 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Object Affordances Through Verb Usage Patterns
Jun 22, 2020
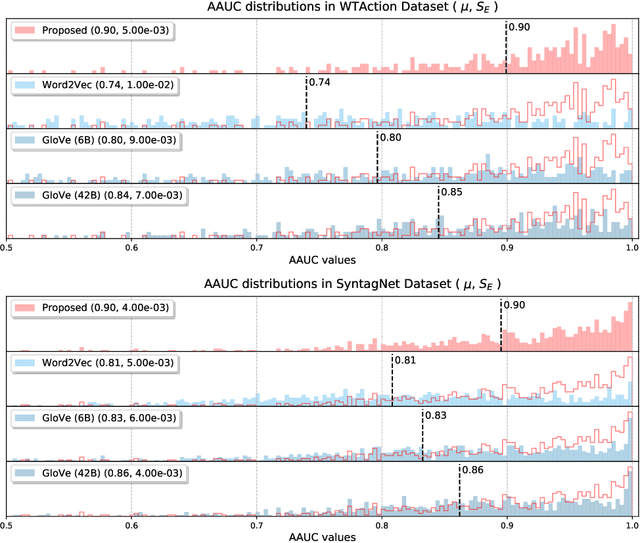
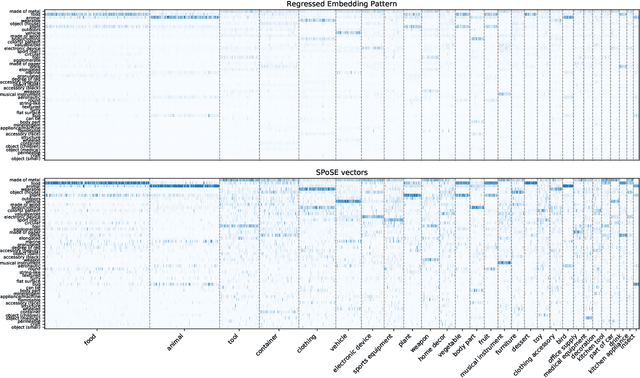

In order to interact with objects in our environment, we rely on an understanding of the actions that can be performed on them, and the extent to which they rely or have an effect on the properties of the object. This knowledge is called the object "affordance". We propose an approach for creating an embedding of objects in an affordance space, in which each dimension corresponds to an aspect of meaning shared by many actions, using text corpora. This embedding makes it possible to predict which verbs will be applicable to a given object, as captured in human judgments of affordance. We show that the dimensions learned are interpretable, and that they correspond to patterns of interaction with objects. Finally, we show that they can be used to predict other dimensions of object representation that have been shown to underpin human judgments of object similarity.