 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMassively Multilingual Joint Segmentation and Glossing
Jan 16, 2026Automated interlinear gloss prediction with neural networks is a promising approach to accelerate language documentation efforts. However, while state-of-the-art models like GlossLM achieve high scores on glossing benchmarks, user studies with linguists have found critical barriers to the usefulness of such models in real-world scenarios. In particular, existing models typically generate morpheme-level glosses but assign them to whole words without predicting the actual morpheme boundaries, making the predictions less interpretable and thus untrustworthy to human annotators. We conduct the first study on neural models that jointly predict interlinear glosses and the corresponding morphological segmentation from raw text. We run experiments to determine the optimal way to train models that balance segmentation and glossing accuracy, as well as the alignment between the two tasks. We extend the training corpus of GlossLM and pretrain PolyGloss, a family of seq2seq multilingual models for joint segmentation and glossing that outperforms GlossLM on glossing and beats various open-source LLMs on segmentation, glossing, and alignment. In addition, we demonstrate that PolyGloss can be quickly adapted to a new dataset via low-rank adaptation.
Untangling the Influence of Typology, Data and Model Architecture on Ranking Transfer Languages for Cross-Lingual POS Tagging
Mar 25, 2025Cross-lingual transfer learning is an invaluable tool for overcoming data scarcity, yet selecting a suitable transfer language remains a challenge. The precise roles of linguistic typology, training data, and model architecture in transfer language choice are not fully understood. We take a holistic approach, examining how both dataset-specific and fine-grained typological features influence transfer language selection for part-of-speech tagging, considering two different sources for morphosyntactic features. While previous work examines these dynamics in the context of bilingual biLSTMS, we extend our analysis to a more modern transfer learning pipeline: zero-shot prediction with pretrained multilingual models. We train a series of transfer language ranking systems and examine how different feature inputs influence ranker performance across architectures. Word overlap, type-token ratio, and genealogical distance emerge as top features across all architectures. Our findings reveal that a combination of typological and dataset-dependent features leads to the best rankings, and that good performance can be obtained with either feature group on its own.
Measuring Contextual Informativeness in Child-Directed Text
Dec 23, 2024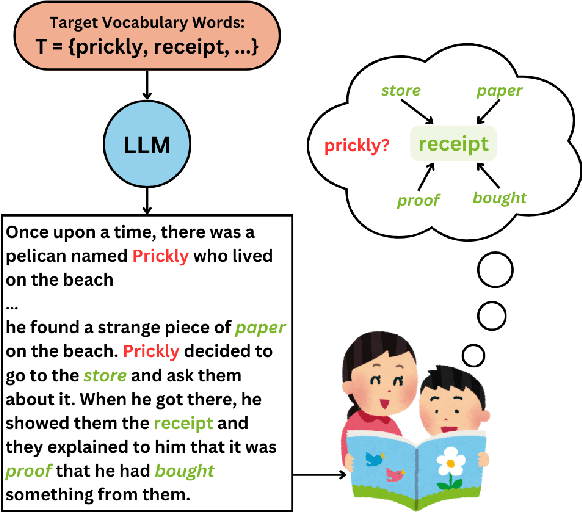
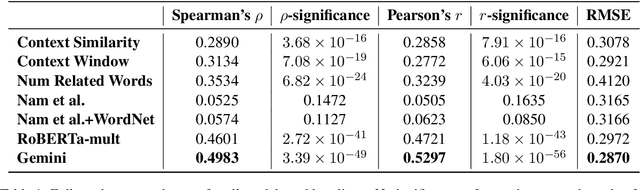
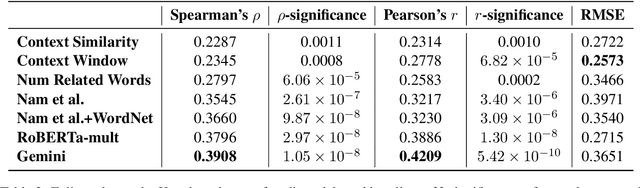
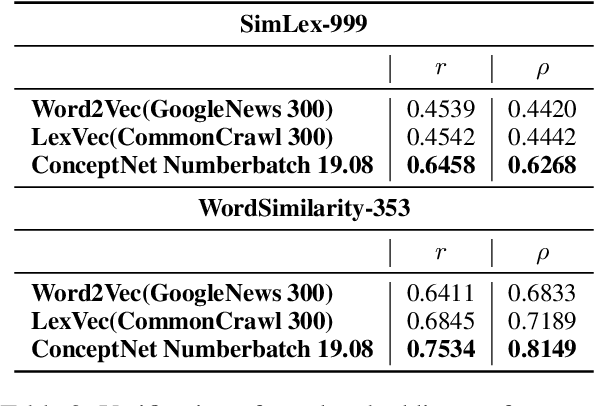
To address an important gap in creating children's stories for vocabulary enrichment, we investigate the automatic evaluation of how well stories convey the semantics of target vocabulary words, a task with substantial implications for generating educational content. We motivate this task, which we call measuring contextual informativeness in children's stories, and provide a formal task definition as well as a dataset for the task. We further propose a method for automating the task using a large language model (LLM). Our experiments show that our approach reaches a Spearman correlation of 0.4983 with human judgments of informativeness, while the strongest baseline only obtains a correlation of 0.3534. An additional analysis shows that the LLM-based approach is able to generalize to measuring contextual informativeness in adult-directed text, on which it also outperforms all baselines.
From Priest to Doctor: Domain Adaptaion for Low-Resource Neural Machine Translation
Dec 01, 2024Many of the world's languages have insufficient data to train high-performing general neural machine translation (NMT) models, let alone domain-specific models, and often the only available parallel data are small amounts of religious texts. Hence, domain adaptation (DA) is a crucial issue faced by contemporary NMT and has, so far, been underexplored for low-resource languages. In this paper, we evaluate a set of methods from both low-resource NMT and DA in a realistic setting, in which we aim to translate between a high-resource and a low-resource language with access to only: a) parallel Bible data, b) a bilingual dictionary, and c) a monolingual target-domain corpus in the high-resource language. Our results show that the effectiveness of the tested methods varies, with the simplest one, DALI, being most effective. We follow up with a small human evaluation of DALI, which shows that there is still a need for more careful investigation of how to accomplish DA for low-resource NMT.
TAMS: Translation-Assisted Morphological Segmentation
Mar 21, 2024



Canonical morphological segmentation is the process of analyzing words into the standard (aka underlying) forms of their constituent morphemes. This is a core task in language documentation, and NLP systems have the potential to dramatically speed up this process. But in typical language documentation settings, training data for canonical morpheme segmentation is scarce, making it difficult to train high quality models. However, translation data is often much more abundant, and, in this work, we present a method that attempts to leverage this data in the canonical segmentation task. We propose a character-level sequence-to-sequence model that incorporates representations of translations obtained from pretrained high-resource monolingual language models as an additional signal. Our model outperforms the baseline in a super-low resource setting but yields mixed results on training splits with more data. While further work is needed to make translations useful in higher-resource settings, our model shows promise in severely resource-constrained settings.
Robust Learning under Strong Noise via SQs
Oct 18, 2020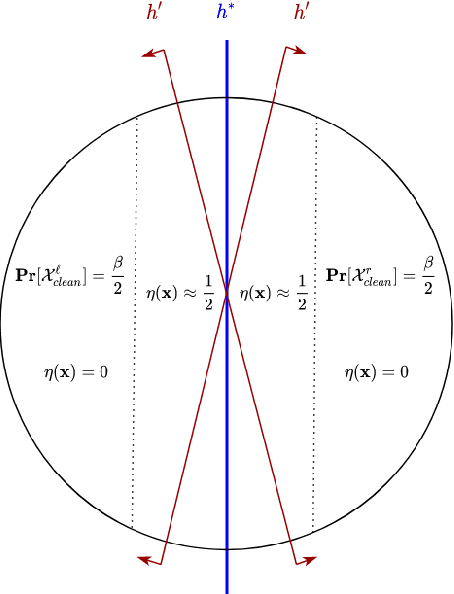
This work provides several new insights on the robustness of Kearns' statistical query framework against challenging label-noise models. First, we build on a recent result by \cite{DBLP:journals/corr/abs-2006-04787} that showed noise tolerance of distribution-independently evolvable concept classes under Massart noise. Specifically, we extend their characterization to more general noise models, including the Tsybakov model which considerably generalizes the Massart condition by allowing the flipping probability to be arbitrarily close to $\frac{1}{2}$ for a subset of the domain. As a corollary, we employ an evolutionary algorithm by \cite{DBLP:conf/colt/KanadeVV10} to obtain the first polynomial time algorithm with arbitrarily small excess error for learning linear threshold functions over any spherically symmetric distribution in the presence of spherically symmetric Tsybakov noise. Moreover, we posit access to a stronger oracle, in which for every labeled example we additionally obtain its flipping probability. In this model, we show that every SQ learnable class admits an efficient learning algorithm with OPT + $\epsilon$ misclassification error for a broad class of noise models. This setting substantially generalizes the widely-studied problem of classification under RCN with known noise rate, and corresponds to a non-convex optimization problem even when the noise function -- i.e. the flipping probabilities of all points -- is known in advance.