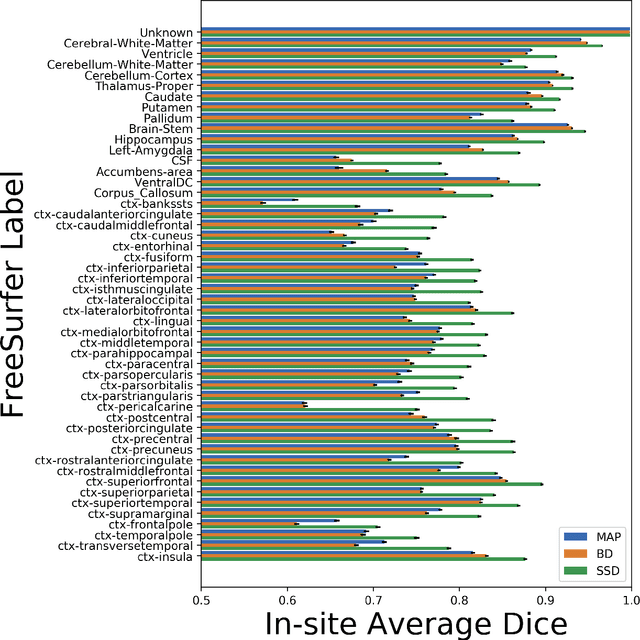
In this paper, we describe a deep neural network trained to predict FreeSurfer segmentations of structural MRI volumes, in seconds rather than hours. The network was trained and evaluated on an extremely large dataset (n = 11,148), obtained by combining data from more than a hundred sites. We also show that the prediction uncertainty of the network at each voxel is a good indicator of whether the network has made an error. The resulting uncertainty volume can be used in conjunction with the predicted segmentation to improve downstream uses, such as calculation of measures derived from segmentation regions of interest or the building of prediction models. Finally, we demonstrate that the average prediction uncertainty across voxels in the brain is an excellent indicator of manual quality control ratings, outperforming the best available automated solutions.
Distributed Weight Consolidation: A Brain Segmentation Case Study
Oct 12, 2018
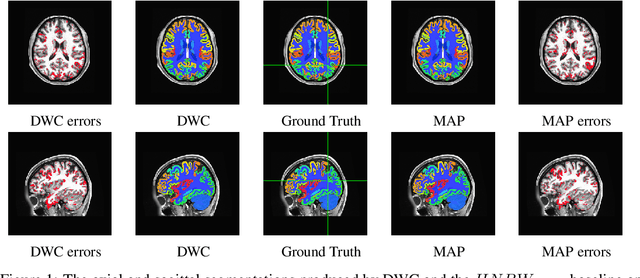
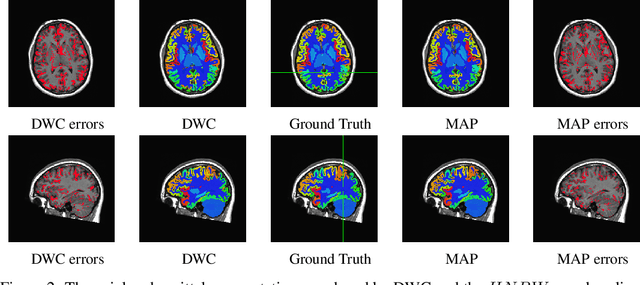
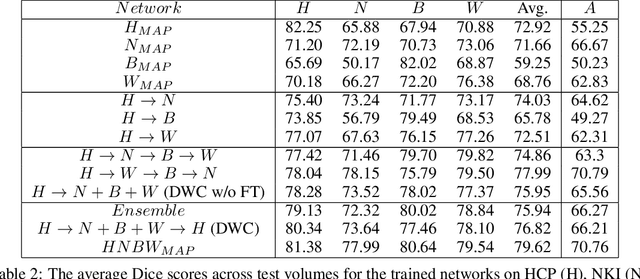
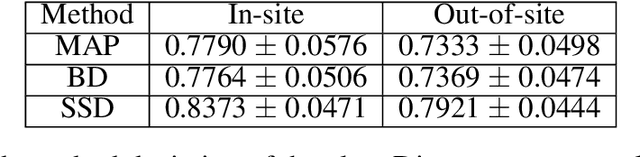
Collecting the large datasets needed to train deep neural networks can be very difficult, particularly for the many applications for which sharing and pooling data is complicated by practical, ethical, or legal concerns. However, it may be the case that derivative datasets or predictive models developed within individual sites can be shared and combined with fewer restrictions. Training on distributed data and combining the resulting networks is often viewed as continual learning, but these methods require networks to be trained sequentially. In this paper, we introduce distributed weight consolidation (DWC), a continual learning method to consolidate the weights of separate neural networks, each trained on an independent dataset. We evaluated DWC with a brain segmentation case study, where we consolidated dilated convolutional neural networks trained on independent structural magnetic resonance imaging (sMRI) datasets from different sites. We found that DWC led to increased performance on test sets from the different sites, while maintaining generalization performance for a very large and completely independent multi-site dataset, compared to an ensemble baseline.