 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Data-Driven Predictors with Allocation: A Decision-Focused Approach to Survival Analysis
Jun 01, 2026Machine learning predictors have become essential tools for guiding automated decision making. However, a major misalignment persists: predictive models are typically optimized in terms of standard statistical metrics in isolation from the algorithmic tasks they inform. We highlight this incongruity in the high-stakes domain of organ allocation by demonstrating that any algorithm relying on (even highly accurate) survival predictors optimized for standard metrics -- such as the Concordance index (C-index) -- can yield arbitrarily poor outcomes when used for allocation, failing to guarantee utility better than a uniform random selection. To bridge the gap between survival analysis and policy optimization, we introduce a decision-focused learning approach based on optimizing normalized discounted cumulative gain (NDCG), a mainstay metric in information retrieval. We establish the utility of NDCG in survival analysis by proving that it translates to guarantees on the performance of allocation. Empirically, we propose a bootstrapping approach to optimize the NDCG of existing survival models. Unlike prior work, we also address the challenge of right censorship when evaluating ranking. On historical heart transplant data from the US, our method dramatically boosts the NDCG of baseline models by 50-100%, which translates to tens of thousands of additional life years gained annually when deployed for transplant allocation. We anticipate that our framework will find broader applications in decision making with predictions.
Decision Making under Imperfect Recall: Algorithms and Benchmarks
Feb 16, 2026In game theory, imperfect-recall decision problems model situations in which an agent forgets information it held before. They encompass games such as the ``absentminded driver'' and team games with limited communication. In this paper, we introduce the first benchmark suite for imperfect-recall decision problems. Our benchmarks capture a variety of problem types, including ones concerning privacy in AI systems that elicit sensitive information, and AI safety via testing of agents in simulation. Across 61 problem instances generated using this suite, we evaluate the performance of different algorithms for finding first-order optimal strategies in such problems. In particular, we introduce the family of regret matching (RM) algorithms for nonlinear constrained optimization. This class of parameter-free algorithms has enjoyed tremendous success in solving large two-player zero-sum games, but, surprisingly, they were hitherto relatively unexplored beyond that setting. Our key finding is that RM algorithms consistently outperform commonly employed first-order optimizers such as projected gradient descent, often by orders of magnitude. This establishes, for the first time, the RM family as a formidable approach to large-scale constrained optimization problems.
Learning Potentials for Dynamic Matching and Application to Heart Transplantation
Feb 09, 2026Each year, thousands of patients in need of heart transplants face life-threatening wait times due to organ scarcity. While allocation policies aim to maximize population-level outcomes, current approaches often fail to account for the dynamic arrival of organs and the composition of waitlisted candidates, thereby hampering efficiency. The United States is transitioning from rigid, rule-based allocation to more flexible data-driven models. In this paper, we propose a novel framework for non-myopic policy optimization in general online matching relying on potentials, a concept originally introduced for kidney exchange. We develop scalable and accurate ways of learning potentials that are higher-dimensional and more expressive than prior approaches. Our approach is a form of self-supervised imitation learning: the potentials are trained to mimic an omniscient algorithm that has perfect foresight. We focus on the application of heart transplant allocation and demonstrate, using real historical data, that our policies significantly outperform prior approaches -- including the current US status quo policy and the proposed continuous distribution framework -- in optimizing for population-level outcomes. Our analysis and methods come at a pivotal moment in US policy, as the current heart transplant allocation system is under review. We propose a scalable and theoretically grounded path toward more effective organ allocation.
Swap Regret Minimization Through Response-Based Approachability
Feb 05, 2026We consider the problem of minimizing different notions of swap regret in online optimization. These forms of regret are tightly connected to correlated equilibrium concepts in games, and have been more recently shown to guarantee non-manipulability against strategic adversaries. The only computationally efficient algorithm for minimizing linear swap regret over a general convex set in $\mathbb{R}^d$ was developed recently by Daskalakis, Farina, Fishelson, Pipis, and Schneider (STOC '25). However, it incurs a highly suboptimal regret bound of $Ω(d^4 \sqrt{T})$ and also relies on computationally intensive calls to the ellipsoid algorithm at each iteration. In this paper, we develop a significantly simpler, computationally efficient algorithm that guarantees $O(d^{3/2} \sqrt{T})$ linear swap regret for a general convex set and $O(d \sqrt{T})$ when the set is centrally symmetric. Our approach leverages the powerful response-based approachability framework of Bernstein and Shimkin (JMLR '15) -- previously overlooked in the line of work on swap regret minimization -- combined with geometric preconditioning via the John ellipsoid. Our algorithm simultaneously minimizes profile swap regret, which was recently shown to guarantee non-manipulability. Moreover, we establish a matching information-theoretic lower bound: any learner must incur in expectation $Ω(d \sqrt{T})$ linear swap regret for large enough $T$, even when the set is centrally symmetric. This also shows that the classic algorithm of Gordon, Greenwald, and Marks (ICML '08) is existentially optimal for minimizing linear swap regret, although it is computationally inefficient. Finally, we extend our approach to minimize regret with respect to the set of swap deviations with polynomial dimension, unifying and strengthening recent results in equilibrium computation and online learning.
Near-Optimal Dynamic Matching via Coarsening with Application to Heart Transplantation
Feb 04, 2026Online matching has been a mainstay in domains such as Internet advertising and organ allocation, but practical algorithms often lack strong theoretical guarantees. We take an important step toward addressing this by developing new online matching algorithms based on a coarsening approach. Although coarsening typically implies a loss of granularity, we show that, to the contrary, aggregating offline nodes into capacitated clusters can yield near-optimal theoretical guarantees. We apply our methodology to heart transplant allocation to develop theoretically grounded policies based on structural properties of historical data. In realistic simulations, our policy closely matches the performance of the omniscient benchmark. Our work bridges the gap between data-driven heuristics and pessimistic theoretical lower bounds, and provides rigorous justification for prior clustering-based approaches in organ allocation.
Position: Machine Learning for Heart Transplant Allocation Policy Optimization Should Account for Incentives
Feb 04, 2026The allocation of scarce donor organs constitutes one of the most consequential algorithmic challenges in healthcare. While the field is rapidly transitioning from rigid, rule-based systems to machine learning and data-driven optimization, we argue that current approaches often overlook a fundamental barrier: incentives. In this position paper, we highlight that organ allocation is not merely a static optimization problem, but rather a complex game involving transplant centers, clinicians, and regulators. Focusing on US adult heart transplant allocation, we identify critical incentive misalignments across the decision-making pipeline, and present data showing that they are having adverse consequences today. Our main position is that the next generation of allocation policies should be incentive aware. We outline a research agenda for the machine learning community, calling for the integration of mechanism design, strategic classification, causal inference, and social choice to ensure robustness, efficiency, and fairness in the face of strategic behavior from the various constituent groups.
Policy Optimization for Dynamic Heart Transplant Allocation
Dec 13, 2025Heart transplantation is a viable path for patients suffering from advanced heart failure, but this lifesaving option is severely limited due to donor shortage. Although the current allocation policy was recently revised in 2018, a major concern is that it does not adequately take into account pretransplant and post-transplant mortality. In this paper, we take an important step toward addressing these deficiencies. To begin with, we use historical data from UNOS to develop a new simulator that enables us to evaluate and compare the performance of different policies. We then leverage our simulator to demonstrate that the status quo policy is considerably inferior to the myopic policy that matches incoming donors to the patient who maximizes the number of years gained by the transplant. Moreover, we develop improved policies that account for the dynamic nature of the allocation process through the use of potentials -- a measure of a patient's utility in future allocations that we introduce. We also show that batching together even a handful of donors -- which is a viable option for a certain type of donors -- further enhances performance. Our simulator also allows us to evaluate the effect of critical, and often unexplored, factors in the allocation, such as geographic proximity and the tendency to reject offers by the transplant centers.
Scale-Invariant Regret Matching and Online Learning with Optimal Convergence: Bridging Theory and Practice in Zero-Sum Games
Oct 06, 2025A considerable chasm has been looming for decades between theory and practice in zero-sum game solving through first-order methods. Although a convergence rate of $T^{-1}$ has long been established since Nemirovski's mirror-prox algorithm and Nesterov's excessive gap technique in the early 2000s, the most effective paradigm in practice is *counterfactual regret minimization*, which is based on *regret matching* and its modern variants. In particular, the state of the art across most benchmarks is *predictive* regret matching$^+$ (PRM$^+$), in conjunction with non-uniform averaging. Yet, such algorithms can exhibit slower $\Omega(T^{-1/2})$ convergence even in self-play. In this paper, we close the gap between theory and practice. We propose a new scale-invariant and parameter-free variant of PRM$^+$, which we call IREG-PRM$^+$. We show that it achieves $T^{-1/2}$ best-iterate and $T^{-1}$ (i.e., optimal) average-iterate convergence guarantees, while also being on par with PRM$^+$ on benchmark games. From a technical standpoint, we draw an analogy between IREG-PRM$^+$ and optimistic gradient descent with *adaptive* learning rate. The basic flaw of PRM$^+$ is that the ($\ell_2$-)norm of the regret vector -- which can be thought of as the inverse of the learning rate -- can decrease. By contrast, we design IREG-PRM$^+$ so as to maintain the invariance that the norm of the regret vector is nondecreasing. This enables us to derive an RVU-type bound for IREG-PRM$^+$, the first such property that does not rely on introducing additional hyperparameters to enforce smoothness. Furthermore, we find that IREG-PRM$^+$ performs on par with an adaptive version of optimistic gradient descent that we introduce whose learning rate depends on the misprediction error, demystifying the effectiveness of the regret matching family *vis-a-vis* more standard optimization techniques.
A Polynomial-Time Algorithm for Variational Inequalities under the Minty Condition
Apr 04, 2025
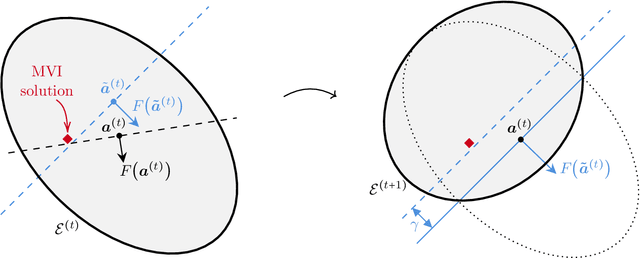


Solving (Stampacchia) variational inequalities (SVIs) is a foundational problem at the heart of optimization, with a host of critical applications ranging from engineering to economics. However, this expressivity comes at the cost of computational hardness. As a result, most research has focused on carving out specific subclasses that elude those intractability barriers. A classical property that goes back to the 1960s is the Minty condition, which postulates that the Minty VI (MVI) problem -- the weak dual of the SVI problem -- admits a solution. In this paper, we establish the first polynomial-time algorithm -- that is, with complexity growing polynomially in the dimension $d$ and $\log(1/\epsilon)$ -- for solving $\epsilon$-SVIs for Lipschitz continuous mappings under the Minty condition. Prior approaches either incurred an exponentially worse dependence on $1/\epsilon$ (and other natural parameters of the problem) or made overly restrictive assumptions -- such as strong monotonicity. To do so, we introduce a new variant of the ellipsoid algorithm wherein separating hyperplanes are obtained after taking a gradient descent step from the center of the ellipsoid. It succeeds even though the set of SVIs can be nonconvex and not fully dimensional. Moreover, when our algorithm is applied to an instance with no MVI solution and fails to identify an SVI solution, it produces a succinct certificate of MVI infeasibility. We also show that deciding whether the Minty condition holds is $\mathsf{coNP}$-complete. We provide several extensions and new applications of our main results. Specifically, we obtain the first polynomial-time algorithms for i) solving monotone VIs, ii) globally minimizing a (potentially nonsmooth) quasar-convex function, and iii) computing Nash equilibria in multi-player harmonic games.
Learning and Computation of $Φ$-Equilibria at the Frontier of Tractability
Feb 25, 2025

$\Phi$-equilibria -- and the associated notion of $\Phi$-regret -- are a powerful and flexible framework at the heart of online learning and game theory, whereby enriching the set of deviations $\Phi$ begets stronger notions of rationality. Recently, Daskalakis, Farina, Fishelson, Pipis, and Schneider (STOC '24) -- abbreviated as DFFPS -- settled the existence of efficient algorithms when $\Phi$ contains only linear maps under a general, $d$-dimensional convex constraint set $\mathcal{X}$. In this paper, we significantly extend their work by resolving the case where $\Phi$ is $k$-dimensional; degree-$\ell$ polynomials constitute a canonical such example with $k = d^{O(\ell)}$. In particular, positing only oracle access to $\mathcal{X}$, we obtain two main positive results: i) a $\text{poly}(n, d, k, \text{log}(1/\epsilon))$-time algorithm for computing $\epsilon$-approximate $\Phi$-equilibria in $n$-player multilinear games, and ii) an efficient online algorithm that incurs average $\Phi$-regret at most $\epsilon$ using $\text{poly}(d, k)/\epsilon^2$ rounds. We also show nearly matching lower bounds in the online learning setting, thereby obtaining for the first time a family of deviations that captures the learnability of $\Phi$-regret. From a technical standpoint, we extend the framework of DFFPS from linear maps to the more challenging case of maps with polynomial dimension. At the heart of our approach is a polynomial-time algorithm for computing an expected fixed point of any $\phi : \mathcal{X} \to \mathcal{X}$ based on the ellipsoid against hope (EAH) algorithm of Papadimitriou and Roughgarden (JACM '08). In particular, our algorithm for computing $\Phi$-equilibria is based on executing EAH in a nested fashion -- each step of EAH itself being implemented by invoking a separate call to EAH.