 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Contextual Informativeness in Child-Directed Text
Paper and Code
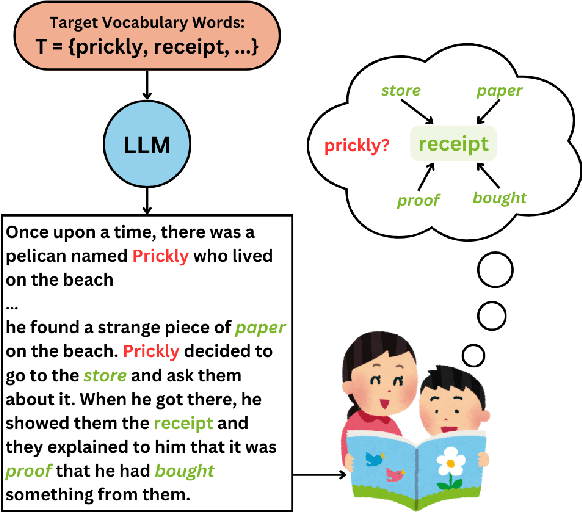
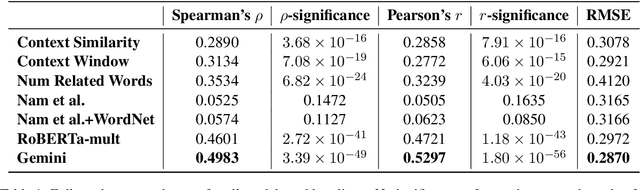
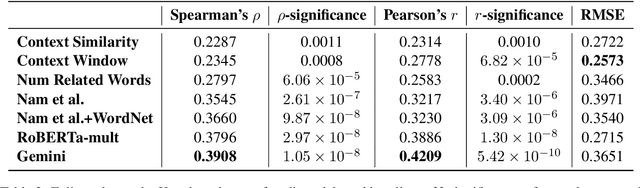
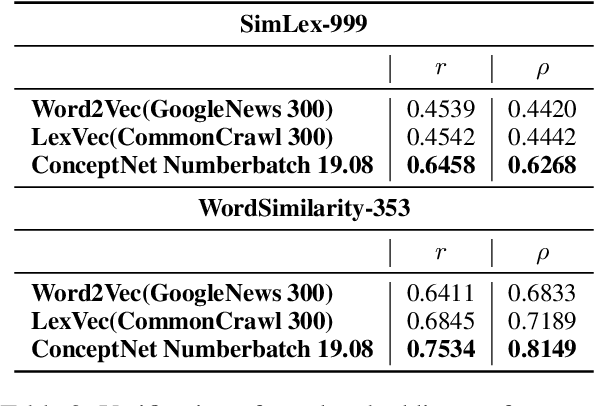
To address an important gap in creating children's stories for vocabulary enrichment, we investigate the automatic evaluation of how well stories convey the semantics of target vocabulary words, a task with substantial implications for generating educational content. We motivate this task, which we call measuring contextual informativeness in children's stories, and provide a formal task definition as well as a dataset for the task. We further propose a method for automating the task using a large language model (LLM). Our experiments show that our approach reaches a Spearman correlation of 0.4983 with human judgments of informativeness, while the strongest baseline only obtains a correlation of 0.3534. An additional analysis shows that the LLM-based approach is able to generalize to measuring contextual informativeness in adult-directed text, on which it also outperforms all baselines.